
JDK學習---深入理解java中的String
本文參考資料:
1、《深入理解jvm虛擬機》
2、《大話數據結構》、《大化設計模式》
3、http://www.cnblogs.com/ITtangtang/p/3976820.html#3441029
4、http://www.cnblogs.com/xiaoxi/p/6036701.html
5、https://www.zhihu.com/question/20618891
6、http://blog.csdn.net/zhangjg_blog/article/details/18319521
今天無錫下著小雨,冷颼颼的,不適合出去玩。此刻,我喝著咖啡,心想著也沒事,那就索性整理一下基礎知識,方便以後自己的理解與記憶,畢竟年紀也不小了,記憶力與精力都大不如前了,不服老不行呀。
本篇我先挑了String類型進行分析,一開始是從虛擬機、源碼、案例的角度去分析和整理文檔的。後來當我讀完HashMap的層源碼的時候,我發現HashMap的底層源碼居然是一個鏈表,而且還是單向鏈表,此刻再回頭看了看String,好像也涉及到了數據結構的線性表順序存儲結構。思慮再三,還是把數據結構的相關知識也添加了進來,因此才有了第四節的《數據結構》。
一、認識JVM基本知識
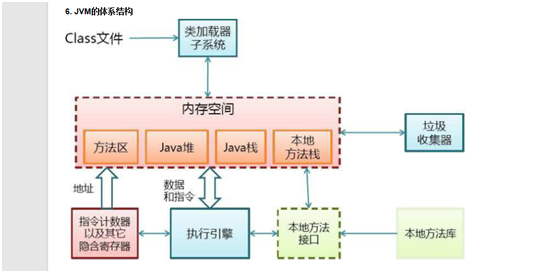
這是一張JVM基本結構圖,本文主要是解讀String類型,涉及虛擬機知識有限。因此,將主要針對方法區、java堆、java棧進行分析
JVM棧
JVM棧是線程私有的,每個線程創建的同時都會創建JVM棧,JVM棧中存放的為當前線程中局部基本類型的變量(java中定義的八種基本類型:boolean、char、byte、short、int、long、float、double)、部分的返回結果以及Stack Frame,非基本類型的對象在JVM棧上僅存放一個指向堆上的地址。
堆內存用於存放由new創建的對象和數組
方法區域(Method Area)
(1)在Sun JDK中這塊區域對應的為PermanetGeneration,又稱為持久代。
(2)方法區域存放了所加載的類的信息(名稱、修飾符等)、類中的靜態變量、類中定義為final類型的常量、類中的Field信息、類中的方法信息,當開發人員在程序中通過Class對象中的getName、 isInterface等方法來獲取信息時,這些數據都來源於方法區域,同時方法區域也是全局共享的,在一定的條件下它也會被GC,當方法區域需要使用的內存超過其允許的大小時,會拋出OutOfMemory的錯誤信息。
二、運行時常量池(Runtime Constant Pool)
存放的為類中的固定的常量信息、方法和Field的引用信息等,其空間從方法區域中分配。
Java的堆是一個運行時數據區,類的(對象從中分配空間。這些對象通過new、newarray、 anewarray和multianewarray等指令建立,它們不需要程序代碼來顯式的釋放。堆是由垃圾回收來負責的,堆的優勢是可以動態地分配內存大小,生存期也不必事先告訴編譯器,因為它是在運行時動態分配內存的,Java的垃圾收集器會自動收走這些不再使用的數據。但缺點是,由於要在運行時動態分配內存,存取速度較慢。
棧的優勢是,存取速度比堆要快,僅次於寄存器,棧數據可以共享。但缺點是,存在棧中的數據大小與生存期必須是確定的,缺乏靈活性。棧中主要存放一些基本類型的變量數據(int, short, long, byte, float, double, boolean, char)和對象句柄(引用)。
虛擬機必須為每個被裝載的類型維護一個常量池。常量池就是該類型所用到常量的一個有序集合,包括直接常量(string,integer和 floating point常量)和對其他類型,字段和方法的符號引用。
三、字符串常量池
我們知道字符串的分配和其他對象分配一樣,是需要消耗高昂的時間和空間的,而且字符串我們使用的非常多。JVM為了提高性能和減少內存的開銷,在實例化字符串的時候進行了一些優化:使用字符串常量池。每當我們創建字符串常量時,JVM會首先檢查字符串常量池,如果該字符串已經存在常量池中,那麽就直接返回常量池中的實例引用。如果字符串不存在常量池中,就會實例化該字符串並且將其放到常量池中。由於String字符串的不可變性我們可以十分肯定常量池中一定不存在兩個相同的字符串(這點後面會重點講解String不可變)。
對於String常量,它的值是在常量池中的。而JVM中的常量池在內存當中是以表的形式存在的, 對於String類型,有一張固定長度的CONSTANT_String_info表用來存儲文字字符串值,註意:該表只存儲文字字符串值,不存儲符號引用。說到這裏,對常量池中的字符串值的存儲位置應該有一個比較明了的理解了。在程序執行的時候,常量池會儲存在Method Area,而不是堆中。常量池中保存著很多String對象; 並且可以被共享使用,因此它提高了效率
