
對字符編碼的理解
1.含義
關於人類文明中的語言符號與計算機所認識的0和1之間的一個對應關系表。字符-------通過翻譯----------計算機認識的數字。這個過程實際就是一個字符如何對應一個特定數字的標準,這個標準稱之為字符編碼。同一編碼規範的不同版本間具有向下兼容性。
2.發展歷史
(1)階段一:現代計算機起源於美國,最早誕生也是基於英文考慮的ASCII
ASCII:一個Bytes代表一個字符(英文字符/鍵盤上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1種變化,即可以表示256個字符
ASCII最初只用了後七位,127個數字,已經完全能夠代表鍵盤上所有的字符了(英文字符/鍵盤的所有其他字符),後來為了將拉丁文也編碼進了ASCII表,將最高位也占用了。
(2)階段二:為了滿足中文和英文,中國人定制了GBK。GBK:2Bytes代表一個中文字符,1Bytes表示一個英文字符 為了滿足其他國家,各個國家紛紛定制了自己的編碼 日本把日文編到Shift_JIS裏,韓國把韓文編到Euc-kr裏。
(3)階段三:各國有各國的標準,就會不可避免地出現沖突,結果就是,在多語言混合的文本中,顯示出來會有亂碼。如何解決這個問題呢???
說白了亂碼問題的本質就是不統一,如果我們能統一全世界,規定全世界只能使用一種文字符號,然後統一使用一種編碼,那麽亂碼問題將不復存在,
ps:就像當年秦始皇統一中國一樣,書同文車同軌,所有的麻煩事全部解決
很明顯,上述的假設是不可能成立的。很多地方或老的系統、應用軟件仍會采用各種各樣的編碼,這是歷史遺留問題。於是我們必須找出一種解決方案或者說編碼方案,需要同時滿足:
#1、能夠兼容萬國字符
#2、與全世界所有的字符編碼都有映射關系,這樣就可以轉換成任意國家的字符編碼
這就是unicode
3.涉及到字符編碼的場景:
(1)一個python文件中的內容是由一堆字符串組成的,存取均涉及到編碼問題;
(2)python中的數據類型字符串是由一串字符組成的;
4.出現亂碼的2種情況:
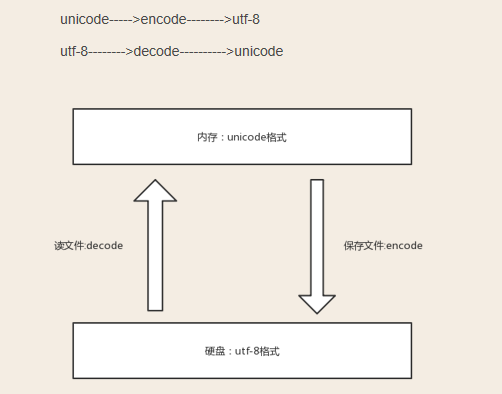
2個概念:文件從內存刷到硬盤叫做存文件:文件從硬盤讀到內存叫做讀文件
(1)存文件時就已經亂碼:存文件時,由於文件內有各個國家的文字,我們單以某一編碼格式去存,會存失敗而編輯器不會報錯,於是打開的時候就會看到亂碼
(2)讀文件時亂碼:存文件時用的是utf-8編碼,可以兼容萬國,不會亂碼,而讀文件時選擇了錯誤的解碼方式,比如gbk,則在讀階段發生亂碼,讀階段發生亂碼是可以解決的,選對正確的解碼方式就ok了。
5.保證不亂碼的方法:用什麽格式編碼的就就用什麽格式解碼,一定不會亂碼。內存中永遠是unicode碼。
6.字符編碼在文本編輯器中的應用:
7.字符編碼在python中的應用:
(1)執行python程序的三個階段:
第一階段:啟動python解釋器
第二階段:將test.py腳本從硬盤讀到內存,此時python解釋器就相當於一個文本編輯器,打開test.py文件;此時,python解釋器會讀取test.py的第一行內容,#coding:utf-8,來決定以什麽編碼格式來讀入內存,這一行就是來設定python解釋器這個軟件的編碼使用的編碼格式這個編碼。可以用sys.getdefaultencoding()查看,如果不在python文件指定頭信息#-*-coding:utf-8-*-,那就使用默認的 python2中默認使用ascii,python3中默認使用utf-8。
