
python實現查有道詞典
阿新 • • 發佈:2017-10-05
int 會有 都是 不同 正則 down 利用 list 指向
因為要考英語四級,所以我今天一大早就起來被英語單詞,但是作為英語渣渣的我,只能是在網頁上挨個查單詞的意思。查的多了,心生厭倦,便想著如何才能在終端下查單詞,那樣速度不就很快了?
NOW,我仔細觀察每次查詢時,瀏覽器地址欄中URL的變化,發現每次瀏覽器提交的URL都是"http://www.youdao.com/w/eng/"xxxxx"/#keyfrom=dict2.index"(其中的xxxxx代表要查的單詞),有了這個發現,那我們將URL指向的網頁下載下來,然後提取我們需要的信息不就得了?
emmmm,這個工作交給Python來做是最合適不過的了
基本步驟:導入requests模塊與re模塊,首先將URL地址指向的網頁下載下來,然後利用Python強大的正則表達式提取單詞經過翻譯後的信息。因為要英漢互譯,所以我寫了兩段代碼,第一個是漢譯英,第二個是英譯漢。
源代碼
漢譯英:
import requests,re
def download(): word=input("請輸入您要翻譯的中文詞語:\n") url="http://dict.youdao.com/w/eng/"+word+"/#keyfrom=dict2.index" #合並URL地址 html=requests.get(url).content.decode(‘utf-8‘) #得到服務器的相應信息後將其轉碼為UTF-8 return html def analysis(): list1=re.findall("詳細釋義.+<p class=\"collapse-content\">",download(),re.S) #這裏對html字符串進行第一步加工,截取大概的信息 list2=re.findall(" [a-zA-Z ]+",str(list1)) #將上面加工後的字符串進一步加工,直接提取到所有翻譯後的單詞信息 print("翻譯結果:\n") for i in list2: i=i.strip() #因為第二步加工後的信息並不幹凈,得到的單詞前面會有空格,這裏將空格刪去 print(i) if __name__ == ‘__main__‘: while(1):
analysis()
英譯漢:
import requests,re def download(): word=input("請輸入您要翻譯的英文單詞:\n") url="http://dict.youdao.com/w/eng/"+word+"/#keyfrom=dict2.index" html=requests.get(url).content.decode(‘utf-8‘) return html def analysis(): list1=re.findall("詳細釋義.+<p class=\"collapse-content\">",download(),re.S) list2=re.findall(" \w+",str(list1)) #只有此處代碼與漢譯英代碼不同,因為是提取漢字,所以這裏要用\w來匹配漢字 print("翻譯結果:\n") for i in list2: i=i.strip() print(i) if __name__ == ‘__main__‘:
while(1):
analysis()
OK,來看看效果吧:
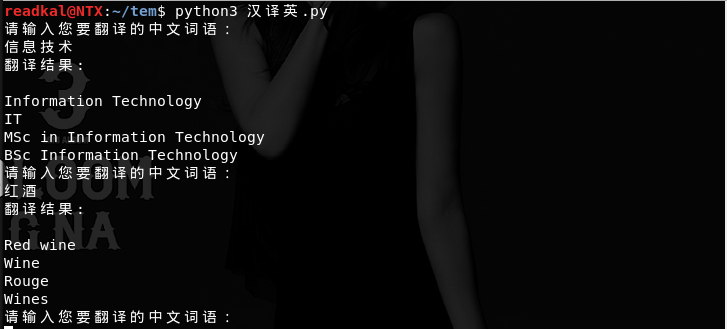

emmmm,OK,發完博客還要繼續背單詞【傷心】【傷心】【傷心】
python實現查有道詞典