四、數據結構
為什麽要介紹數據結構的相關知識,因為在我把String底層實現讀完之後,其實String的數據存儲是放在一個char[]類型的數組中的,雖然這個數組被定義為private final類型,每次添加元素和替換等其他操作都是直接生成新的字符數組進行操作,但是這完全不影響我們來介紹數據結構知識,尤其是線性表的順序存儲結構相關知識。
數據結構:是相互之間存在一種或多種特定關系的數據元素的集合。 【DP】
按照視點的不同,我們把數據結構分為邏輯結構與物理結構。
邏輯結構:是指數據對象中數據元素之間的相互關系。它分為集合結構、線性結構、樹形結構和圖形結構。
物理結構: 是指數據的邏輯結構在計算機中的存儲形式。它分為順序存儲結構和鏈式存儲結構
下面來分別認識一下邏輯結構的各個結構圖:
集合結構:
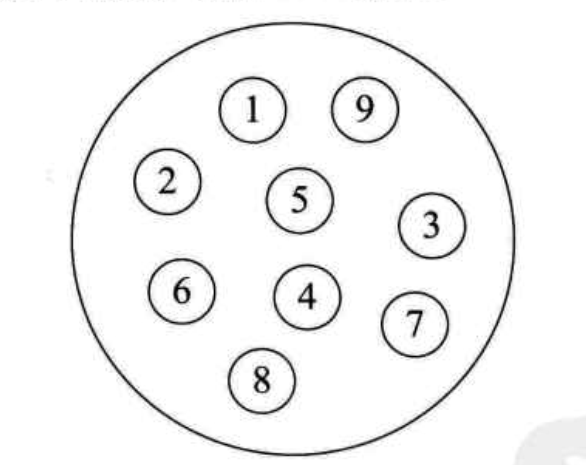
線性結構:
樹形結構
圖形結構
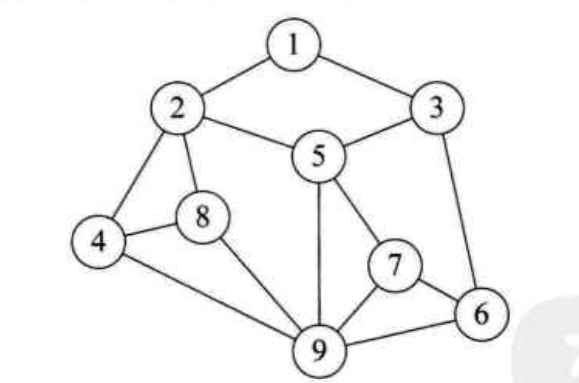
接下來介紹一下物理結構我兩種存儲結構:順序存儲結構、鏈式存儲結構。
順序存儲結構

鏈式存儲結構
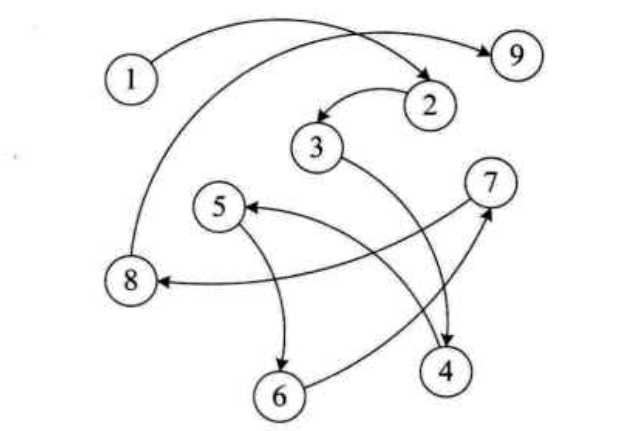
我以前出去找工作面試的時候,經常會有人問我ArrayList和LinkedList的區別以及插入和查找的性能,其實這就是想問數據結構的順序存儲結構和鏈式存儲結構知識。後來我當了面試官,遇到有兩三年工作經驗的小夥伴,我喜歡問HashMap的key為什麽不能重復、HashSet為什麽元素不能重復、以及ArrayList和LinkedList區別等等。其實,即使不知道這些知識,也不會嚴重影響正常的編碼,但是卻能反應出一個程序員是否有愛動腦的習慣,是否有好奇心或者主動性去看點東西習慣,這個很重要。
有了以上的數據結構做鋪墊,那麽我們接下來會重點介紹一下線性表的順序存儲結構。因為String類型底層實現是字符數組,這是典型的線性表的順序存儲結構。
線性表:零個或多個數據元素的有序集合 【DP】
線性表強調的是有序,那麽接下來看看常見的線性表:
星座列表:

班級點名冊:
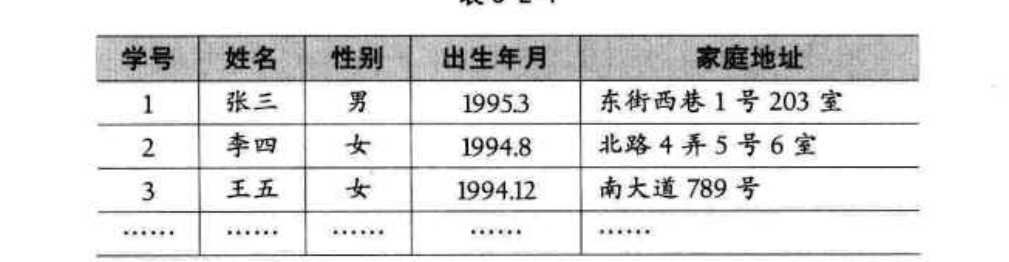
線性表的順序存儲結構:指的是用一段地址連續的去存儲單元依次存儲線性表的數據元素。【DP】
舉個例子,本來我們買春運火車票,大家都好好的排隊,這時候來了一個美女,對著隊伍中的第三位的你說:“大哥,求你幫幫忙,我家母親有病,我著急回去一趟,隊伍這麽長,我能否插個隊排在你的前面?” ,你心一軟,就同意了。這時,你必須往後退一步,否則她沒法插到隊伍裏面來。這個影響很大,後面的人像蠕蟲一樣,全部都得往後退一步。其實這個例子很好的說明了線性表的順序存儲結構。
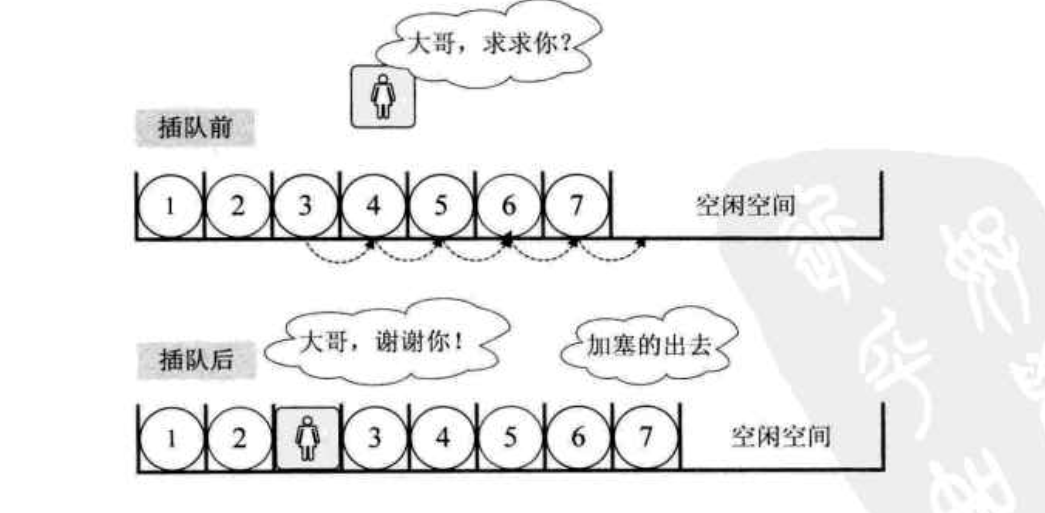
線性表順序存儲結構總結:
優點:
1、無須為表中元素之間的邏輯關系而增加額外的存儲空間(這一點你學完鏈式存儲結構就明白了,因為鏈表每個元素除了值域,還要保存一個指針域)。
2、其次是可以快速的讀取表中任意一個位置的元素(因為元素相鄰存儲在同一段內存中,查找速度快)。
缺點:1、首先是插入和刪除需要移動大量的數據,上面插隊的例子就是很好的說明;
2、當線性表長度變化較大時,難以確定存儲空間的容量(典型的就是初始化數組時要有長度)
3、造成存儲空間的“碎片”
註意:如果你覺得用String來說明線性表的順序存儲結構有點勉強的話,那你可以拿ArrayList的底層實現來說服自己,原理都是一樣的。
五、 String各種奇葩案例分析:
例子1:
[java] view plain copy- /**
- * 采用字面值的方式賦值
- */
- public void test1(){
- String str1="aaa";
- String str2="aaa";
- System.out.println("===========test1============");
- System.out.println(str1==str2);//true 可以看出str1跟str2是指向同一個對象
- }
執行上述代碼,結果為:true。
分析:當執行String str1="aaa"時,JVM首先會去字符串池中查找是否存在"aaa"這個對象,如果不存在,則在字符串池中創建"aaa"這個對象,然後將池中"aaa"這個對象的引用地址返回給字符串常量str1,這樣str1會指向池中"aaa"這個字符串對象;如果存在,則不創建任何對象,直接將池中"aaa"這個對象的地址返回,賦給字符串常量。當創建字符串對象str2時,字符串池中已經存在"aaa"這個對象,直接把對象"aaa"的引用地址返回給str2,這樣str2指向了池中"aaa"這個對象,也就是說str1和str2指向了同一個對象,因此語句System.out.println(str1 == str2)輸出:true。
