
Redis集群方案收集
說明:
如果不考慮客戶端分片去實現集群,那麽市面上基本可以說就三種方案最成熟,它們分別如下所示:
| 系統 | 貢獻者 | 是否官方Redis實現 | 編程語言 |
| Twemproxy | 是 | C | |
| Redis Cluster | Redis官方 | 是 | C |
| Codis | 豌豆莢 | 否 | Go+C |
使用總結:
Twemprosy:
- 輕量級
- 在Proxy層實現一致性哈希
- 快速的故障節點移除
- 可借助Sentinel和重啟工具降低故障節點移除時的Cache失配
Redis Cluster:
- 無中心自組織結構
- 更強的功能:主備平衡
- 故障轉移響應時間長
- 已經發布了正式版,且基於P2P網絡實現無主模式,可以嘗試。
Codis:
- 基於Zookeeper的Proxy高可用
- 非官方Redis實現
- 側重於動態水平擴容
- 手動故障轉移
- 由於基於ZK做為額外部署,無意會將部署運維成本增加,需要慎重考慮
下面將詳細介紹這些集群實現的特點:
由於Redis出眾的性能,其在眾多的移動互聯網企業中得到廣泛的應用。Redis在3.0版本前只支持單實例模式,雖然現在的服務器內存可以到100GB、200GB的規模,但是單實例模式限制了Redis沒法滿足業務的需求(例如新浪微博就曾經用Redis存儲了超過1TB的數據)。Redis的開發者Antirez早在博客上就提出在Redis 3.0版本中加入集群的功能,但3.0版本等到2015年才發布正式版。各大企業在3.0版本還沒發布前為了解決Redis的存儲瓶頸,紛紛推出了各自的Redis集群方案。這些方案的核心思想是把數據分片(sharding)存儲在多個Redis實例中,每一片就是一個Redis實例。
1、客戶端分片
客戶端分片是把分片的邏輯放在Redis客戶端實現,通過Redis客戶端預先定義好的路由規則,把對Key的訪問轉發到不同的Redis實例中,最後把返回結果匯集。這種方案的模式如圖所示。
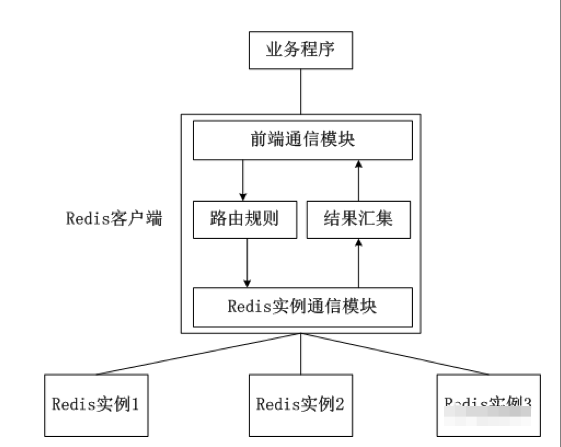
客戶端分片的好處是所有的邏輯都是可控的,不依賴於第三方分布式中間件。開發人員清楚怎麽實現分片、路由的規則,不用擔心踩坑。
客戶端分片方案有下面這些缺點。
-
這是一種靜態的分片方案,需要增加或者減少Redis實例的數量,需要手工調整分片的程序。
-
可運維性差,集群的數據出了任何問題都需要運維人員和開發人員一起合作,減緩了解決問題的速度,增加了跨部門溝通的成本。
-
在不同的客戶端程序中,維護相同的分片邏輯成本巨大。例如,系統中有兩套業務系統共用一套Redis集群,一套業務系統用Java實現,另一套業務系統用PHP實現。為了保證分片邏輯的一致性,在Java客戶端中實現的分片邏輯也需要在PHP客戶端實現一次。相同的邏輯在不同的系統中分別實現,這種設計本來就非常糟糕,而且需要耗費巨大的開發成本保證兩套業務系統分片邏輯的一致性。
2、Twemproxy
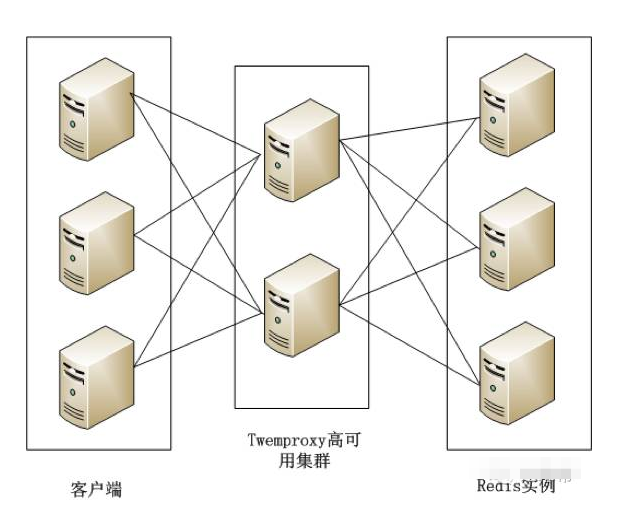
Twemproxy是由Twitter開源的Redis代理,其基本原理是:Redis客戶端把請求發送到Twemproxy,Twemproxy根據路由規則發送到正確的Redis實例,最後Twemproxy把結果匯集返回給客戶端。
Twemproxy通過引入一個代理層,將多個Redis實例進行統一管理,使Redis客戶端只需要在Twemproxy上進行操作,而不需要關心後面有多少個Redis實例,從而實現了Redis集群。
Twemproxy集群架構如圖所示。
Twemproxy的優點如下。
-
客戶端像連接Redis實例一樣連接Twemproxy,不需要改任何的代碼邏輯。
-
支持無效Redis實例的自動刪除。
-
Twemproxy與Redis實例保持連接,減少了客戶端與Redis實例的連接數。
Twemproxy有如下不足。
-
由於Redis客戶端的每個請求都經過Twemproxy代理才能到達Redis服務器,這個過程中會產生性能損失。
-
沒有友好的監控管理後臺界面,不利於運維監控。
-
