
個人作業-Week 2 代碼復審
一.概要部分
1.代碼能符合需求和規格說明麽?
經過我自己的測試和助教的檢測,他的代碼符合需求和規格的說明。
2.代碼設計是否有周全的考慮?
這裏代碼設計我們是從兩個方面檢查的:
- 對方處理控制臺輸入的邏輯是不是考慮全面:
經過我的分析和他的解釋,我可以得到他的處理控制臺輸入的邏輯是這樣的:
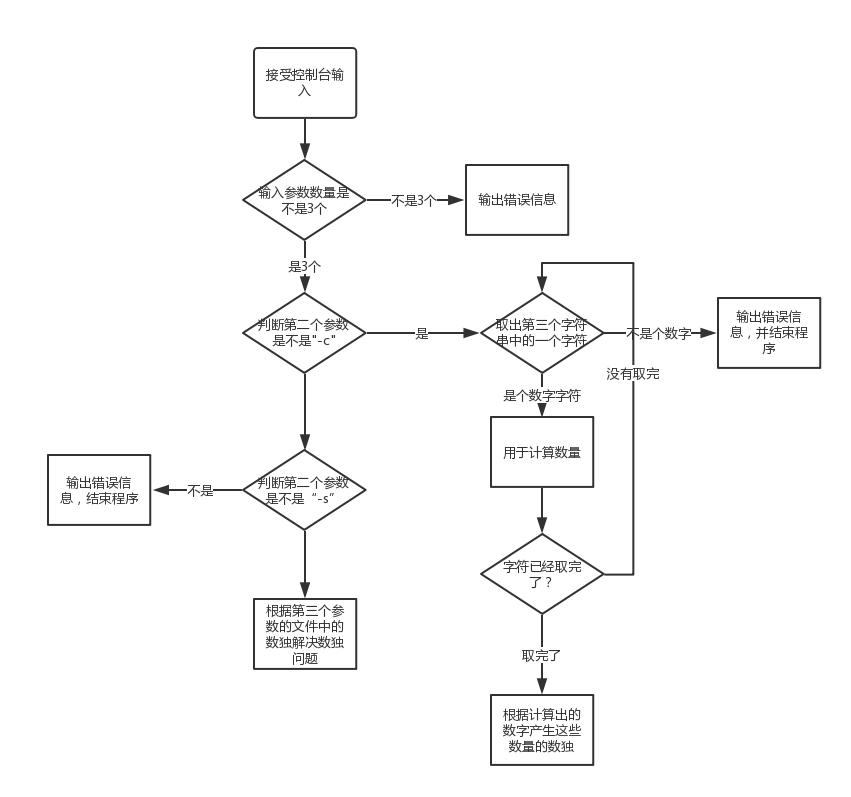
畫了邏輯圖就可以看出處理輸入的這部分大致判斷邏輯已經很完備了,還可以再更完備:
輸入的數字的範圍處理:對於輸入的生成數獨的數量,規定是N範圍在1到100萬之間,但是上面的邏輯並沒有對輸入的數字字符串做這方面的可能超出範圍的檢測。比如對於一段超長的數字字符串,超過了最大int的範圍,這時就會產生錯誤。
- 可擴展性怎樣?
較好的可擴展性需要代碼模塊之間的松耦合,模塊內部的高聚合。在這次的作業中,我覺得大致可以分為這麽幾個大的模塊:命令行參數處理模塊,數獨生成模塊,數獨解決模塊,最後的結果寫入模塊。
經過仔細的檢查,覺得我們在這方面的實現還不太完善,因為:
1.並沒有把命令行參數處理模塊化,而是直接把數獨生成和數獨解決這兩個過程寫在了main函數的if else邏輯中。這樣命令行參數這個處理過程與數獨的生成和解決耦合性過大。
2.最後文件的寫入沒有和數獨生成/解決分開。
所以這裏我們都需要改進。
3.代碼可讀性如何?
總體來講,我覺得他的代碼滿足簡明,易讀,無二義性的基本原則。我從兩個方面評判他的代碼可讀性:
- 命名規範:
我覺得他的代碼命名簡潔明了:
例如:
int val, pos_row, pos_col;
整體上都是采用單詞和單詞之間加下劃線的表示方法。
- 單詞與單詞之間的空隙:
他的縮進讓代碼整體上看起來很舒服,例如:
A = new cross_link(rownum, colnum); rows = A->rows; cols = A->cols; head = A->head; for (int i = 0; i < rownum; i++) { int val = i % 9 + 1; int pos = i / 9; int row = pos / 9; int col = pos % 9; int block = (row / 3) * 3 + (col / 3); A->insert(i, pos); A->insert(i, 81 + row * 9 + val - 1); A->insert(i, 81 * 2 + col * 9 + val - 1); A->insert(i, 81 * 3 + block * 9 + val - 1); }
還有其他的分行,括號等用的都很好,但是有個缺點我覺的就是註釋太少。
4.代碼容易維護麽?
