
數據挖掘在大數據中的應用綜述
數據挖掘在大數據中的應用綜述
***
(上海海事大學 上海 201306)
摘 要: 面對大規模多源異構的數據,數據挖掘的方法不斷的得到改善與發展,同時對於數據挖掘體系的完善也提出了新的挑戰。針對當前數據挖掘在大數據方面的應用,本文從數據挖掘的各個階段進行了方法論的總結及應用,主要包括數據準備的方法、數據探索的方法、關聯規則方法、數據回歸方法、數據分類方法、數據聚類方法、數據預測方法和數據診斷方法。最後還指出類數據挖掘在魯棒性表達方面的進一步研究。
關鍵詞: 數據挖掘;方法論;大數據;魯棒性
Application of Data Mining in Large Data
***
(Shanghai Maritime University,Shanghai 201306)
Abstract: In the face of large-scale multi-source heterogeneous data, data mining methods continue to improve and develop, at the same time for the improvement of data mining system also put forward new challenges. In this paper, the method of data mining, the method of data exploration, the association rule method, the data regression method, the data classification method, the data classification method, the data classification method, the data classification method, the data classification method, the data classification method, the data classification method, the data classification method, Data clustering method, data prediction method and data diagnosis method. Finally, it also points out the further research on the robustness of class data mining.
Key words: Data mining; methodology; large data; robustness
隨著人類生活方式的多樣化,由此產生的數據的規模和復雜性也在急速增長,對於數據的各種分析也應運而生。在數據挖掘領域,對於大數據的分析可謂是越來越成為時代的主流。科技時代下,數據成為各行各業發展的依據和關鍵,面對如此龐大的數據,數據挖掘承擔了十分重要的角色。在大數據時代下,數據挖掘成為行業間溝通的橋梁,可以說,誰掌握了數據,誰就擁有了行業的主導權。因此,數據挖掘在大數據中顯得尤為重要。
大數據的定義可謂是五花八門,但是不管哪種定義,大數據並不是一種新的產品也不是一種新的技術,大數據只是一種數字化時代下的現象。大數據由海量交易數據、海量交互數據和海量數據處理三大主要的技術趨勢匯集而成。大數據的特征是數據體量巨大、數據種類繁多、流動速度快、價值密度低,大數據的"4V"特征表明其不僅僅是海量數據,對於大數據的分析將更加復雜、更追求速度、更註重實效。
數據挖掘已經在大數據中得到了廣泛的應用,並且獲得了成功。數據挖掘就是從大量的、不完全的、有噪聲的、模糊的、隨機的實際應用數據中,提取隱含在其中的、人們事先不知道的,但又潛在有用的信息和知識的過程,數據挖掘是在沒有明確假設的前提下去挖掘信息,發現知識。數據挖掘基於的數據庫類型主要有關系型數據庫、面向對象數據庫、事物數據庫、演義數據庫、時態數據庫、多媒體數據庫、主動數據庫、空間數據庫、文本型、Internet信息庫以及新興的數據倉庫,數據挖掘的內容主要集中在關聯、回歸、分類、聚類、預測和診斷六個方面。本文從總體上對數據挖掘有個全面的認識與了解,主要從算法及其應用的層次介紹數據挖掘在大數據方面的應用,包括數據準備的方法、數據探索的方法、關聯規則方法、數據回歸方法、數據分類方法、數據聚類方法、數據預測方法、數據診斷方法。另外還包括時間序列方法和智能優化方法,本文不做陳述。