最大的問題是Twemproxy無法平滑地增加Redis實例。對於運維人員來說,當因為業務需要增加Redis實例時工作量非常大。
Twemproxy作為最被廣泛使用、最久經考驗、穩定性最高的Redis代理,在業界被廣泛使用。
3、Codis
Twemproxy不能平滑增加Redis實例的問題帶來了很大的不便,於是豌豆莢自主研發了Codis,一個支持平滑增加Redis實例的Redis代理軟件,其基於Go和C語言開發,並於2014年11月在GitHub上開源。
Codis包含下面4個部分。
-
Codis Proxy:Redis客戶端連接到Redis實例的代理,實現了Redis的協議,Redis客戶端連接到Codis Proxy進行各種操作。Codis Proxy是無狀態的,可以用Keepalived等負載均衡軟件部署多個Codis Proxy實現高可用。
-
CodisRedis:Codis項目維護的Redis分支,添加了slot和原子的數據遷移命令。Codis上層的 Codis Proxy和Codisconfig只有與這個版本的Redis通信才能正常運行。
-
Codisconfig:Codis管理工具。可以執行添加刪除CodisRedis節點、添加刪除Codis Proxy、數據遷移等操作。另外,Codisconfig自帶了HTTP server,裏面集成了一個管理界面,方便運維人員觀察Codis集群的狀態和進行相關的操作,極大提高了運維的方便性,彌補了Twemproxy的缺點。
-
ZooKeeper:分布式的、開源的應用程序協調服務,是Hadoop和Hbase的重要組件,其為分布式應用提供一致性服務,提供的功能包括:配置維護、名字服務、分布式同步、組服務等。Codis依賴於ZooKeeper存儲數據路由表的信息和Codis Proxy節點的元信息。另外,Codisconfig發起的命令都會通過ZooKeeper同步到CodisProxy的節點。
Codis的架構如圖所示。
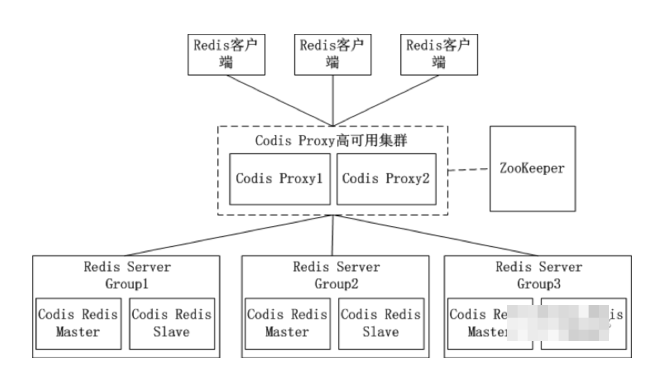
在Codis的架構圖中,Codis引入了Redis Server Group,其通過指定一個主CodisRedis和一個或多個從CodisRedis,實現了Redis集群的高可用。當一個主CodisRedis掛掉時,Codis不會自動把一個從CodisRedis提升為主CodisRedis,這涉及數據的一致性問題(Redis本身的數據同步是采用主從異步復制,當數據在主CodisRedis寫入成功時,從CodisRedis是否已讀入這個數據是沒法保證的),需要管理員在管理界面上手動把從CodisRedis提升為主CodisRedis。
如果覺得麻煩,豌豆莢也提供了一個工具Codis-ha,這個工具會在檢測到主CodisRedis掛掉的時候將其下線並提升一個從CodisRedis為主CodisRedis。
Codis中采用預分片的形式,啟動的時候就創建了1024個slot,1個slot相當於1個箱子,每個箱子有固定的編號,範圍是1~1024。slot這個箱子用作存放Key,至於Key存放到哪個箱子,可以通過算法“crc32(key)%1024”獲得一個數字,這個數字的範圍一定是1~1024之間,Key就放到這個數字對應的slot。例如,如果某個Key通過算法“crc32(key)%1024”得到的數字是5,就放到編碼為5的slot(箱子)。1個slot只能放1個Redis Server Group,不能把1個slot放到多個Redis Server Group中。1個Redis Server Group最少可以存放1個slot,最大可以存放1024個slot。因此,Codis中最多可以指定1024個Redis Server Group。
Codis最大的優勢在於支持平滑增加(減少)Redis Server Group(Redis實例),能安全、透明地遷移數據,這也是Codis 有別於Twemproxy等靜態分布式 Redis 解決方案的地方。Codis增加了Redis Server Group後,就牽涉到slot的遷移問題。例如,系統有兩個Redis Server Group,Redis Server Group和slot的對應關系如下。
|