例子2:
[java] view plain copy- /**
- * 采用new關鍵字新建一個字符串對象
- */
- public void test2(){
- String str3=new String("aaa");
- String str4=new String("aaa");
- System.out.println("===========test2============");
- System.out.println(str3==str4);//false 可以看出用new的方式是生成不同的對象
- }
執行上述代碼,結果為:false。
分析: 采用new關鍵字新建一個字符串對象時,JVM首先在字符串池中查找有沒有"aaa"這個字符串對象,如果有,則不在池中再去創建"aaa"這個對象了,直接在堆中創建一個"aaa"字符串對象,然後將堆中的這個"aaa"對象的地址返回賦給引用str3,這樣,str3就指向了堆中創建的這個"aaa"字符串對象;如果沒有,則首先在字符串池中創建一個"aaa"字符串對象,然後再在堆中創建一個"aaa"字符串對象,然後將堆中這個"aaa"字符串對象的地址返回賦給str3引用,這樣,str3指向了堆中創建的這個"aaa"字符串對象。當執行String str4=new String("aaa")時, 因為采用new關鍵字創建對象時,每次new出來的都是一個新的對象,也即是說引用str3和str4指向的是兩個不同的對象,因此語句System.out.println(str3 == str4)輸出:false。
例子3:
[java] view plain copy- /**
- * 編譯期確定
- */
- public void test3(){
- String s0="helloworld";
- String s1="helloworld";
- String s2="hello"+"world";
- System.out.println("===========test3============");
- System.out.println(s0==s1); //true 可以看出s0跟s1是指向同一個對象
- System.out.println(s0==s2); //true 可以看出s0跟s2是指向同一個對象
- }
執行上述代碼,結果為:true、true。
分析:因為例子中的s0和s1中的"helloworld”都是字符串常量,它們在編譯期就被確定了,所以s0==s1為true;而"hello”和"world”也都是字符串常量,當一個字符串由多個字符串常量連接而成時,它自己肯定也是字符串常量,所以s2也同樣在編譯期就被解析為一個字符串常量,所以s2也是常量池中"helloworld”的一個引用。所以我們得出s0==s1==s2。
例子4:
[java] view plain copy- /**
- * 編譯期無法確定
- */
- public void test4(){
- String s0="helloworld";
- String s1=new String("helloworld");
- String s2="hello" + new String("world");
- System.out.println("===========test4============");
- System.out.println( s0==s1 ); //false
- System.out.println( s0==s2 ); //false
- System.out.println( s1==s2 ); //false
- }
執行上述代碼,結果為:false、false、false。
分析:用new String() 創建的字符串不是常量,不能在編譯期就確定,所以new String() 創建的字符串不放入常量池中,它們有自己的地址空間。
s0還是常量池中"helloworld”的引用,s1因為無法在編譯期確定,所以是運行時創建的新對象"helloworld”的引用,s2因為有後半部分new String(”world”)所以也無法在編譯期確定,所以也是一個新創建對象"helloworld”的引用。
例子5:
[java] view plain copy- /**
- * 繼續-編譯期無法確定
- */
- public void test5(){
- String str1="abc";
- String str2="def";
- String str3=str1+str2;
- System.out.println("===========test5============");
- System.out.println(str3=="abcdef"); //false
- }
執行上述代碼,結果為:false。