-
數據準備的方法
數據的準備包括數據的收集、數據的質量分析和數據的預處理。
-
數據的收集
數據的抽樣方法:
(1)簡單隨機抽樣
(2)系統抽樣
(3)整群抽樣
(4)分層抽樣
-
數據的質量分析
(1)值分析:包括唯一值分析、無效值分析、異常值分析
(2)統計分析:包括眾數、分位數、中位數、偏度
(3)頻次與直方圖分析:包括頻次圖和直方圖分析方法
-
數據的預處理
(1)數據清洗:對於缺失值的處理,一般采用刪除法和插補法;對於噪聲的過濾,一般采用回歸法、均值平均法、離群點分析、小波去噪
(2)數據集成:包括聯邦數據庫、中間件集成方法和數據倉庫方法。
(3)數據規約:包括數據選擇和樣本選擇。
(4)數據變換:包括標準化、離散化和語義轉換
-
數據探索的方法
數據探索中常用的方法包括衍生變量、數據的統計、數據可視化、樣本選擇和數據降維。
-
衍生變量
衍生變量常用的方法:
(1)對多個列變量進行組合
(2)按照維度分類匯總
(3)對某個變量進一步分解
(4)對具有時間序列特征的變量提取時間特征
-
數據的統計
數據的統計一般包括基本描述性統計和分布描述性統計
(1)基本描述性統計:包括表示位置的統計量,算數平均數和中位數;表示數據散度的統計量,標準差、方差和極差;表示分布形狀的統計量,偏度和峰度
(2)分布描述性統計:包括隨機變量的分布函數和密度函數
-
數據可視化
數據的可視化一般包括基本可視化,數據分布形狀可視化,數據關聯情況可視化和數據分組可視化。
-
樣本選擇
樣本的選擇方法主要包括隨機取樣法、順序取樣法和監督取樣法。
-
數據降維
主成分分析法是采用一種數學降維的方法,設法做的就是將原來眾多具有一定相關性的變量,重新組合為一組新的相互無關的綜合變量來代替原來變量。
主成分分析法的步驟:
(1)對原始數據進行標量化處理
(2)計算相關系數矩陣R
(3)計算相關系數矩陣R的特征值和相應的特征向量
(4)選擇重要的主成分,並寫出主成分表達式
(5)計算主成分得分
(6)依據主成分得分的數據,進一步對問題進行後續的分析、建模
-
主成分分析法在大數據的應用
對於企業的綜合實力進行排序,是PCA成功的應用實例。根據不同企業的凈資產、固定資產利潤率、總產值利潤率、銷售收入利潤率、產品成本利潤率、物耗利潤率、人均利潤率和物流資金利潤率組成的矩陣,對企業綜合實力進行排序。
-
關聯規則的方法
關聯規則常用的方法包括Apriori算法和FP-Growth算法。
-
Apriori算法
Apriori算法使用頻繁項集性質的先驗知識,其主要步驟如下:
- 掃描全部數據,產生候選1-項集的集合C1;
- 根據最小支持度,由候選1-項集的集合C1產生頻繁1-項集的集合L1;
- 對k>1,重復執行步驟4)、5)、6);
- 由Lk執行連接和剪枝操作,產生(k+1)-項集的的集合Ck+1;
- 根據最小支持度,由候選(k+1)-項集的集合Ck+1,產生頻繁(k+1)-項集的集合Lk+1;
- 若L不等於空集,則k=k+1,跳往步驟4);否則,跳往步驟7);
- 根據最小置信度,由頻繁項集產生強關聯規則,結束。
-
FP-Growth算法
FP-Growth算法將提供頻繁項集的數據庫壓縮到一顆頻繁模式數,但是任然保留項集的關聯信息,與Apriori算法的最大不同有兩點,第一,不產生候選碼,第二,只需要兩次遍歷數據庫。其主要步驟如下:
- 按照以下步驟構造FP-樹:掃描事務數據庫D一次。收集頻繁項的集合F和他們的支持度;創建FP-樹的根節點,以"null"標記它。
- 根據FP-樹挖掘頻繁項集。
-
Apriori算法的在大數據的應用
行業關聯選股法就是一種基於關聯規則的選股方法,其基本思想就是從數據中選擇有聯動關聯的行業,當某個行業出現漲勢之後,而其相關聯行業還沒有開始漲,則從其關聯行業中選擇典型個股買入。
-
數據回歸方法
