
Mysql加鎖過程詳解(4)-select for update/lock in share mode 對事務並發性影響
事務並發性理解
事務並發性,粗略的理解就是單位時間內能夠執行的事務數量,常見的單位是 TPS( transactions per second).
那在數據量和業務操作量一定的情況下,常見的提高事務並發性主要考慮的有哪幾點呢?
1.提高服務器的處理能力,讓事務的處理時間變短。
這樣不僅加快了這個事務的執行時間,也降低了其他等待該事務執行的事務執行時間。
2.盡量將事務涉及到的 sql 操作語句控制在合理範圍,換句話說就是不要讓一個事務包含的操作太多或者太少。
在業務繁忙情況下,如果單個事務操作的表或者行數據太多,其他的事務可能都在等待該事務 commit或者 rollback,這樣會導致整體上的 TPS 降低。但是,如果每個 sql 語句都是一個事務也是不太現實的。一來,有些業務本身需要多個sql語句來構成一個事務(比如匯款這種多個表的操作);二來,每個 sql 都需要commit,如果在 mysql 裏 innodb_flush_log_at_trx_commit=1 的情況下,會導致 redo log 的刷新過於頻繁,也不利於整體事務數量的提高(IO限制也是需要考慮的重要因素)。
3.在操作的時候,盡量控制鎖的粒度,能用小的鎖粒度就盡量用鎖的粒度,用完鎖資源後要記得立即釋放,避免後面的事務等待。
但是有些情況下,由於業務需要,或者為了保證數據的一致性的時候,必須要增加鎖的粒度,這個時候就是下面所說的幾種情況。
select for update 理解
select col from t where where_clause for update 的目的是在執行這個 select 查詢語句的時候,會將對應的索引訪問條目進行上排他鎖(X 鎖),也就是說這個語句對應的鎖就相當於update帶來的效果。
那這種語法為什麽會存在呢?肯定是有需要這種方式的存在啦!!請看下面的案例描述:
案例1:
前提條件:
mysql 隔離級別 repeatable-read ,
事務1:
建表: CREATE TABLE `lockt` ( `id` int(11) NOT NULL, `col1` int(11) DEFAULT NULL, `col2` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `col1_ind` (`col1`), KEY `col2_ind` (`col2`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 插入數據 。。。。。 mysql> set autocommit=0; Query OK, 0 rows affected (0.00 sec) mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 14 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec)
然後另外一個事務2 進行了下面的操作:
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 14 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec) mysql> update lockt set col2= 144 where col2=14; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec)
結果:可以看到事務2 將col2=14 的列改為了 col2=144.
可是事務1繼續執行的時候根本沒有覺察到 lockt 發生了變化,請看 事務1 繼續後面的操作:
mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 14 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.01 sec) mysql> update lockt set col2=col2*2 where col2=14; Query OK, 0 rows affected (0.00 sec) Rows matched: 0 Changed: 0 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 144 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec)
結果: 事務1 明明查看到的存在 col2=12 的行數據,可是 update 後,竟然不僅沒有改為他想要的col2=28 的值,反而變成了 col2=144 !!!!
這在有些業務情況下是不允許的,因為有些業務希望我通過 select * from lockt; 查詢到的數據是此時數據庫裏面真正存儲的最新數據,並且不允許其他的事務來修改只允許我來修改。(這個要求很霸氣,但是我喜歡。。)
這種情況就是很牛逼的情況了。具體的細節請參考下面的案例2:
案例2:
mysql 條件和案例1 一樣。
事務1操作:
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from lockt where col2=20 for update; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 8 | 8 | 20 | +----+------+------+ 1 row in set (0.00 sec)
事務2 操作:
mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 144 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec) mysql> update lockt set col2=222 where col2=20;
註意: 事務2 在執行 update lockt set col2=222 where col2=20; 的時候,會發現 sql 語句被 block住了,為什麽會發現這種情況呢?
因為事務1 的 select * from lockt where col2=20 for update; 語句會將 col2=20 這個索引的入口給鎖住了,(其實有些時候是範圍的索引條目也被鎖住了,暫時不討論。),那麽事務2雖然看到了所有的數據,但是想去修改 col2=20 的行數據的時候, 事務1 只能說 “不可能也不允許”。
後面只有事務1 commit或者rollback 以後,事務2 的才能夠修改 col2=20 的這個行數據。
總結:
這就是 select for update 的使用場景,為了避免自己看到的數據並不是數據庫存儲的最新數據並且看到的數據只能由自己修改,需要用 for update 來限制。
如果看了前面的 select *** for update ,就可以很好的理解 select lock in share mode ,in share mode 子句的作用就是將查找到的數據加上一個 share 鎖,這個就是表示其他的事務只能對這些數據進行簡單的select 操作,並不能夠進行 DML 操作。
那它和 for update 在引用場景上究竟有什麽實質上的區別呢?
