
高吞吐低延遲Java應用的垃圾回收優化
高吞吐低延遲Java應用的垃圾回收優化
高性能應用構成了現代網絡的支柱。LinkedIn有許多內部高吞吐量服務來滿足每秒數千次的用戶請求。要優化用戶體驗,低延遲地響應這些請求非常重要。
比如說,用戶經常用到的一個功能是了解動態信息——不斷更新的專業活動和內容的列表。動態信息在LinkedIn隨處可見,包括公司頁面,學校頁面以及最重要的主頁。基礎動態信息數據平臺為我們的經濟圖譜(會員,公司,群組等等)中各種實體的更新建立索引,它必須高吞吐低延遲地實現相關的更新。
圖1 LinkedIn 動態信息
這些高吞吐低延遲的Java應用轉變為產品,開發人員必須確保應用開發周期的每個階段一致的性能。確定優化垃圾回收(Garbage Collection,GC)的設置對達到這些指標非常關鍵。
本文章通過一系列步驟來明確需求並優化GC,目標讀者是為實現應用的高吞吐低延遲,對使用系統方法優化GC感興趣的開發人員。文章中的方法來自於LinkedIn構建下一代動態信息數據平臺過程。這些方法包括但不局限於以下幾點:並發標記清除(Concurrent Mark Sweep,CMS)和G1垃圾回收器的CPU和內存開銷,避免長期存活對象引起的持續GC周期,優化GC線程任務分配使性能提升,以及GC停頓時間可預測所需的OS設置。
優化GC的正確時機?
GC運行隨著代碼級的優化和工作負載而發生變化。因此在一個已實施性能優化的接近完成的代碼庫上調整GC非常重要。但是在端到端的基本原型上進行初步分析也很有必要,該原型系統使用存根代碼並模擬了可代表產品環境的工作負載。這樣可以捕捉該架構延遲和吞吐量的真實邊界,進而決定是否縱向或橫向擴展。
在下一代動態信息數據平臺的原型階段,幾乎實現了所有端到端的功能,並且模擬了當前產品基礎架構所服務的查詢負載。從中我們獲得了多種用來衡量應用性能的工作負載特征和足夠長時間運行情況下的GC特征。
優化GC的步驟
下面是為滿足高吞吐,低延遲需求優化GC的總體步驟。也包括在動態信息數據平臺原型實施的具體細節。可以看到在ParNew/CMS有最好的性能,但我們也實驗了G1垃圾回收器。
1.理解GC基礎知識
理解GC工作機制非常重要,因為需要調整大量的參數。Oracle的Hotspot JVM 內存管理白皮書是開始學習Hotspot JVM GC算法非常好的資料。了解G1垃圾回收器,請查看該論文。
2. 仔細考量GC需求
為降低應用性能的GC開銷,可以優化GC的一些特征。吞吐量、延遲等這些GC特征應該長時間測試運行觀察,確保特征數據來自於應用程序的處理對象數量發生變化的多個GC周期。
- Stop-the-world回收器回收垃圾時會暫停應用線程。停頓的時長和頻率不應該對應用遵守SLA產生不利的影響。
- 並發GC算法與應用線程競爭CPU周期。這個開銷不應該影響應用吞吐量。
- 不壓縮GC算法會引起堆碎片化,導致full GC長時間Stop-the-world停頓。
- 垃圾回收工作需要占用內存。一些GC算法產生更高的內存占用。如果應用程序需要較大的堆空間,要確保GC的內存開銷不能太大。
- 清晰地了解GC日誌和常用的JVM參數對簡單調整GC運行很有必要。GC運行隨著代碼復雜度增長或者工作特性變化而改變。
我們使用Linux OS的Hotspot Java7u51,32GB堆內存,6GB新生代(young generation)和-XX:CMSInitiatingOccupancyFraction值為70(老年代GC觸發時其空間占用率)開始實驗。設置較大的堆內存用來維持長期存活對象的對象緩存。一旦這個緩存被填充,提升到老年代的對象比例顯著下降。
使用初始的GC配置,每三秒發生一次80ms的新生代GC停頓,超過百分之99.9的應用延遲100ms。這樣的GC很可能適合於SLA不太嚴格要求延遲的許多應用。然而,我們的目標是盡可能降低百分之99.9應用的延遲,為此GC優化是必不可少的。
3.理解GC指標
優化之前要先衡量。了解GC日誌的詳細細節(使用這些選項:-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationStoppedTime)可以對該應用的GC特征有總體的把握。