數據回歸方法包括一元線性、一元非線性、多元線性、多元非線性、逐步回歸和Logstic回歸。由於前四種回歸方式比較簡單,只對後兩種回歸進行介紹。
-
逐步回歸
逐步回歸的基本思想有進有出。引入一個變量或者從回歸方程總剔除一個變量為逐步回歸的一步,每一步都要進行F檢驗。算法的基本步驟如下:
- 計算變量均值和差平方和
- 計算自變量和因變量的相關系數矩陣R
- 設已經選上K個變量,R(0)經過變換後為R(k)。逐一計算標準化變量的偏回歸平方和,作F檢驗,對給定的顯著性水平,計算拒絕域。
-
將步驟3循環,直至最終選上了t個變量,求出對應的回歸方程。
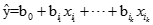
-
Logistic回歸
Logistic回歸是一個概率模型,可以利用它預測某個時間發生的概率,通常將f(p)定義為Logit函數。
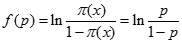
-
回歸方法在大數據中的應用
多因子模型是應用最廣泛的一種選股模型,基本原理正是采用一系列的因子作為選股標準,滿足這些因子的股票則被買入,不滿足的則被賣出。多因子選股模型的建立過程主要分為候選因子的提取、選股因子有效性的檢驗、有效但冗余因子的剔除、綜合評分模型的建立和模型的評價及持續改進5個步驟。這5個步驟中,回歸方法可以用來輔助篩選因子、檢驗因子有效性、冗余因子的剔除,也可以直接用回歸方程建立綜合評分模型。
-
數據分類方法
常見的分類方法有7種,包括K-近鄰、貝葉斯分類、神經網絡、Logtic、判別分析、支持向量機和決策樹。
-
K-近鄰
K-近鄰分類方法通過計算每個訓練樣例到待分類樣品的距離,取和待分類樣品距離最近的K個訓練樣例,K個樣品中那個類別的訓練樣本占多數,則待分類元祖就屬於那個類別。
KNN算法的具體步驟:
- 初始化距離為最大值;
- 計算未知樣本和每個訓練樣本的距離dist;
- 得到k個最近鄰樣本中的最大距離maxdist;
- 若dist小於maxdist,則將樣本作為K-最近鄰樣本;
- 重復2到4步驟,直到未知樣本和所有訓練樣本的距離用完;
- 統計K個最近樣本中每個類別出現的次數;
- 選出頻率最大的類別作為未知樣本的類別;
-
貝葉斯分類
貝葉斯分類是一類利用概率統計知識進行分類的算法,其分類原理是貝葉斯定理
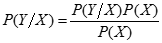
其算法的步驟如下:
- X為一個待分類項,而每個a為X的一個特征屬性
- 確定類別集合C
- 計算各個條件概率
- 求解在待分類項出現的條件下,集合C中事件發生的概率,哪個最大,集合C中事件就屬於哪個項。
-
神經網絡
人工神經網絡是一種應用類似於大腦神經突觸連接的結構,進行信息處理的數學模型。人工神經網絡的研究是由試圖模擬生物神經系統而激發的,其重要的模型為感知器,感知器模型如下:
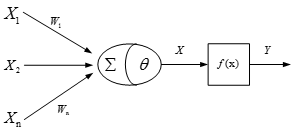
圖1 感知器模型
感知器包括兩個節點,幾個輸入點和一個輸出點,在感知器中,每個輸入節點都通過一個加權的鏈連接到輸出節點。其具體算法如下:
- 令D是訓練樣例集合
- 用隨機值初始化權值向量W
- 對每個訓練樣例,計算預測輸出
- 對每個權值W更新權值
-
重復步驟3和步驟4,算法更新的主要計算公式為:
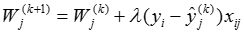
其中
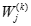 是第k次循環後第i個輸入鏈上的權值,參數
是第k次循環後第i個輸入鏈上的權值,參數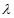 成為學習率,
成為學習率,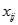 是訓練樣例
是訓練樣例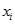 的第j個屬性值
的第j個屬性值 -
Logstic
Logstic算法已經在前面進行了介紹,這裏可以陳述一下Logstic的特點
- 預測值域0-1,適合二分類問題
- 模型的值呈現S-形曲線,符合某種特殊的預測
-
判別分析