第三階段:讀取已經加載到內存中的代碼(unicode模式),然後執行過程中可能會開辟新的內存空間,比如x="alex"。請理解好這句話:內存的編碼使用unicode,不代表內存中全都是unicode(在程序執行之前,內存中確實都是unicode,比如從文件中讀取了一行x="egon",其中的x,等號,引號,地位都一樣,都是普通字符而已,都是以unicode的格式存放於內存中的。但是程序在執行過程中,會申請內存(與程序代碼所存在的內存是倆個空間)用來存放python的數據類型的值,而python的字符串類型又涉及到了字符的概念。比如x="egon",會被python解釋器識別為字符串,會申請內存空間來存放字符串類型的值,至於該字符串類型的值被識別成何種編碼存放,這就與python解釋器的有關了,而python2與python3的字符串類型又有所不同。python3中“egon"是以unicode碼暫存於內存,而python2中是以bytes暫存於內存中的。即python2中,str=bytes,unicode=unicode; python3中,str=unicode,bytes=bytes)。
8.python2與python3字符串類型區別
(1)python2中有2種類型:str 和 unicode。
str類型
當python解釋器執行到產生字符串的代碼時(例如x=‘上‘),會申請新的內存地址,然後將‘上‘編碼成文件開頭指定的編碼格式
要想看x在內存中的真實格式,可以將其放入列表中再打印,而不要直接打印,因為直接print()會自動轉換編碼,python解釋器這樣幫我們做的,易於初學者能看懂,見下面的細說。
#coding:gbk x=‘上‘ y=‘下‘ print([x,y]) #[‘\xc9\xcf‘, ‘\xcf\xc2‘] #\x代表16進制,此處是c9cf總共4位16進制數,一個16進制四4個比特位,4個16進制數則是16個比特位,即2個Bytes,這就證明了按照gbk編碼中文用2Bytes
print(type(x),type(y)) #(<type ‘str‘>, <type ‘str‘>)
unicode類型
當python解釋器執行到產生字符串的代碼時(例如s=u‘林‘),會申請新的內存地址,然後將‘林‘以unicode的格式存放到新的內存空間中,所以s只能encode,不能decode
#coding:gbk x=u‘上‘ #等同於 x=‘上‘.decode(‘gbk‘) y=u‘下‘ #等同於 y=‘下‘.decode(‘gbk‘) print([x,y]) #[u‘\u4e0a‘, u‘\u4e0b‘] 註意這一行
print(type(x),type(y)) #(<type ‘unicode‘>, <type ‘unicode‘>)
打印到終端(細說)
對於print需要特別說明的是:
當程序執行時,比如
x=‘上‘ #gbk下,字符串存放為\xc9\xcf
print(x) #這一步是將x指向的那塊新的內存空間(非代碼所在的內存空間)中的內存,打印到終端,按理說應該是存的什麽就打印什麽,但打印\xc9\xcf,對一些不熟知python編碼的程序員,立馬就懵逼了,所以龜叔自作主張,在print(x)時,使用終端的編碼格式,將內存中的\xc9\xcf轉成字符顯示,此時就需要終端編碼必須為gbk,否則無法正常顯示原內容。
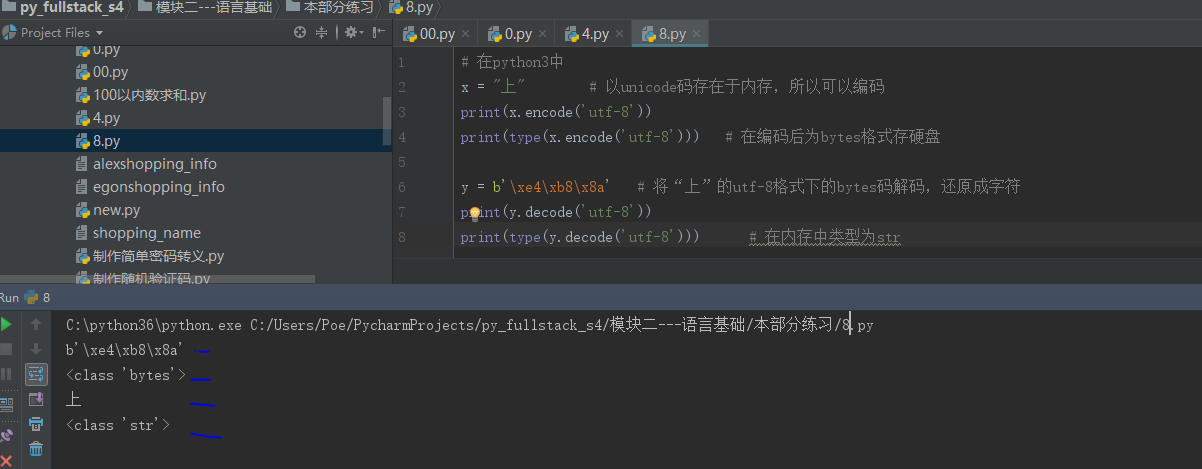
(2)在python3 中也有兩種字符串類型str和bytes
str是unicode
#coding:gbk x=‘上‘ #當程序執行時,無需加u,‘上‘也會被以unicode形式保存新的內存空間中, print(type(x)) #<class ‘str‘> #x可以直接encode成任意編碼格式 print(x.encode(‘gbk‘)) #b‘\xc9\xcf‘ print(type(x.encode(‘gbk‘))) #<class ‘bytes‘>
很重要的一點是:看到python3中x.encode(‘gbk‘) 的結果\xc9\xcf正是python2中的str類型的值,而在python3是bytes類型,在python2中則是str類型
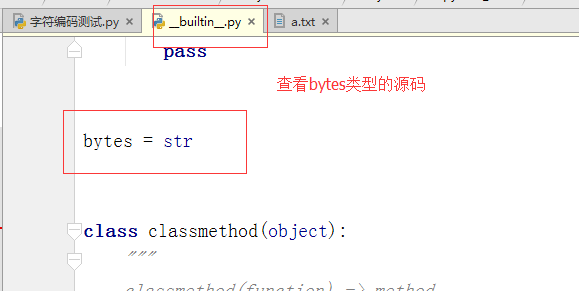
於是我有一個大膽的推測:python2中的str類型就是python3的bytes類型,於是我查看python2的str()源碼,發現
對字符編碼的理解