
hbase(一)region
前言
文章不含源碼,只是一些官方資料的整理和個人理解
架構總覽
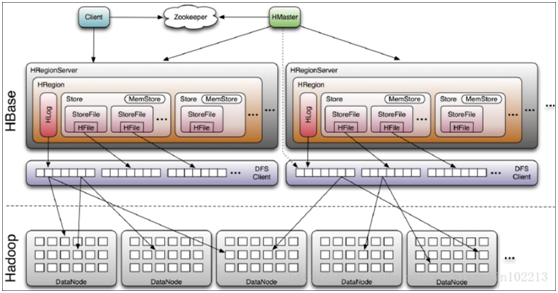
這張圖在大街小巷裏都能看到,感覺是hbase架構中最詳細最清晰的一張,稍微再補充幾點。
1) Hlog是低版本hbase術語,現在稱為WALs。
2) 1個region包含了多個store,1個store包含了1個colum family,這樣就比較好理解
3) 1個store包含了多個storefile,1個sotrefile就是1個hfile文件
這在HDFS路徑也能體現,大概長這樣
table/region/column family/hfile
region
region就是一些連續的hfile集合,也就是說連續的hfile被存儲在一個region目錄下。
我們知道,hbase索引一個數據其實是通過遍歷的方式,當然是經過優化的遍歷,而region就起到了一個很大的作用。想象一下,如果你要在一堆文件中找到你要的內容,怎麽樣的文件結構才是更快。
·有序
假如你要找的文件有關鍵字a,那麽如果所有文件是按關鍵字(hbase的rowkey)排序的,那麽a就有跡可循,Hbase采用了lexicographic order(這個單詞有點不想單詞..)也就是字典排序(ASCII碼),對每個rowkey從高位到地位排序。
·分塊
Rowkey已經是排序的,但還是要遍歷啊,萬一有個rowkey是z開頭的,不是要哭死。Hfile就出現了,一個hfile裏有一段連續的rowkey,並且記錄了所有rowkey的長度和整個hfile的rowkey是起始和終止。這樣就方便了很多,遍歷的時候只要看一個文件夾是否包含了該rowkey,而不用一個一個對比。(先忽略column family機制,bloom filter機制)
·進一步分塊
但是hfile還是很多啊,要是把hfile容量擴大也不利用讀。
最容易想到的就是把多個hfile統一管理,再做封裝,這裏就引申出了region。一些連續的hfile被一個region管理,region記錄了rowkey的起始和終止等信息。這樣遍歷起來又快了很多。
region split
上面說的解決了遍歷的性能問題,但是region也會變大,就像hfile會變大一樣。這時候region split就出現了。
當region被認為需要split的時候(max size超過閾值),一系列操作就出現了。
1) region是否需要分割是否regionserver決定的,當需要的時候,通過zookeeper和master溝通一下
2) regionserver關閉該region,並且把memstore的相關數據flush到hfile。這時候有client來請求,則會拋出NotServingRegionException異常
3) 準備子region的相關環境(路徑啊,文件夾啊什麽的,都是臨時的),創建兩個文件來指向父region(也就是待split的region)
4) 創建兩個真正的子region(文件夾),並把那兩個文件移過去
5) regionserver向hbase:meta表發起Put請求,把待分割的region設置為offline,並且增加子region的信息。在這過程中,客戶端並不能真正看到子region(還不是獨立的region),只是能知道有個父region在split。當put請求成功後,父region才會正真的split。(如果put請求失敗了,那麽由master分配新的regionserver來重新region split,在此之前會把上一次split失敗的相關臟數據清除)
6) 打開子region,接收寫操作。為之後無縫接入服務做準備
7) regionserver再向hbase:meta表添加相關信息。然後客戶端再請求就能搜索到子region。當然由於region是新建的,所以之前的緩存都不可用。
8) regionserver通過zookeeper和master交互,讓master知道有新region split好了。Master可以決定新region由哪個regionserver管理
9) 最後就是善後工作,由於新region實際上沒有父region的數據,只有一些引用來指向父region。所以在子region compaction的時候,會重寫這些數據。另外hbase的master還有一個GC task(不是jvm的GC),來定期輪詢,查看是否還有引用父region,當沒有的時候就刪除父region
總結
整個流程雖然看上去很復雜,其實效率很高,region split的過程中是不可用的,但是這時間很短,因為不涉及大量的io,只有引用和交互。
master和regionserver之間的配合,master主要做協調,regionserver做實際的工作
Region compaction
其實用storefile compaction來表示更合適,compaction分為兩種,minor和major
Minor
Minor compaction主要合並一些小的相鄰的hfile,重寫進一個新的hfile。重寫的過程不包括數據的drop,filter,delete等移除操作,只是簡單的把小文件合並成大文件。
Major
major compaction會把所有需要清除的數據都移除,最終合並成一個storefile。合並過程中服務還是可以使用,但是會慢一點。
major合並的主要目的是為了提高性能,但是major操作本身也是一個耗費資源(cpu,mem)的過程,默認是7天合並一次,但是這個時間點可能並不是最合適的。所以我們可以手動操作major。
數據需要被移除一般有三種情況
1) 客戶端顯示的聲明delete
2) 某些column family的version超過max version
3) 某些設置了TTL的column family
參考資料
//hbase官網推薦的region split 博客
https://hortonworks.com/blog/apache-hbase-region-splitting-and-merging/
hbase(一)region