
多線程-ConcurrentHashMap(JDK1.8)
前言
HashMap非線程安全的,HashTable是線程安全的,所有涉及到多線程操作的都加上了synchronized關鍵字來鎖住整個table,這就意味著所有的線程都在競爭一把鎖,在多線程的環境下,它是安全的,但是無疑效率低下的。
ConcurrentHashMap(JDK1.7)
在JDK1.7中,ConcurrentHashMap的數據結構是由一個Segment數組和多個HashEntry組成的,如圖:
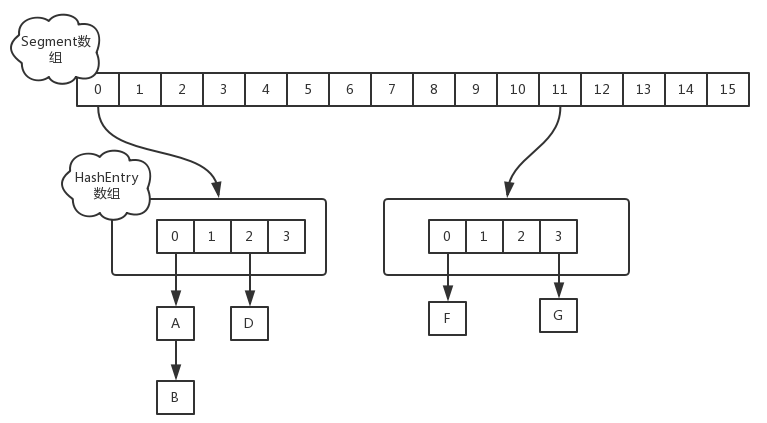
Segment數組的意義就是將一個大的table分割成多個小的table來進行加鎖,也就是鎖分離技術,而每一個Segment元素存儲的是HashEntry數組+ 鏈表。
put
對於ConcurrentHashMap的數據插入,這裏要進行兩次Hash去定位數據的存儲位置。
static class Segment<K,V> extends ReentrantLock implements Serializable {
}
從上Segment的繼承體系可以看出,Segment實現了ReentrantLock,也就帶有鎖的功能,當執行put操作時,會進行第一次key的hash來定位Segment的位置,如果該Segment還沒有初始化,即通過CAS操作進行賦值,然後進行第二次hash操作,找到相應的HashEntry的位置,這裏會利用繼承過來的鎖的特性,在將數據插入指定的HashEntry位置時(鏈表的尾端),會通過繼承ReentrantLock的tryLock()方法嘗試去獲取鎖,如果獲取成功就直接插入相應的位置,如果已經有線程獲取該Segment的鎖,那當前線程會以自旋的方式去繼續的調用tryLock()方法去獲取鎖,超過指定次數就掛起,等待喚醒。
get
ConcurrentHashMap的get操作跟HashMap類似,只是ConcurrentHashMap第一次需要經過一次hash定位到Segment的位置,然後再hash定位到指定的HashEntry,遍歷該HashEntry下的鏈表進行對比,成功就返回,不成功就返回null。
size
計算ConcurrentHashMap的元素大小是一個有趣的問題,因為他是並發操作的,就是在你計算size的時候,他還在並發的插入數據,可能會導致你計算出來的size和你實際的size有相差(在你return size的時候,插入了多個數據),要解決這個問題,JDK1.7版本用兩種方案:
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j) ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) { sum += seg.modCount; int c = seg.count; if (c < 0 || (size += c) < 0)
overflow = true;
} }
if (sum == last) break;
last = sum; } }
finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
- 第一種方案他會使用不加鎖的模式去嘗試多次計算ConcurrentHashMap的size,最多三次,比較前後兩次計算的結果,結果一致就認為當前沒有元素加入,計算的結果是準確的
- 第二種方案是如果第一種方案不符合,他就會給每個Segment加上鎖,然後計算ConcurrentHashMap的size返回
ConcurrentHashMap(JDK1.8)
JDK1.8的實現已經摒棄了Segment的概念,而是直接用Node數組+鏈表+紅黑樹的數據結構來實現,並發控制使用Synchronized和CAS來操作,整個看起來就像是優化過且線程安全的HashMap,雖然在JDK1.8中還能看到Segment的數據結構,但是已經簡化了屬性,只是為了兼容舊版本.