判別分析是根據觀察或者預測到的若幹變量值判斷研究對象如何分類的方法。判別分析對判別變量有三個基本建設:
- 每個判別變量不能是其他判別變量的線性組合
- 各組案例的協方差矩陣相等
-
各個判別變量之間具有多元正態分布
判別分析的基本模型就是判別函數:
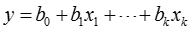
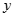 是判別函數值,又簡稱為判別值;
是判別函數值,又簡稱為判別值;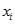 是各判別變量;
是各判別變量;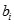 為相應的判別系數
為相應的判別系數 -
支持向量機
支持向量機構建了一個分割兩類的超平面,該算法師徒使兩類之間的分割達到最大化,以一個很大的邊緣分隔兩個類,可以使期望泛化誤差最小化。
支持向量機最初是在研究線性可分問題的過程中提出的,所以常用的線性支持向量機模型為:
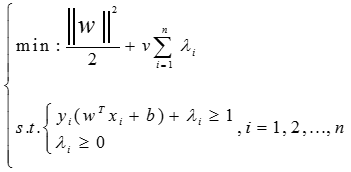
支持向量機的理論有三個要點,最大化間距,核函數,對偶理論。
-
決策樹
決策樹是最為廣泛的歸納推理算法之一,處理類別型或連續型變量的分類預測問題,可以用圖形和if-then的規則表示模型,可讀性較高。決策樹是一種監督式的學習方法,產生一種類似流程圖的樹結構。決策樹的構建步驟主要有三個:
- 選擇適當的算法訓練樣本構建決策樹
- 適當的修剪決策樹
-
從決策樹中萃取知識規則
決策樹的算法基本上是一種貪心算法,由上而下的逐次搜索方式,漸漸產生決策樹模型結構。ID3是著名的決策樹算法,以信息論為基礎,企圖最小化變量間比較的次數,其基本策略是選擇具有最高信息增量的變量為分割變量,ID3算法必須將所有變量轉化為類別變量
ID3算法的步驟:
- 模型由代表訓練樣本開始,樣本屬於同一類別,節點成為樹葉,並使用該類別的標簽
- 如果樣本不屬於同一個類別,算法使用信息增量選擇將樣本最佳分類的變量
- 算法使用的過程,逐次形成每個分割的樣本決策樹,如果一個變量出現在一個節點上,就不必在後續分割時考慮該變數
- 當給定節點的所有樣本屬於同一類別,或沒有剩余變量可以進一步分割樣本,此時分割的動作就可以停止。
-
分類算法在大數據中的應用
分類在量化投資中是一種十分實用的技術。在股票投資中,將股票分為三類:漲、持平和跌。在進行選股時,可以根據數據訓練一個分類器,再利用該分類器,實現對近期或者未來一段時間的股票進行預測。
-
數據的聚類方法
常見的聚類方法包括k-means、層次聚類、神經網絡、模糊C-均值聚類、高斯混合聚類
-
k-means
劃分的基本思想是給定一個有N個元組或者記錄的數據集,分裂法將構造K個分組,每一個分組就代表一個聚類。算法步驟:
- 從n個數據對象中任意選擇k個對象作為初始聚類中心
- 循環3到4步驟,直到每個聚類不再發生變化
- 根據每個聚類對象的均值,計算每個對象與中心的距離,並根據最小距離重新對相應對象進行劃分。
- 重新計算每個聚類的均值,直到聚類中心不再變化。
-
層次聚類
層次聚類算法是通過將數據組織為若幹組並形成一個相應的樹來進行聚類的。兩種常用的層次聚類算法是凝聚的層級聚類和分裂的層次聚類。
- 凝聚的層級聚類算法步驟:
- 將D中每個樣本點當做其類族
- 重復
- 找到分屬於兩個不同類族,且距離最近的樣本點對
- 將兩個類族合並
- 直到類族數=K
- 分裂的層次聚類算法步驟:
- 將D中所有樣本點歸並成類聚
- 重復
- 在同類族中找到距離最遠的樣本點對
- 以該樣本點對為代表,將原類族中的樣本點重新分屬到新類族
- 直到類族數=K
-
神經網絡聚類
神經網絡在聚類方面表現的特征與分類相似,對數據適應性強,對噪聲數據敏感。神經網絡的輸入具有連續性,但聚類結果往往是分類數據類型。
-
模糊C-均值聚類
模糊C均值聚類是用隸屬度確定每個數據點屬於某個聚類的程度的一種聚類算法。具體步驟如下:
-
確定類的個數C,冪指數M>1和初始隸屬度矩陣
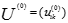 ,通常的做法是取[0,1]上的均值分布隨機數來確定初始隸屬度矩陣