LinkedIn的內部監控和報表系統,inGraphs和Naarad,生成了各種有用的指標可視化圖形,比如GC停頓時間百分比,一次停頓最大持續時間,長時間內GC頻率。除了Naarad,有很多開源工具比如gclogviewer可以從GC日誌創建可視化圖形。
在這個階段,需要確定GC頻率和停頓時長是否影響應用滿足延遲性需求的能力。
4.降低GC頻率
在分代GC算法中,降低回收頻率可以通過:(1)降低對象分配/提升率;(2)增加代空間的大小。
在Hotspot JVM中,新生代GC停頓時間取決於一次垃圾回收後對象的數量,而不是新生代自身的大小。增加新生代大小對於應用性能的影響需要仔細評估:
- 如果更多的數據存活而且被復制到survivor區域,或者每次垃圾回收更多的數據提升到老年代,增加新生代大小可能導致更長的新生代GC停頓。
- 另一方面,如果每次垃圾回收後存活對象數量不會大幅增加,停頓時間可能不會延長。在這種情況下,減少GC頻率可能使應用總體延遲降低和(或)吞吐量增加。
對於大部分為短期存活對象的應用,僅僅需要控制前面所說的參數。對於創建長期存活對象的應用,就需要註意,被提升的對象可能很長時間都不能被老年代GC周期回收。如果老年代GC觸發閾值(老年代空間占用率百分比)比較低,應用將陷入不斷的GC周期。設置高的GC觸發閾值可避免這一問題。
由於我們的應用在堆中維持了長期存活對象的較大緩存,將老年代GC觸發閾值設置為-XX:CMSInitiatingOccupancyFraction=92 -XX:+UseCMSInitiatingOccupancyOnly。我們也試圖增加新生代大小來減少新生代回收頻率,但是並沒有采用,因為這增加了應用延遲。
5.縮短GC停頓時間
減少新生代大小可以縮短新生代GC停頓時間,因為這樣被復制到survivor區域或者被提升的數據更少。但是,正如前面提到的,我們要觀察減少新生代大小和由此導致的GC頻率增加對於整體應用吞吐量和延遲的影響。新生代GC停頓時間也依賴於tenuring threshold(提升閾值)和空間大小(見第6步)。
使用CMS嘗試最小化堆碎片和與之關聯的老年代垃圾回收full GC停頓時間。通過控制對象提升比例和減小-XX:CMSInitiatingOccupancyFraction的值使老年代GC在低閾值時觸發。所有選項的細節調整和他們相關的權衡,請查看Web Services的Java 垃圾回收和Java 垃圾回收精粹。
我們觀察到Eden區域的大部分新生代被回收,幾乎沒有對象在survivor區域死亡,所以我們將tenuring threshold從8降低到2(使用選項:-XX:MaxTenuringThreshold=2),為的是縮短新生代垃圾回收消耗在數據復制上的時間。
我們也註意到新生代回收停頓時間隨著老年代空間占用率上升而延長。這意味著來自老年代的壓力使得對象提升花費更多的時間。為解決這個問題,將總的堆內存大小增加到40GB,減小-XX:CMSInitiatingOccupancyFraction的值到80,更快地開始老年代回收。盡管-XX:CMSInitiatingOccupancyFraction的值減小了,增大堆內存可以避免不斷的老年代GC。在本階段,我們獲得了70ms新生代回收停頓和百分之99.9延遲80ms。
6.優化GC工作線程的任務分配
進一步縮短新生代停頓時間,我們決定研究優化與GC線程綁定任務的選項。
-XX:ParGCCardsPerStrideChunk 選項控制GC工作線程的任務粒度,可以幫助不使用補丁而獲得最佳性能,這個補丁用來優化新生代垃圾回收的卡表掃描時間。有趣的是新生代GC時間隨著老年代空間的增加而延長。將這個選項值設為32678,新生代回收停頓時間降低到平均50ms。此時百分之99.9應用延遲60ms。
也有其他選項將任務映射到GC線程,如果OS允許的話,-XX:+BindGCTaskThreadsToCPUs選項綁定GC線程到個別的CPU核。-XX:+UseGCTaskAffinity使用affinity參數將任務分配給GC工作線程。然而,我們的應用並沒有從這些選項發現任何益處。實際上,一些調查顯示這些選項在Linux系統不起作用[1,2]。
7.了解GC的CPU和內存開銷
