
第七篇 css選擇器實現字段解析
阿新 • • 發佈:2017-10-02
resp 文章 elf span ext div ant rec normalize 
CSS選擇器的作用實際和xpath的一樣,都是為了定位具體的元素
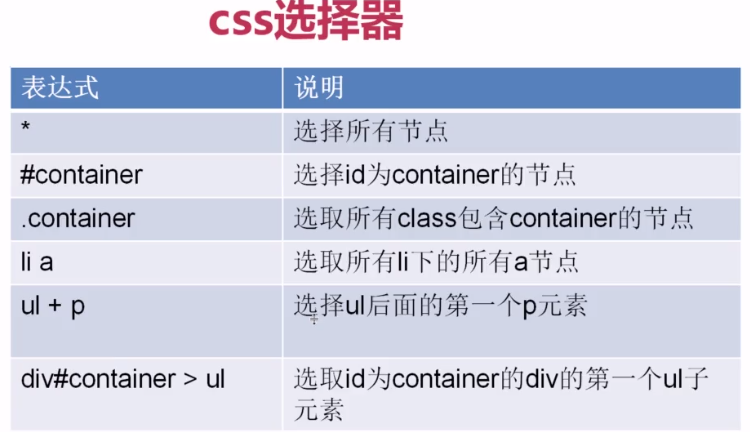
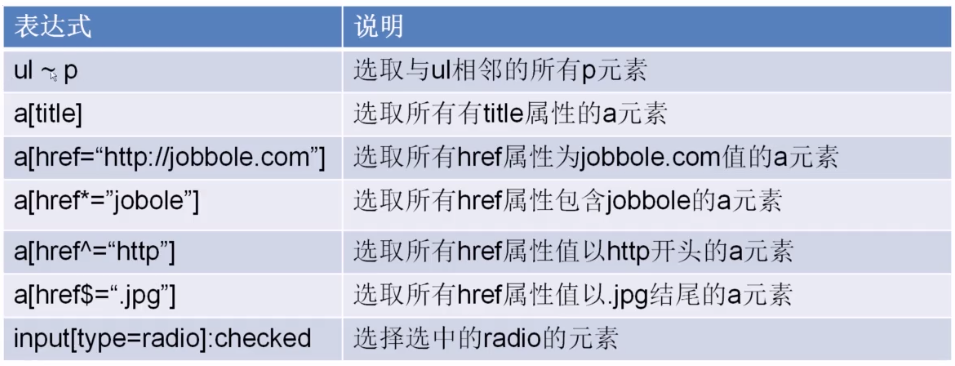

舉例我要爬取下面這個頁面的標題
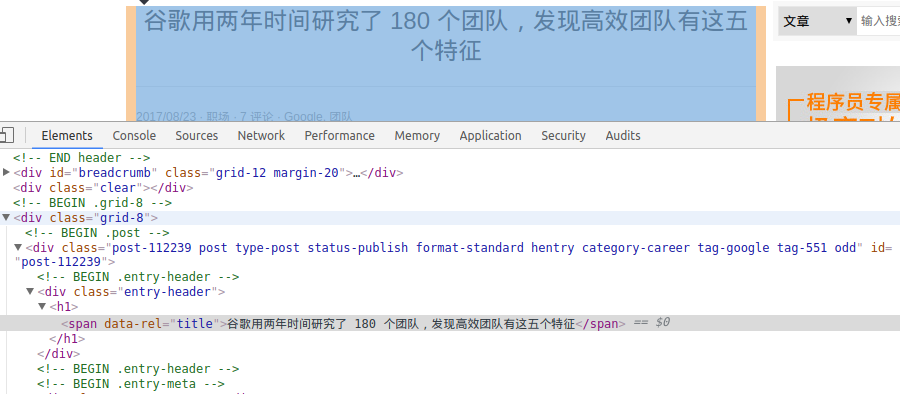
In [20]: title = response.css(".entry-header h1") In [21]: title Out[21]: [<Selector xpath="descendant-or-self::*[@class and contains(concat(‘ ‘, normalize-space(@class), ‘ ‘), ‘ entry-header ‘)]/descendant-or-self::*/h1" data=‘<h1>谷歌用兩年時間研究了 180 個團隊,發現高效團隊有這五個特征</h1>‘>] In [22]: title = response.css(".entry-header h1").extract() In [23]: title Out[23]: [‘<h1>谷歌用兩年時間研究了 180 個團隊,發現高效團隊有這五個特征</h1>‘] In [24]: ##可以使用css的::text取到內容 In [25]: title = response.css(".entry-header h1::text").extract() In [26]: title Out[26]: [‘谷歌用兩年時間研究了 180 個團隊,發現高效團隊有這五個特征‘]
獲取文章創建日期:
In [38]: date_text = response.css(".entry-meta-hide-on-mobile").extract() In [39]: date_text Out[39]: [‘<p class="entry-meta-hide-on-mobile">\r\n\r\n 2017/08/23 · <a href="http://blog.jobbole.com/category/career/" rel="category tag">職場</a>\r\n \r\n · <a href="#article-comment"> 7 評論 </a>\r\n \r\n\r\n \r\n · <a href="http://blog.jobbole.com/tag/google/">Google</a>, <a href="http://blog.jobbole.com/tag/%e5%9b%a2%e9%98%9f/">團隊</a>\r\n \r\n</p>‘] In [40]: date_text = response.css(".entry-meta-hide-on-mobile::text").extract() In [41]: date_text Out[41]: [‘\r\n\r\n 2017/08/23 · ‘, ‘\r\n \r\n · ‘, ‘\r\n \r\n\r\n \r\n · ‘, ‘, ‘, ‘\r\n \r\n‘] In [42]: date_text = response.css(".entry-meta-hide-on-mobile::text").extract()[ ...: 0] In [43]: date_text Out[43]: ‘\r\n\r\n 2017/08/23 · ‘ In [44]: date_text = response.css(".entry-meta-hide-on-mobile::text").extract()[ ...: 0].strip() In [45]: date_text Out[45]: ‘2017/08/23 ·‘ In [46]: date_text = response.css(".entry-meta-hide-on-mobile::text").extract()[ ...: 0].strip().replace("·","").strip() In [47]: date_text Out[47]: ‘2017/08/23‘
獲取評論數
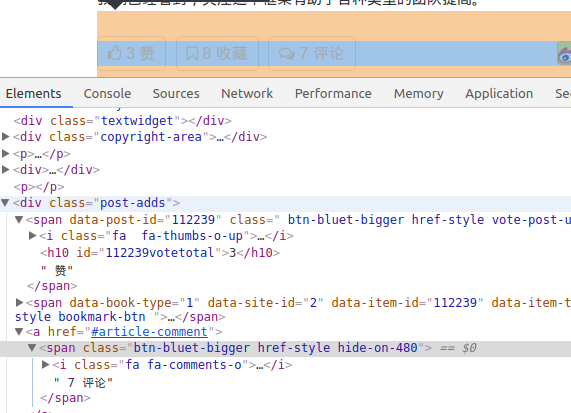

In [49]: comment_num = response.css("a[href=‘#article-comment‘]") In [50]: comment_num Out[50]: [<Selector xpath="descendant-or-self::a[@href = ‘#article-comment‘]" data=‘<a href="#article-comment"> 7 評論 </a>‘>, <Selector xpath="descendant-or-self::a[@href = ‘#article-comment‘]" data=‘<a href="#article-comment"><span class="‘>] In [51]: comment_num = response.css("a[href=‘#article-comment‘] span::text").ext ...: ract() In [52]: comment_num Out[52]: [‘ 7 評論‘] In [53]: comment_num = response.css("a[href=‘#article-comment‘] span::text").ext ...: ract().strip() --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-53-18ae8761867f> in <module>() ----> 1 comment_num = response.css("a[href=‘#article-comment‘] span::text").extract().strip() AttributeError: ‘list‘ object has no attribute ‘strip‘ In [54]: comment_num = response.css("a[href=‘#article-comment‘] span::text").ext ...: ract()[0] In [55]: comment_num Out[55]: ‘ 7 評論‘ In [56]:View Code
PS:css選擇器裏,不同標簽使用空格隔開
第七篇 css選擇器實現字段解析