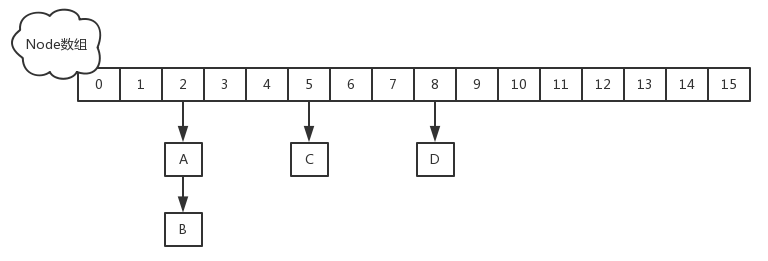
先看一些常量設計和數據結構:
// node數組最大容量:2^30=1073741824 private static final int MAXIMUM_CAPACITY = 1 << 30; // 默認初始值,必須是2的幕數 private static final int DEFAULT_CAPACITY = 16; //數組可能最大值,需要與toArray()相關方法關聯 static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; //並發級別,遺留下來的,為兼容以前的版本 private static final int DEFAULT_CONCURRENCY_LEVEL = 16; // 負載因子 private static final float LOAD_FACTOR = 0.75f; // 鏈表轉紅黑樹閥值,> 8 鏈表轉換為紅黑樹 static final int TREEIFY_THRESHOLD = 8; //樹轉鏈表閥值,小於等於6(tranfer時,lc、hc=0兩個計數器分別++記錄原bin、新binTreeNode數量,<=UNTREEIFY_THRESHOLD 則untreeify(lo)) static final int UNTREEIFY_THRESHOLD = 6; static final int MIN_TREEIFY_CAPACITY = 64; private static final int MIN_TRANSFER_STRIDE = 16; private static int RESIZE_STAMP_BITS = 16; // 2^15-1,help resize的最大線程數 private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1; // 32-16=16,sizeCtl中記錄size大小的偏移量 private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; // forwarding nodes的hash值 static final int MOVED = -1; // 樹根節點的hash值 static final int TREEBIN = -2; // ReservationNode的hash值 static final int RESERVED = -3; // 可用處理器數量 static final int NCPU = Runtime.getRuntime().availableProcessors(); //存放node的數組 transient volatile Node<K,V>[] table; /*控制標識符,用來控制table的初始化和擴容的操作,不同的值有不同的含義 *當為負數時:-1代表正在初始化,-N代表有N-1個線程正在 進行擴容 *當為0時:代表當時的table還沒有被初始化 *當為正數時:表示初始化或者下一次進行擴容的大小
*/ private transient volatile int sizeCtl;
基本屬性定義了ConcurrentHashMap的一些邊界以及操作時的一些控制。
類圖

Node是ConcurrentHashMap存儲結構的基本單元,實現了Map.Entry接口,用於存儲數據。
TreeNode繼承與Node,但是數據結構換成了二叉樹結構,它是紅黑樹的數據的存儲結構,用於紅黑樹中存儲數據,當鏈表的節點數大於8時會轉換成紅黑樹的結構,他就是通過TreeNode作為存儲結構代替Node來轉換成黑紅樹。
TreeBin從字面含義中可以理解為存儲樹形結構的容器,而樹形結構就是指TreeNode,所以TreeBin就是封裝TreeNode的容器,它提供轉換黑紅樹的一些條件和鎖的控制。
put
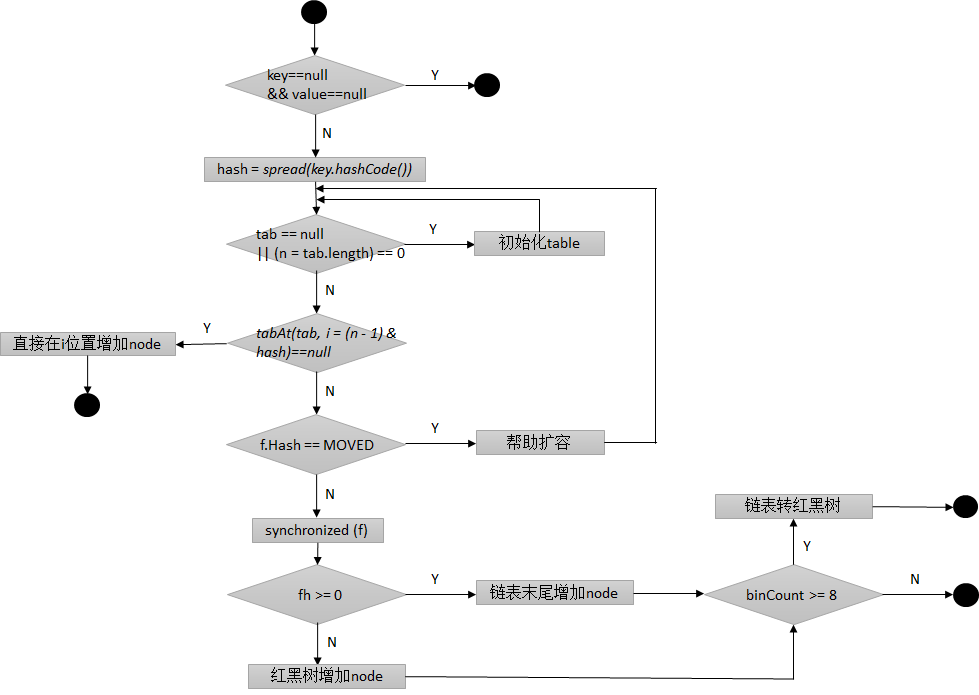
多線程-ConcurrentHashMap(JDK1.8)