分析:因為str3指向堆中的"abcdef"對象,而"abcdef"是字符串池中的對象,所以結果為false。JVM對String str="abc"對象放在常量池中是在編譯時做的,而String str3=str1+str2是在運行時刻才能知道的。new對象也是在運行時才做的。而這段代碼總共創建了5個對象,字符串池中兩個、堆中三個。+運算符會在堆中建立來兩個String對象,這兩個對象的值分別是"abc"和"def",也就是說從字符串池中復制這兩個值,然後在堆中創建兩個對象,然後再建立對象str3,然後將"abcdef"的堆地址賦給str3。
步驟:
1)棧中開辟一塊中間存放引用str1,str1指向池中String常量"abc"。
2)棧中開辟一塊中間存放引用str2,str2指向池中String常量"def"。
3)棧中開辟一塊中間存放引用str3。
4)str1 + str2通過StringBuilder的最後一步toString()方法還原一個新的String對象"abcdef",因此堆中開辟一塊空間存放此對象。
5)引用str3指向堆中(str1 + str2)所還原的新String對象。
6)str3指向的對象在堆中,而常量"abcdef"在池中,輸出為false。
例子6:
[java] view plain copy- /**
- * 編譯期優化
- */
- public void test6(){
- String s0 = "a1";
- String s1 = "a" + 1;
- System.out.println("===========test6============");
- System.out.println((s0 == s1)); //result = true
- String s2 = "atrue";
- String s3= "a" + "true";
- System.out.println((s2 == s3)); //result = true
- String s4 = "a3.4";
- String s5 = "a" + 3.4;
- System.out.println((s4 == s5)); //result = true
- }
執行上述代碼,結果為:true、true、true。
分析:在程序編譯期,JVM就將常量字符串的"+"連接優化為連接後的值,拿"a" + 1來說,經編譯器優化後在class中就已經是a1。在編譯期其字符串常量的值就確定下來,故上面程序最終的結果都為true。
例子7:
[java] view plain copy- /**
- * 編譯期無法確定
- */
- public void test7(){
- String s0 = "ab";
- String s1 = "b";
- String s2 = "a" + s1;
- System.out.println("===========test7============");
- System.out.println((s0 == s2)); //result = false
- }
執行上述代碼,結果為:false。
分析:JVM對於字符串引用,由於在字符串的"+"連接中,有字符串引用存在,而引用的值在程序編譯期是無法確定的,即"a" + s1無法被編譯器優化,只有在程序運行期來動態分配並將連接後的新地址賦給s2。所以上面程序的結果也就為false。
例子8:
[java] view plain copy- /**
- * 比較字符串常量的“+”和字符串引用的“+”的區別
- */
- public void test8(){
- String test="javalanguagespecification";
- String str="java";
- String str1="language";
- String str2="specification";
- System.out.println("===========test8============");
- System.out.println(test == "java" + "language" + "specification");
- System.out.println(test == str + str1 + str2);
- }
執行上述代碼,結果為:true、false。
分析:為什麽出現上面的結果呢?這是因為,字符串字面量拼接操作是在Java編譯器編譯期間就執行了,也就是說編譯器編譯時,直接把"java"、"language"和"specification"這三個字面量進行"+"操作得到一個"javalanguagespecification" 常量,並且直接將這個常量放入字符串池中,這樣做實際上是一種優化,將3個字面量合成一個,避免了創建多余的字符串對象。而字符串引用的"+"運算是在Java運行期間執行的,即str + str2 + str3在程序執行期間才會進行計算,它會在堆內存中重新創建一個拼接後的字符串對象。總結來說就是:字面量"+"拼接是在編譯期間進行的,拼接後的字符串存放在字符串池中;而字符串引用的"+"拼接運算實在運行時進行的,新創建的字符串存放在堆中。