,通常的做法是取[0,1]上的均值分布隨機數來確定初始隸屬度矩陣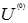 。令l=1表示第1步叠代。
。令l=1表示第1步叠代。
-
通過俠士計算第L步的聚類中心
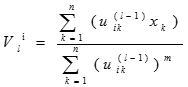
-
修正隸屬度矩陣
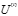 ,計算目標函數值
,計算目標函數值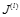
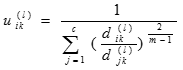
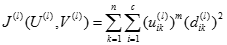
-
對於給定的隸屬度種植容限
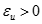 ,當
,當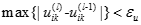 時,停止叠代,否則l=l+1,然後轉到步驟2)。
時,停止叠代,否則l=l+1,然後轉到步驟2)。
-
高斯混合聚類
高斯混合聚類方法和K-means相似,區別在於高斯混合聚類引入了概率。高斯混合聚類學習的過程就是訓練出幾個概率分布,所謂混合高斯模型就是對樣本的概率密度分布進行估計,而估計的模型是幾個高斯模型加權之和。每個高斯模型就代表一個類,對樣本的數據分別在幾個高斯模型上進行投影,就分別得到了各個類上的概率。我們選取概率最大的作為判別結果。
-
聚類方法在大數據中的應用
聚類方法在量化投資中的主要作用是對投資對象進行聚類,然後根據聚類的結果評估每個類別的盈利能力,選擇盈利強的類別的對象進行投資。
-
數據的預測方法
常見的預測方法
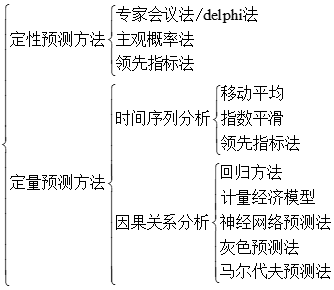
這裏對灰色預測法和馬爾科夫法進行介紹
-
灰色預測
灰色預測是以灰色模型為基礎,在諸多模型中,以灰色系統中單序列一階線性微分方程模型GM(1,1)最常用。
GM(1,1)模型:
-
原始數據累加以便弱化隨機序列的波動性和隨機性,得到新數據序列:
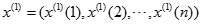
-
對
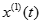 建立
建立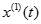 的一階線性微分方程,即:
的一階線性微分方程,即:
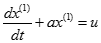
-
對累加生成數據作均值生成B與常數項向量
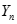
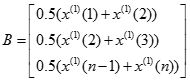
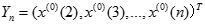
- 用最小二乘法計算灰度參數
-
將灰度參數帶入一階線性微分方程並且求得
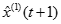
-
對函數表達式
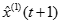 及
及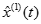 進行離散並且將二者作差以便還原
進行離散並且將二者作差以便還原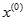 原序列,得到近似數據序列
原序列,得到近似數據序列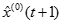
- 對建立的灰色模型進行檢驗
-
利用模型進行預測
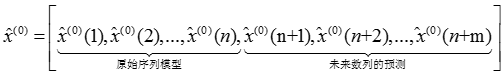
-
馬爾科夫預測
馬爾科夫預測具有馬爾科夫性,預測時刻的狀態治愈當前狀態有關,與前期狀態無關。馬爾科夫預測的步驟如下:
- 根據數據表,寫出模型的一步轉移概率矩陣
- 緊接著構造出任意K步轉移矩陣
- 最後根據模型求解
