
結對-爬取大麥網近期演唱會信息-開發過程
Github:https://github.com/atinst/Python/tree/master/Damai
開發過程:
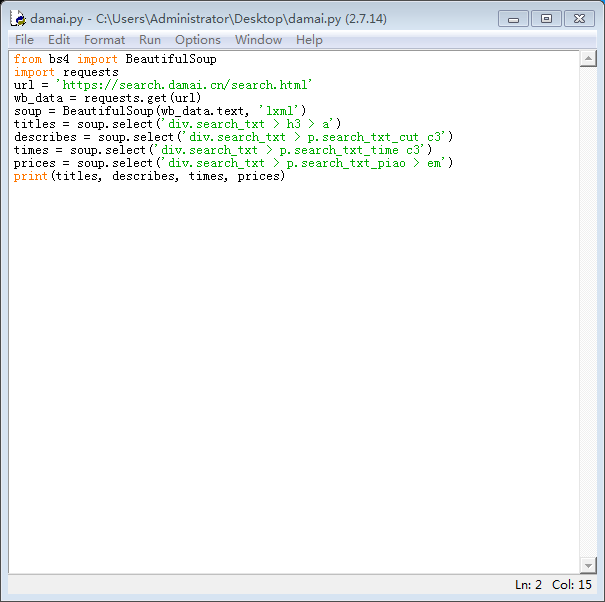
1.根據需求分析,安裝並導入BeautifulSoup和requests模塊
2.對大麥網html代碼進行了分析
3.找到標題、演出時間所在位置並編寫python代碼
4.進行簡單測試,並對程序進行修改
結對-爬取大麥網近期演唱會信息-開發過程
相關推薦
結對-爬取大麥網近期演唱會信息-開發過程
quest 程序 ima ref 時間 -1 git 簡單測試 cnblogs Github:https://github.com/atinst/Python/tree/master/Damai 開發過程:1.根據需求分析,安裝並導入BeautifulSoup和reques
結對-爬取大麥網近期演唱會信息-最終程序
.cn es2017 https png 演唱會 pair ima 技術 img 結對成員:閻大為,張躍馨學號:2015035107201學號:2015035107219 項目托管平臺地址:https://github.com/atinst/Pair-programming
結對-爬取大麥網演唱會信息-設計文檔
.com ref lock beautiful 模塊 有用 pytho spa pil 結對編程成員:閻大為,張躍馨 搭建環境: ?1.安裝python2.7 ?2.安裝beautifulsoup4等相關模塊 編寫程序階段: ?1.分析html代碼以及了解相
amazon爬取亞馬遜頁面信息
爬蟲 pyton代碼:# -*- coding: cp936 -*-import requestsfrom lxml import etreeASIN = ‘B00X4WHP5E‘#ASIN = ‘B017R1YFEG‘url = ‘https://www.amazon.com/dp/‘+ASINr = re
用scrapy爬取京東商城的商品信息
keywords XML 1.5 rom toc ons lines open 3.6 軟件環境: 1 gevent (1.2.2) 2 greenlet (0.4.12) 3 lxml (4.1.1) 4 pymongo (3.6.0) 5 pyO
利用 Scrapy 爬取知乎用戶信息
oauth fault urn family add token post mod lock 思路:通過獲取知乎某個大V的關註列表和被關註列表,查看該大V和其關註用戶和被關註用戶的詳細信息,然後通過層層遞歸調用,實現獲取關註用戶和被關註用戶的關註列表和被關註列表,最終實
爬取餓了麽商鋪信息
home AD lan term str ping CA orien 感受 分析: 當我們訪問https://www.ele.me/home/時,看看我們得到了什麽 1.png 我們發現所有的城市名稱和他的經緯度,還有一個風流的
使用selenium 多線程爬取愛奇藝電影信息
連接 獲取 ict 容易出錯 span column 分享圖片 odi attribute 使用selenium 多線程爬取愛奇藝電影信息 轉載請註明出處。 爬取目標:每個電影的評分、名稱、時長、主演、和類型 爬取思路: 源文件:(有註釋) from seleniu
我的第一個爬蟲,爬取北京地區短租房信息
爬取 connect except links 效率 chrom cti clas 爬蟲 # 導入程序所需要的庫。import requestsfrom bs4 import BeautifulSoupimport time# 加入請求頭偽裝成瀏覽器headers = {
python3爬蟲 -----爬取百思不得姐信息-------http://www.budejie.com/
chrom tree www cti mozilla from tar 2-0 sum 1 # -*- coding:utf-8 -*- 2 # author:zxy 3 # Date:2018-10-21 4 5 import request 6 from
<scrapy爬蟲>爬取騰訊社招信息
extra rul topic osi .org 接收 處理 += doc 1.創建scrapy項目 dos窗口輸入: scrapy startproject tencent cd tencent 2.編寫item.py文件(相當於編寫模板,需要爬取的數據在這裏
最簡單的網絡圖片的爬取 --Pyhon網絡爬蟲與信息獲取
文件 spa lose man spl roo () pen image 1、本次要爬取的圖片url http://www.nxl123.cn/static/imgs/php.jpg 2、代碼部分 import requestsimport osurl = "ht
Python爬蟲項目--爬取自如網房源信息
xml解析 quest chrom 當前 b2b cal 源代碼 headers 判斷 本次爬取自如網房源信息所用到的知識點: 1. requests get請求 2. lxml解析html 3. Xpath 4. MongoDB存儲 正文 1.分析目標站點 1. url:
知網摘要作者資訊爬取和搜狗微信、搜狗新聞的爬蟲
個人專案,只支援python3. 需要說明的是,本文中介紹的都是小規模資料的爬蟲(資料量<1G),大規模爬取需要會更復雜,本文不涉及這一塊。另外,程式碼細節就不過多說了,只將一個大概思路以及趟過的
用crawl spider爬取起點網小說信息
models anti arc pub work 全部 see 效率 rand 起點作為主流的小說網站,在防止數據采集反面還是做了準備的,其對主要的數字采用了自定義的編碼映射取值,想直接通過頁面來實現數據的獲取,是無法實現的。 單獨獲取數字還是可以實現的,通過reques
scrapy實戰1分布式爬取有緣網:
req 年齡 dict ems arch last rem pen war 直接上代碼: items.py 1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items
多線程版爬取故事網
實現 exe don comm value obj nco result nic 前言:為了能以更高效的速度爬取,嘗試采用了多線程本博客參照代碼及PROJECT來源:http://kexue.fm/archives/4385/ 源代碼: 1 #! -*- cod
Python爬取天氣網歷史天氣數據
ast 信息 爬蟲 cmake tex for roc ins fonts 使用Python的requests 和BeautifulSoup模塊,Python 2.7.12可在命令行中直接使用pip進行模塊安裝。爬蟲的核心是利用BeautifulSoup的select語句獲
爬取豆瓣網評論最多的書籍
ups info 程序 不容易 ima nta 單元 bs4 很多 相信很多人都有書荒的時候,想要找到一本合適的書籍確實不容易,所以這次利用剛學習到的知識爬取豆瓣網的各類書籍,傳送門https://book.douban.com/tag/?view=cloud。 首先是這個
Python爬取全書網小說,免費看小說
tle 3.6 tro con fin 保存 get 正在 url地址 什麽是網絡爬蟲 網絡爬蟲(又被稱為網頁蜘蛛,網絡機器人,在FOAF社區中間,更經常的稱為網頁追逐者),是一種按照一定的規則,自動地抓取萬維網信息的程序或者腳本。另外一些不常使用的名字還有螞蟻、自