對於直接相加字符串,效率很高,因為在編譯器便確定了它的值,也就是說形如"I"+"love"+"java"; 的字符串相加,在編譯期間便被優化成了"Ilovejava"。對於間接相加(即包含字符串引用),形如s1+s2+s3; 效率要比直接相加低,因為在編譯器不會對引用變量進行優化。
例子9:
[java] view plain copy- /**
- * 編譯期確定
- */
- public void test9(){
- String s0 = "ab";
- final String s1 = "b";
- String s2 = "a" + s1;
- System.out.println("===========test9============");
- System.out.println((s0 == s2)); //result = true
- }
執行上述代碼,結果為:true。
分析:和例子7中唯一不同的是s1字符串加了final修飾,對於final修飾的變量,它在編譯時被解析為常量值的一個本地拷貝存儲到自己的常量池中或嵌入到它的字節碼流中。所以此時的"a" + s1和"a" + "b"效果是一樣的。故上面程序的結果為true。
例子10:
[java] view plain copy- /**
- * 編譯期無法確定
- */
- public void test10(){
- String s0 = "ab";
- final String s1 = getS1();
- String s2 = "a" + s1;
- System.out.println("===========test10============");
- System.out.println((s0 == s2)); //result = false
- }
- private static String getS1() {
- return "b";
- }
執行上述代碼,結果為:false。
分析:這裏面雖然將s1用final修飾了,但是由於其賦值是通過方法調用返回的,那麽它的值只能在運行期間確定,因此s0和s2指向的不是同一個對象,故上面程序的結果為false。
六、理解 String 類型值的不可變
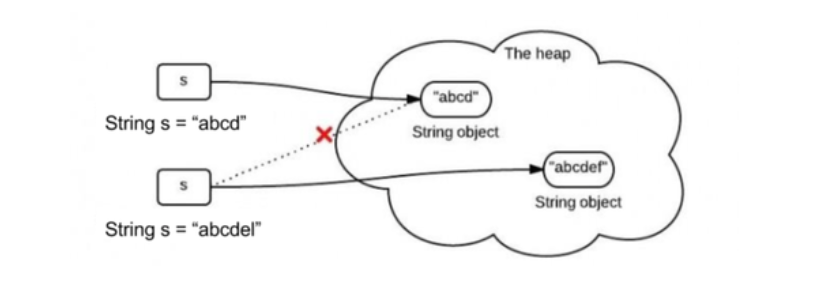
1、String的不可變實現如下圖,給一個已有字符串"abcd"第二次賦值成"abcedl",不是在原內存地址上修改數據,而是重新指向一個新對象,新地址。
2. String為什麽不可變?
[java] view plain copy- public final class String
- implements java.io.Serializable, Comparable<String>, CharSequence {
- /** The value is used for character storage. */
- private final char value[];
- /** Cache the hash code for the string */
- private int hash; // Default to 0
- /** use serialVersionUID from JDK 1.0.2 for interoperability */
- private static final long serialVersionUID = -6849794470754667710L;
首先類String是final修飾的,這就說明String不可繼續;而String儲存在字符數組value中,value也是final,這就說明value創建以後地址(註意,是地址)也是不可變的;還有一個也比較重要,那就是private修飾的value,並且value沒有提供set、get方法,這就保證外部無法直接去操作value數組,這一點也非常重要。
除此以外,String內部的各個邏輯方法都沒有對value數組進行直接的修改,而是拷貝到新的字符寶坻全屋定制數組中,這一點是保證String不可變的最重要的因此。因為value只是一個指向堆內存的指針,value不可變,但是value所指向的堆內存中的對象的內容是可以變的,如果不是String內部一系列底層實現,僅僅依靠private和final是根本沒有辦法保證String不可變的。
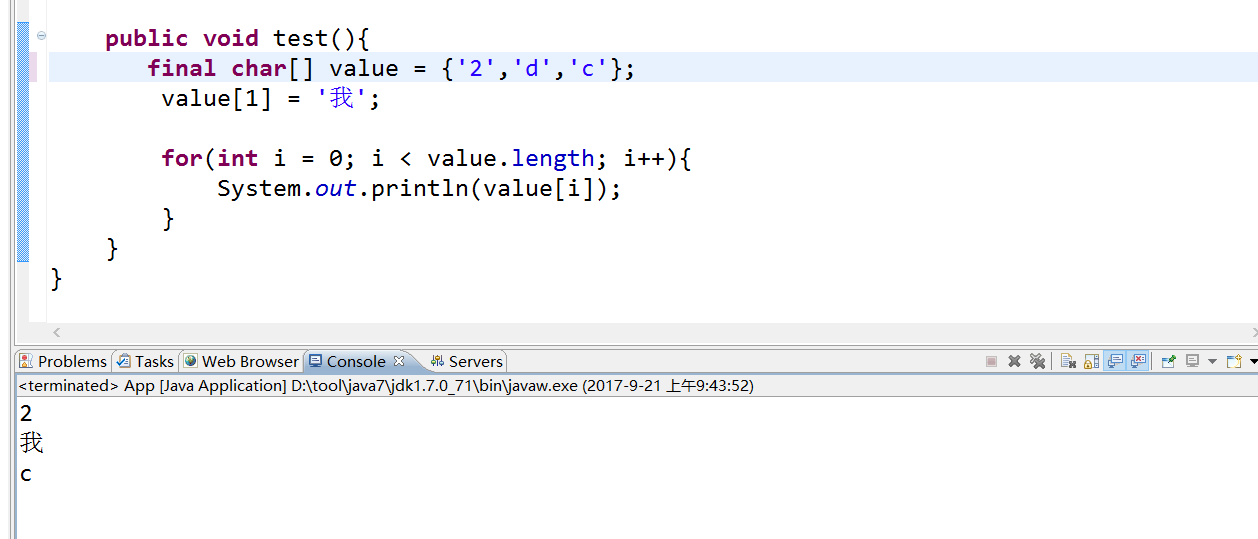
下面的案例可以說明一切:
[java] view plain copy- public void test(){
- final char[] value = {‘2‘,‘d‘,‘c‘};
- value[1] = ‘我‘;