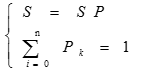
-
預測方法在大數據中的應用
在股票的走勢分析中,經常用馬爾科夫性來進行股票走勢的預測。
-
數據的診斷方法
常用的數據的診斷方法包括基於統計的離群點診斷、基於距離的離群點診斷、基於密度的離群點診斷和基於聚類的離群點診斷。
-
基於統計的離群點診斷
基於統計的離群點診斷的基本思想:符合正態總體分布的對象出現在分布尾部的機會很少。其算法如下:
-
求出樣本均值
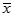 和樣本標準差S。根據給定的顯著水平
和樣本標準差S。根據給定的顯著水平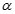 和樣本容量n,查表求出
和樣本容量n,查表求出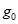
-
計算
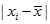 ,找出
,找出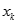 ,使得
,使得
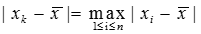
-
若有
 ,則認為無異常數據,否則,將之剔除。
,則認為無異常數據,否則,將之剔除。
-
基於距離的離群點診斷
某個對象遠離大部分其他對象,則該對象是離群的。基於距離方法的兩種不同策略:第一種策略采用給定鄰域半徑,依據點的鄰域中包含的對象多少來判定離群點;第二種策略是利用K-最近鄰距離的大小來判定離群。離群因子的定義:
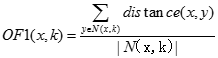
-
基於密度的離群點診斷
探測局部密度,通過不同的密度估計策略來檢測離群點。一種常用的定義密度的方法是,定義密度為k個最近鄰的平均距離的倒數
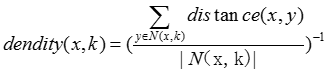
具體的基於密度的離群點的步驟如下:
- {k是最近鄰個數}
- For all 對象 x do
- 確定x的k-最近鄰N(x,k)
- 使用x的最近鄰(即N(x,k)中的對象),確定x的密度density(x,k)
- End for
- For all 對象 x do
- 確定x的相對密度relative density(x,k),並且賦值給LOF(X,K)
- End for
- 對LOF(X,K)降序排序,確定離群點得分高的若幹對象
-
基於聚類的離群點診斷
聚類分析是用來發現數據集中強相關的對象組,而離群點診斷是發現不與其他對象組強相關的對象。基於聚類的離群點診斷步驟如下:
-
對數據集D進行采用一趟聚類算法進行聚類,得到聚類結果
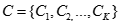
-
計算數據集D中所有對象P的離群因子OF3(P),及其平均值Ave_OF和標準差Dev_OF,滿足條件的
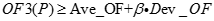 的對象為離群點。
的對象為離群點。
-
離群點診斷在大數據中的應用
離群點診斷的主要目的是發現異常,這種異常在股票投資中十分有用,所以離群點診斷在股票買賣時可以發揮重要的作用。
結束語
數據挖掘作為近年來十分流行的一門學科,在各個行業,尤其是金融、互聯網方面發揮了巨大的作用。經過多年的時間證明,數據挖掘能夠提高團隊的生產率,產品的質量和產品的滿意度。但是,由於數據挖掘還存在許多問題,今後還有很多工作值得進一步深入研究。例如,面向大規模多源異構數據的魯棒特性的表達。
參考文獻
- 趙培鴻. Web數據挖掘綜述[J]. 無線互聯科技,2013,02:6-7.
- 陶雪嬌,胡曉峰,劉洋. 大數據研究綜述[J]. 系統仿真學報,2013,S1:142-146.
- 樊嘉麒. 基於大數據的數據挖掘引擎[D].北京郵電大學,2015.
- 夏天維. 計算機數據挖掘技術的開發及其應用探究[A]. 《決策與信息》雜誌社、北京大學經濟管理學院."決策論壇——管理科學與工程研究學術研討會"論文集(下)[C].《決策與信息》雜誌社、北京大學經濟管理學院:,2016:1.
數據挖掘在大數據中的應用綜述