Redis Server Group |
slot |
|
1 |
1~500 |
|
2 |
501~1024 |
當增加了一個Redis Server Group,slot就要重新分配了。Codis分配slot有兩種方法。
第一種:通過Codis管理工具Codisconfig手動重新分配,指定每個Redis Server Group所對應的slot的範圍,例如可以指定Redis Server Group和slot的新的對應關系如下。
|
Redis Server Group |
slot |
|
1 |
1~500 |
|
2 |
501~700 |
|
3 |
701~1024 |
第二種:通過Codis管理工具Codisconfig的rebalance功能,會自動根據每個Redis Server Group的內存對slot進行遷移,以實現數據的均衡。
4、Redis 3.0集群(截至今天已經發布到4.0了,成熟性可以說是沒什麽問題的了)
Redis 3.0集群采用了P2P的模式,完全去中心化。Redis把所有的Key分成了16384個slot,每個Redis實例負責其中一部分slot。集群中的所有信息(節點、端口、slot等),都通過節點之間定期的數據交換而更新。
Redis客戶端在任意一個Redis實例發出請求,如果所需數據不在該實例中,通過重定向命令引導客戶端訪問所需的實例。
Redis 3.0集群的工作流程如圖所示。
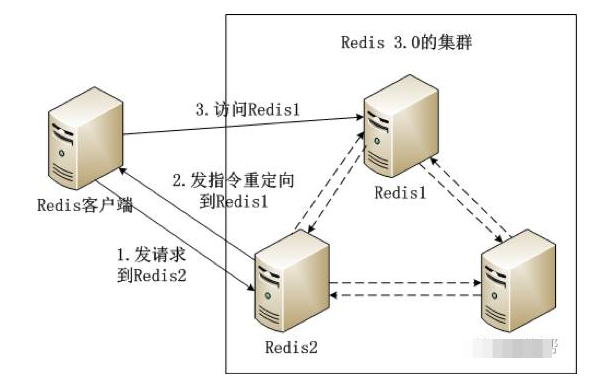
如圖所示Redis集群內的機器定期交換數據,工作流程如下。
(1) Redis客戶端在Redis2實例上訪問某個數據。
(2) 在Redis2內發現這個數據是在Redis3這個實例中,給Redis客戶端發送一個重定向的命令。
(3) Redis客戶端收到重定向命令後,訪問Redis3實例獲取所需的數據。
Redis 3.0的集群方案有以下兩個問題。
-
一個Redis實例具備了“數據存儲”和“路由重定向”,完全去中心化的設計。這帶來的好處是部署非常簡單,直接部署Redis就行,不像Codis有那麽多的組件和依賴。但帶來的問題是很難對業務進行無痛的升級,如果哪天Redis集群出了什麽嚴重的Bug,就只能回滾整個Redis集群。
-
對協議進行了較大的修改,對應的Redis客戶端也需要升級。升級Redis客戶端後誰能確保沒有Bug?而且對於線上已經大規模運行的業務,升級代碼中的Redis客戶端也是一個很麻煩的事情。
綜合上面所述的兩個問題,Redis 3.0集群在業界並沒有被大規模使用。這個是以前的觀點,現在4.0時代已經突破了這個限制。但成熟度還有待業界進行更多成熟案例的分析。
參考:
http://www.sohu.com/a/79200151_354963(以上內容大部分轉自此篇博客,我也買了這本書)
https://linux.cn/article-2076-1.html
http://www.cnblogs.com/verrion/p/redis_structure_type_selection.html
http://ifeve.com/redis-cluster-spec/
https://www.zhihu.com/question/21419897
http://chong-zh.iteye.com/blog/2175166
http://blog.csdn.net/yfkiss/article/details/25688153
http://blog.csdn.net/yfkiss/article/details/38944179
http://www.cnblogs.com/guoyinglin/p/4604279.html
http://www.cnblogs.com/lulu/archive/2013/06/10/3130878.html
http://www.jianshu.com/p/14835303b07e
http://www.infoq.com/cn/news/2014/11/open-source-redis-cache/
http://www.redis.cn/topics/cluster-tutorial.html
Redis集群方案收集