- for(int i = 0; i < value.length; i++){
- System.out.println(value[i]);
- }
- }
運行結果:
七、底層源碼分析
length()方法:其實就是直接返回value字符數組的長度而已
[java] view plain copy- public int length() {
- return value.length;
- }
- trim()方法:看看邏輯吧,其實就是對字符數組首、尾進行無限循環判斷是否為空格字符,直到不是空格字符才跳出循環
- public String trim() {
- int len = value.length;
- int st = 0;
- char[] val = value; /* avoid getfield opcode */
- while ((st < len) && (val[st] <= ‘ ‘)) {
- st++;
- }
- while ((st < len) && (val[len - 1] <= ‘ ‘)) {
- len--;
- }
- return ((st > 0) || (len < value.length)) ? substring(st, len) : this;
- }
concat()方法:就是拷貝到新的char[]數組進行存儲,而value才是String的存儲元素,因此直接new String進行賦值。(因為value是 final的,不可以直接將value指向buf[]所指向的對象;而value長度也不可以變化,因此只能重新new String對value進行重新初始化)
[java] view plain copy- public String concat(String str) {
- int otherLen = str.length();
- if (otherLen == 0) {
- return this;
- }
- int len = value.length;
- char buf[] = Arrays.copyOf(value, len + otherLen);
- str.getChars(buf, len);
- return new String(buf, true);
- }
- public static char[] copyOf(char[] original, int newLength) {
- char[] copy = new char[newLength];
- System.arraycopy(original, 0, copy, 0,
- Math.min(original.length, newLength));
- return copy;
- }
- void getChars(char dst[], int dstBegin) {
- System.arraycopy(value, 0, dst, dstBegin, value.length);
- }
indexOf(String str)方法:看看代碼,還用解釋嗎?
[java] view plain copy- public int indexOf(String str) {
- return indexOf(str, 0);
- }
- public int indexOf(String str, int fromIndex) {
- return indexOf(value, 0, value.length,
- str.value, 0, str.value.length, fromIndex);
- }
- static int indexOf(char[] source, int sourceOffset, int sourceCount,
- char[] target, int targetOffset, int targetCount,
- int fromIndex) {
- if (fromIndex >= sourceCount) {
- return (targetCount == 0 ? sourceCount : -1);
- }
- if (fromIndex < 0) {
- fromIndex = 0;
- }
- if (targetCount == 0) {
- return fromIndex;
- }
- char first = target[targetOffset];
- int max = sourceOffset + (sourceCount - targetCount);
- for (int i = sourceOffset + fromIndex; i <= max; i++) {
- /* Look for first character. */
- if (source[i] != first) {
- while (++i <= max && source[i] != first);