因為之前說的封裝性不夠,註釋少,所以我覺得代碼的可維護性還不夠,還需要加強。
二.設計規範部分
1.設計是否遵從已知的設計模式或項目中常用的模式?
目前因為完成的功能較少,所以還沒有用到特別明顯的設計模式。
2.有沒有硬編碼或字符串/數字等存在?
還是有一些硬編碼的存在的,例如:
- 左上角數字題目要求固定,但是我覺得需要使用特別的常量標識符來代替它
rstr[0][0] = 3;
- 最後寫入文件時,必須要先計算好每一行所需要寫的字符數19,我覺得這個數字也可以用更明白的方式表示出來
str[i * 19 + 2 * j + 1] = ‘ ‘;
3.代碼有沒有依賴於某一平臺,是否會影響將來的移植(如Win32到Win64)?
根據我和他的討論,應該對平臺沒有依賴性。
4.開發者新寫的代碼能否用已有的Library/SDK/Framework中的功能實現?在本項目中是否存在類似的功能可以調用而不用全部重新實現?
根據交流和檢查的結果,在他的代碼中沒有這樣的可以直接調用庫函數的功能。
5.有沒有無用的代碼可以清除?
確實還有一些無用代碼是可以清除的。
三.具體代碼部分
1.有沒有對錯誤進行處理?對於調用的外部函數,是否檢查了返回值或處理了異常?
目前還沒有調用外部的函數,所以還沒有這方面的檢查。而且目前還沒有太多的錯誤處理,只有在main函數中的命令行參數處的錯誤處理。
2.參數傳遞有無錯誤,字符串的長度是字節的長度還是字符(可能是單/雙字節)的長度,是以0開始計數還是以1開始計數?
參數傳遞目前檢查結果來看沒有錯誤,字符串的長度是單字節。
3.邊界條件是如何處理的?Switch語句的Default是如何處理的?循環有沒有可能出現死循環?
- 代碼中沒有發現switch語句
- 邊界條件在他的代碼中有這麽幾處,①鏈表的結尾,我查看了都加了不為NULL的判斷②數獨本身9*9的限制,也都處理的很好
- 對於他的每個for循環,首先我可以確定他的每一個循環的循環變量在循環體的執行中都不會改變,這樣循環變量的改變只有for()的變化了,然後我可以確定他的循環終止條件都是正確的,所以不可能出現死循環
- 對於他在讀文件時用的while循環,使用的判斷條件是:getline函數的返回值。getline函數在讀到文件結尾時,會返回false,不會出現死循環。
4.有沒有使用斷言(Assert)來保證我們認為不變的條件真的滿足?
經過檢查,代碼中沒有斷言。
5.對資源的利用,是在哪裏申請,在哪裏釋放的?有沒有可能導致資源泄露(內存、文件、各種GUI資源、數據庫訪問的連接,等等)?有沒有可能優化?
檢查了他的代碼中的資源申請,有這麽幾處
- 文件流的打開和結束。檢查發現他的寫入文件流最後沒有close,數獨解決時讀入題目的文件流也沒有close。
- 對於cross_link對象(具體的數據結構)和dlx對象(解數獨和生成數獨的對象),在析構函數中都定義好了相應的釋放資源的邏輯。所以這裏沒有問題。
6.數據結構中是否有無用的元素?
經過細致的檢查,他的代碼中的數據結構只有這個;
typedef struct cross_node { cross_node *left; cross_node *right; cross_node *up; cross_node *down; bool ishead; int count; int row; int col; } *Cross;
其中包括四個方向上的指針,這個是有用的;
還有是否為頭指針的判斷ishead,這個也是有用的;
count成員是對於頭結點來說的,頭結點需要記錄這一行或者這一列有多少個有效節點,這個也是有用的;
row,col表示節點所在的行,列。
綜上,數據結構都是有用的,可能count只對於頭結點有用,對非頭結點無用,有點冗余。但是如果不同意寫起來的話,可能需要定義兩種數據結構了,所以還是統一寫起來會實現的更好吧。
四.效能
1.代碼的效能(Performance)如何?最壞的情況是怎樣的?