並發GC通常會增加CPU的使用。我們觀察了運行良好的CMS默認設置,並發GC和G1垃圾回收器共同工作引起的CPU使用增加顯著降低了應用的吞吐量和延遲。與CMS相比,G1可能占用了應用更多的內存開銷。對於低吞吐量的非計算密集型應用,GC的高CPU使用率可能不需要擔心。

圖2 ParNew/CMS和G1的CPU使用百分數%:相對來說CPU使用率變化明顯的節點使用G1
選項-XX:G1RSetUpdatingPauseTimePercent=20
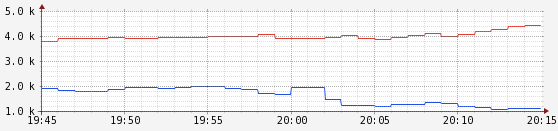
圖3 ParNew/CMS和G1每秒服務的請求數:吞吐量較低的節點使用G1
選項-XX:G1RSetUpdatingPauseTimePercent=20
8.為GC優化系統內存和I/O管理
通常來說,GC停頓發生在(1)低用戶時間,高系統時間和高時鐘時間和(2)低用戶時間,低系統時間和高時鐘時間。這意味著基礎的進程/OS設置存在問題。情況(1)可能說明Linux從JVM偷頁,情況(2)可能說明清除磁盤緩存時Linux啟動GC線程,等待I/O時線程陷入內核。在這些情況下如何設置參數可以參考該PPT。
為避免運行時性能損失,啟動應用時使用JVM選項-XX:+AlwaysPreTouch訪問和清零頁面。設置vm.swappiness為零,除非在絕對必要時,OS不會交換頁面。
可能你會使用mlock將JVM頁pin在內存中,使OS不換出頁面。但是,如果系統用盡了所有的內存和交換空間,OS通過kill進程來回收內存。通常情況下,Linux內核會選擇高駐留內存占用但還沒有長時間運行的進程(OOM情況下killing進程的工作流)。對我們而言,這個進程很有可能就是我們的應用程序。一個服務具備優雅降級(適度退化)的特點會更好,服務突然故障預示著不太好的可操作性——因此,我們沒有使用mlock而是vm.swappiness避免可能的交換懲罰。
LinkedIn動態信息數據平臺的GC優化
對於該平臺原型系統,我們使用Hotspot JVM的兩個算法優化垃圾回收:
- 新生代垃圾回收使用ParNew,老年代垃圾回收使用CMS。
- 新生代和老年代使用G1。G1用來解決堆大小為6GB或者更大時存在的低於0.5秒穩定的、可預測停頓時間的問題。在我們用G1實驗過程中,盡管調整了各種參數,但沒有得到像ParNew/CMS一樣的GC性能或停頓時間的可預測值。我們查詢了使用G1發生內存泄漏相關的一個bug[3],但還不能確定根本原因。
使用ParNew/CMS,應用每三秒40-60ms的新生代停頓和每小時一個CMS周期。JVM選項如下:
|
1 2 3 4 5 6 7 8 |
// JVM sizing options -server -Xms40g -Xmx40g -XX:MaxDirectMemorySize=4096m -XX:PermSize=256m -XX:MaxPermSize=256m // Young generation options -XX:NewSize=6g -XX:MaxNewSize=6g -XX:+UseParNewGC -XX:MaxTenuringThreshold=2 -XX:SurvivorRatio=8 -XX:+UnlockDiagnosticVMOptions -XX:ParGCCardsPerStrideChunk=32768 // Old generation options -XX:+UseConcMarkSweepGC -XX:CMSParallelRemarkEnabled -XX:+ParallelRefProcEnabled -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSInitiatingOccupancyOnly // Other options -XX:+AlwaysPreTouch -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationStoppedTime -XX:-OmitStackTraceInFastThrow |
使用這些選項,對於幾千次讀請求的吞吐量,應用百分之99.9的延遲降低到60ms。
高吞吐低延遲Java應用的垃圾回收優化