- }
- /* Found first character, now look at the rest of v2 */
- if (i <= max) {
- int j = i + 1;
- int end = j + targetCount - 1;
- for (int k = targetOffset + 1; j < end && source[j]
- == target[k]; j++, k++);
- if (j == end) {
- /* Found whole string. */
- return i - sourceOffset;
- }
- }
- }
- return -1;
- }
substring(int ,int)方法:
[java] view plain copy- public String substring(int beginIndex, int endIndex) {
- if (beginIndex < 0) {
- throw new StringIndexOutOfBoundsException(beginIndex);
- }
- if (endIndex > value.length) {
- throw new StringIndexOutOfBoundsException(endIndex);
- }
- int subLen = endIndex - beginIndex;
- if (subLen < 0) {
- throw new StringIndexOutOfBoundsException(subLen);
- }
- return ((beginIndex == 0) && (endIndex == value.length)) ? this
- : new String(value, beginIndex, subLen);
- }
看了這麽多的String底層代碼實現,有沒有看到那個方法是對value數組進行重新初始化或者修改value數組元素的?沒有,都是拷貝到新的char[]數組 或者 直接new 新的String對象吧,這樣印證了上一張《理解 String 類型值的不可變》分析結論
八、對String各個方法進行模擬
[java] view plain copy- package foo;
- import java.util.Arrays;
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class StringDemo
- {
- public static void main(String[] args)
- {
- StringStr s = new StringStr();
- String str1 = "hello,大家好,我是C";
- String str2 = "nice to see you!";
- String str21 = "nice to see you!";
- //模擬concat方法
- String str3 = s.concat(str1, str2);
- System.out.println("模擬concat方法 : " + str3);
- //模擬concat方法
- String str4 = s.concat(s.trim(str1), str2);
- System.out.println("模擬trim方法 : " + str4);
- //模擬substring
- String str5 = s.substring(0, 10, str1);
- System.out.println("模擬trim方法 : " + str5);
- //模擬equals
- boolean b1 = s.equals(str1, str2);
- boolean b2 = s.equals(str2,str21);
- System.out.println("模擬equals方法 : b1:" + b1 + " b2:" + b2);
- //模擬replace
- String str6 = s.replace("我是C", " java", str1);
- System.out.println("模擬replace方法 : " + str6);
- //模擬length
- int length = s.length(str6);
- System.out.println("模擬length方法 : " + length);
- }
- }
- class StringStr
- {
- public String concat(String str1, String str2)
- {
- char[] value1 = this.getChars(str1);
- int len = value1.length;
- char[] value2 = this.getChars(str2);