lock in share mode 沒有 for update 那麽霸道,所以它有時候也會遇到問題,請看案例3
案例3:
mysql 環境和案例1 類似
事務1:
mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 144 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec) mysql> select * from lockt where col2=20 lock in share mode; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 8 | 8 | 20 | +----+------+------+ 1 row in set (0.00 sec)
事務2 接著開始操作
mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 144 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec) mysql> select * from lockt where col2=20 lock in share mode; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 8 | 8 | 20 | +----+------+------+ 1 row in set (0.01 sec)
後面的比較蛋疼的一幕出現了,當 事務1 想更新 col2=20 的時候,他發現 block 住了。
mysql> update lockt set col2=22 where col2=20;
解釋:因為事務1 和事務2 都對該行上了一個 share 鎖,事務1 以為就只有自己一個人上了 S 鎖,所以當事務一想修改的時候發現沒法修改,這種情況下,事務1 需要使用 for update 子句來進行約束了,而不是使用 for share 來使用。
可能用到的情景和對性能的影響
使用情景:
1. select *** for update 的使用場景
為了讓自己查到的數據確保是最新數據,並且查到後的數據只允許自己來修改的時候,需要用到 for update 子句。
2. select *** lock in share mode 使用場景
為了確保自己查到的數據沒有被其他的事務正在修改,也就是說確保查到的數據是最新的數據,並且不允許其他人來修改數據。但是自己不一定能夠修改數據(比如a,b都拿了鎖,a更改了數據,因為b還拿著鎖,a提交不了,直到超時),因為有可能其他的事務也對這些數據 使用了 in share mode 的方式上了 S 鎖。
性能影響:
select for update 語句,相當於一個 update 語句。在業務繁忙的情況下,如果事務沒有及時的commit或者rollback 可能會造成其他事務長時間的等待,從而影響數據庫的並發使用效率。
select lock in share mode 語句是一個給查找的數據上一個共享鎖(S 鎖)的功能,它允許其他的事務也對該數據上 S鎖,但是不能夠允許對該數據進行修改。如果不及時的commit 或者rollback 也可能會造成大量的事務等待。
for update 和 lock in share mode 的區別:前一個上的是排他鎖(X 鎖),一旦一個事務獲取了這個鎖,其他的事務是沒法在這些數據上執行 for update ;後一個是共享鎖,多個事務可以同時的對相同數據執行 lock in share mode。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
例子實驗
1.lock in share mode死鎖情況
|
a |
b |
|
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
|
|
SET AUTOCOMMIT=0; |
|
|
|
|
|
BEGIN |
BEGIN |
|
SELECT * FROM test |
SELECT * FROM test |
|
|
|
SELECT * FROM test WHERE a=‘1‘ LOCK IN SHARE MODE; |
SELECT * FROM test WHERE a=‘1‘ LOCK IN SHARE MODE; |
|
|
|
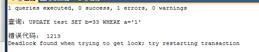
UPDATE test SET b=111 WHERE a=‘1‘
|
|
|
|
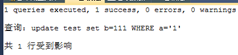
UPDATE test SET b=222 WHERE a=‘1‘ |
|
|
|
|
B死鎖了,釋放掉了s鎖,所以a就成功了 |
|
|
UPDATE test SET b=222 WHERE a=‘1‘ |
|
|
|
|
COMMIT |
|
|
|
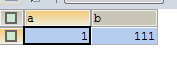
A提交後B才更新成功,因為死鎖後B丟了鎖,A才成功
|
|
SELECT * FROM test |
|
|
|
|
|
SELECT * FROM test |
|
|
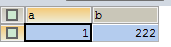
|
|
|
COMMIT |
|
SELECT * FROM test |
SELECT * FROM test |
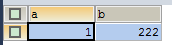
|
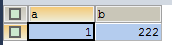
|
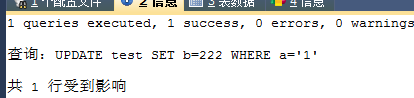
例子2 for update鎖
|
a |
b |
|
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
|
|
SET AUTOCOMMIT=0; |
|
|
|
|
|
BEGIN |
BEGIN |
|
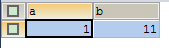
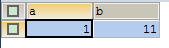
SELECT * FROM test |
SELECT * FROM test |
|
|
|
SELECT * FROM test WHERE a=‘1‘ FOR UPDATE; |
|
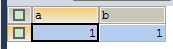
|
SELECT * FROM test WHERE a=‘1‘ FOR UPDATE; |
|
|
|
|
COMMIT |
COMMIT |
|
ForUpdate只能一個人拿到鎖,是x(排他)鎖 |
|
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
參考:http://www.cnblogs.com/liushuiwuqing/p/3966898.html
Mysql加鎖過程詳解(4)-select for update/lock in share mode 對事務並發性影響