
requests庫和BeautifulSoup4庫爬取新聞列表
阿新 • • 發佈:2017-09-28
blog 結果 分析 代碼 ner eba etime 包裝 mat
畫圖顯示:
import jieba from wordcloud import WordCloud import matplotlib.pyplot as plt txt = open("zuihou.txt","r",encoding=‘utf-8‘).read() wordlist = jieba.lcut(txt) wl_split=" ".join(wordlist) mywc = WordCloud().generate(wl_split) plt.imshow(mywc) plt.axis("off") plt.show()
結果:
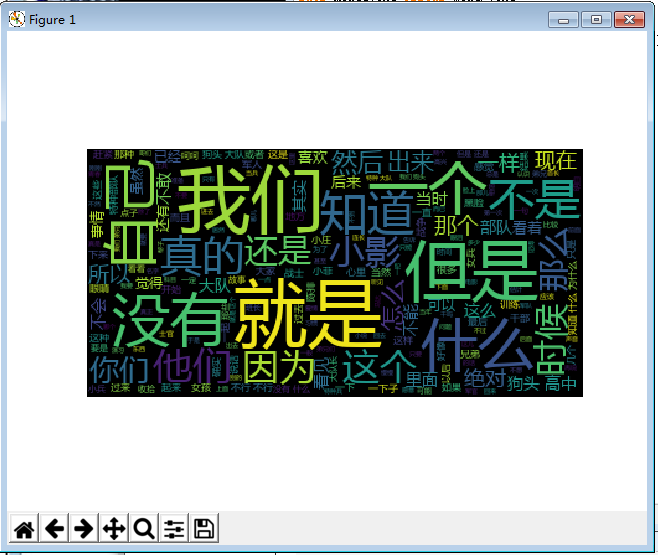
用requests庫和BeautifulSoup4庫,爬取校園新聞列表的時間、標題、鏈接、來源、詳細內容
爬蟲,網頁信息
import requests from bs4 import BeautifulSoup gzccurl = ‘http://news.gzcc.cn/html/xiaoyuanxinwen/‘ res = requests.get(gzccurl) res.encoding = ‘utf-8‘ soup = BeautifulSoup(res.text,‘html.parser‘) for news in soup.select(‘li‘): if len(news.select(‘.news-list-title‘))>0: title = news.select(‘.news-list-title‘)[0].text url = news.select(‘a‘)[0][‘href‘] print(title,url)
結果:
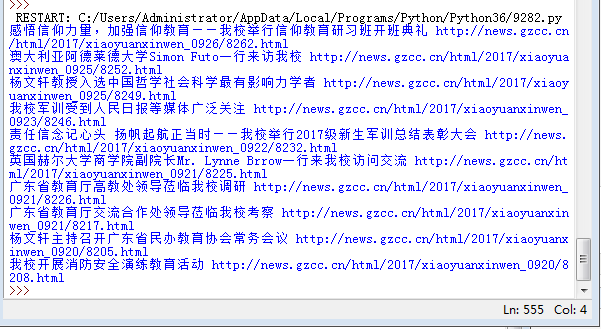
加上時間:
for news in soup.select(‘li‘): if len(news.select(‘.news-list-title‘))>0: title = news.select(‘.news-list-title‘)[0].text url = news.select(‘a‘)[0][‘href‘] time = news.select(‘.news-list-info‘)[0].contents[0].text print(time,title,url)
效果:

- 將其中的時間str轉換成datetime類型。
- 將取得詳細內容的代碼包裝成函數。
import requests from bs4 import BeautifulSoup from datetime import datetime gzccurl = ‘http://news.gzcc.cn/html/xiaoyuanxinwen/‘ res = requests.get(gzccurl) res.encoding = ‘utf-8‘ soup = BeautifulSoup(res.text,‘html.parser‘) def getdetail(url): resd = requests.get(url) resd.encoding= ‘utf-8‘ soupd = BeautifulSoup(resd.text,‘html.parser‘) return(soupd.select(‘.show-content‘)[0].text) for news in soup.select(‘li‘): if len(news.select(‘.news-list-title‘))>0: title = news.select(‘.news-list-title‘)[0].text url = news.select(‘a‘)[0][‘href‘] time = news.select(‘.news-list-info‘)[0].contents[0].text dt = datetime.strptime(time,‘%Y-%m-%d‘) source = news.select(‘.news-list-info‘)[0].contents[1].text detail = getdetail(url) print(dt,title,url,source,detail)
結果:
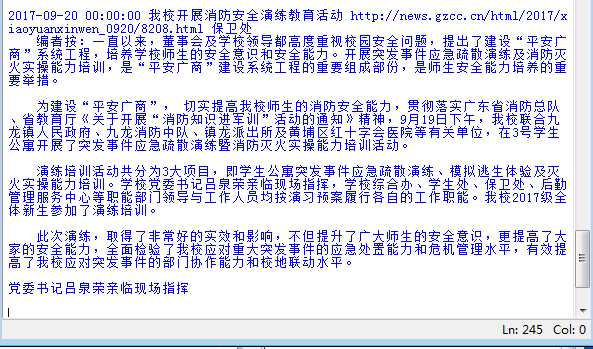
- 選一個自己感興趣的主題,做類似的操作,為後面“爬取網絡數據並進行文本分析”做準備。
import requests from bs4 import BeautifulSoup from datetime import datetime gzccurl = ‘http://www.lbldy.com/tag/gqdy/‘ res = requests.get(gzccurl) res.encoding = ‘utf-8‘ soup = BeautifulSoup(res.text,‘html.parser‘) def getdetail(url): resd = requests.get(url) resd.encoding= ‘utf-8‘ soupd = BeautifulSoup(resd.text,‘html.parser‘) return(soupd.select(‘.show-content‘)[0].text) for news in soup.select(‘h4‘): print(news)
結果:

requests庫和BeautifulSoup4庫爬取新聞列表