- int otherLen = value2.length;
- int newLength = len + otherLen;
- char[] buf = new char[newLength];
- System.arraycopy(value1, 0, buf, 0, len);
- System.arraycopy(value2, 0, buf, len, otherLen);
- return new String(buf);
- }
- public String trim(String str)
- {
- char[] value = this.getChars(str);
- int len = value.length;
- int st = 0;
- char[] val = value;
- while ((st < len) && (val[st] <= ‘ ‘)) {
- st++;
- }
- while ((st < len) && (val[len - 1] <= ‘ ‘)) {
- len--;
- }
- return ((st > 0) || (len < value.length)) ? this.substring(st, len, str) : str;
- }
- public String substring(int beginIndex, int endIndex, String str)
- {
- char[] value = this.getChars(str);
- if (beginIndex < 0) {
- throw new StringIndexOutOfBoundsException(beginIndex);
- }
- if (endIndex > value.length) {
- throw new StringIndexOutOfBoundsException(endIndex);
- }
- int subLen = endIndex - beginIndex;
- if (subLen < 0) {
- throw new StringIndexOutOfBoundsException(subLen);
- }
- return (((beginIndex == 0) && (endIndex == value.length)) ? str: new String(value, beginIndex, subLen));
- }
- public String replace(CharSequence target, CharSequence replacement, CharSequence str) {
- return Pattern.compile(target.toString(), Pattern.LITERAL).matcher(
- str).replaceAll(Matcher.quoteReplacement(replacement.toString()));
- }
- public boolean equals(Object object, Object anObject)
- {
- if (object == anObject) {
- return true;
- }
- if (anObject instanceof String && object instanceof String)
- {
- String anotherString = (String) anObject;
- int len1 = this.getChars(anotherString).length;
- String objectString = (String) objectString;
- int len2 = this.getChars(objectString).length;
- if (len1 == len2) {
- char v1[] = this.getChars(anotherString);
- char v2[] = this.getChars(objectString);
- int i = 0;
- while (len1-- != 0) {
- if (v1[i] != v2[i])
- return false;
- i++;
- }
- return true;
- }
- }
- return false;
- }
- public int length(String str) {
- return this.getChars(str).length;
- }
- public char[] getChars(String str){
- return str.toCharArray();
- }
- }
運行看看吧,看看這些自定義的方法是不是和String的這些方法功能一致?
JDK學習---深入理解java中的String