DLX算法本質上也是遞歸回溯的算法,所以最壞的情況可能是對於一些數獨初局,回溯搜索太多。因為搜索是按照一定的順序比如1-9來搜索的,所以固定的搜索順序可能導致找到解之前已經回溯了大量的分支了。
2.代碼中,特別是循環中是否有明顯可優化的部分(C++中反復創建類,C#中string的操作是否能用StringBuilder 來優化)?
經過檢查,他的代碼中沒有反復創建類這個過程,無論是數獨的解決和生成都是只創建一個類。
3.對於系統和網絡調用是否會超時?如何處理?
目前還不涉及系統和網絡的調用。
五.可讀性
1.代碼可讀性如何?有沒有足夠的註釋?
他的代碼確實沒有足夠的註釋,但是命名清晰,可讀性還可以。
六.可測試性
1.代碼是否需要更新或創建新的單元測試?
他實現的單元測試有:
- 生成數獨功能的單元測試
- 解決數獨功能的單元測試
- CrossLink_insert的單元測試
- CrossLink_delAndRecover的單元測試
在代碼更新後,可能會增加一些模塊功能,可以為他們創建新的單元測試。
2.還可以有針對特定領域開發(如數據庫、網頁、多線程等)的核查表。
目前還不涉及特定領域的開發。
七.看了Google C++ Style規範後的心得
因為我使用了c++來編碼,所以我參考了google的C++編碼規範。因為剛接觸C++所以其中有很多規範還沒太看懂,不過也是有很多心得的:
1.工具提供的代碼規範和你個人的代碼風格有什麽不同?
在我能理解的範圍內,google規定的代碼規範和自己的代碼風格有以下不同:
- 規範中倡導“Avoid defining macros, especially in headers; prefer inline functions, enums, and
constvariables.”,不提倡用宏定義我還是第一次聽說,規範中的理由是這樣的:①宏定義會讓你所看到的代碼和編譯器看到的代碼不一致。我覺得就是因為宏在預處理時會被替換,就可能會在替換後導致錯誤吧。②宏定義是全局的,這和C++一直倡導的命名空間有沖突,一般對於常量的宏定義用const來代替,函數用inline來代替。我在C中定義常量時喜歡用宏,看了這個規範我是很驚訝的,也許是沒接觸很大的工程吧,還沒有遇到規範上說的宏定義的缺陷。不過既然規範這樣說了,那麽以後就盡量用常量和內聯函數來代替宏定義吧。 - 常量定義在google的規範中是以k開頭的,之後是每個單詞的第一個字母大寫
- 之前我在定義成員變量時,命名時前面加m_,這裏google規範定義的是名字後加_
2.工具提供的代碼規範裏有哪些部分是你之前沒有想到的?
有很多我都沒有想到,除了上面說的那幾個規範,還有這些規範我之前是不了解的:
- 變量的聲明盡可能的置於最小作用域內,並且在變量聲明時就要初始化好。
- 但是有個例外,對於一個對象,因為它在每次進入作用域初始化時都會調用其構造函數,每次退出時都會調用其構析函數,所以如果沒有必要的話,不要重復的初始化一個類,這一點我在自己這次作業中實現的並不太好。
- 傳遞對象的所有權,開銷比copy一下來的少
- 所有按引用傳遞的參數在函數參數定義時必須加上const,這個規範可以保證在函數中不會對這個引用修改,其實本來引用就是不能修改的。
- 前置自增即++i比後置自增i++效率高,在不考慮返回值時,還是用++i吧,比如在一些循環中
- 最好使用C++的自己的類型轉換方法
上面都是我能看懂的規範中對我有幫助的。
八.代碼規範整理
1.代碼風格規範整理
- 縮進以及不同單詞之間的空隙完全由VS工具自動調整的結果為準
- 命名:(1)類型命名首字母大寫,不含下劃線(2)變量命名一律小寫,單詞之間用_連接,類的成員變量最後加_(3)常量以k開頭,首字母大寫不加下劃線(4)常規函數使用大小寫混合, 取值和設值函數則要求與變量名匹配(5)特殊的命名再做商議
- 註釋:(1)盡量為每個類都寫一份註釋聲明(2)為復雜函數前加上註釋聲明(3)註釋要上下對齊
2.代碼設計規範整理
- 不用goto語句
- 盡可能的把清理工作放在析構函數中
- 構造函數盡可能的簡短
- 僅在必要時再使用類的繼承
個人作業-Week 2 代碼復審