
數據庫知識
阿新 • • 發佈:2017-10-09
rul doc 記得 數據庫操作 png 源文件 use 標準 最好 這個是我工作中總結的一些當時不懂的問題,當初記在百度雲筆記,覺得這個還是值得分享一下的,因為是給自己看的,可能比較亂一點,但還是很值得一看的,百度雲裏面還有其他的很多筆記,到時候可能也會看看再繼續分享
數據庫知識大概網址:
http://www.w3school.com.cn/sql/sql_join_left.asp
如下圖那個就是可以直接回到登錄界面的:連接對象資源管理器
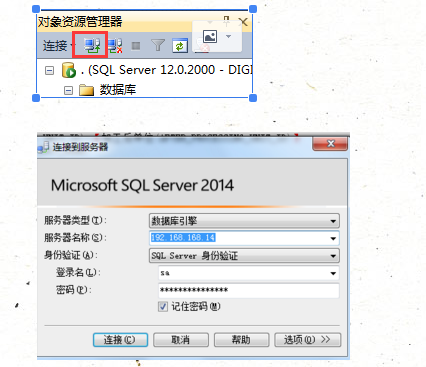 修改sa的密碼:
可以先用window登進去之後安全性中的sa點屬性就可以改密碼,而且每一個網址對應的sa其實是不一樣的,也就是說這些密碼也是不一樣的
而且可以同時連接好幾個數據庫的呢,點完這個之後就會又多一個數據庫,也是可以相互切換操作的
SQL 對大小寫不敏感!裏面是不需要進行分號隔開的,裏面分為DDL(數據庫定義語言)和DML(數據庫操作語言),數據庫定義語言主要包括:創建數據庫,表以及索引,修改這三個以及刪除(create,drop,alter),數據庫操作語言就是包括增刪改查
create index:
增加索引的好處就是 首先明白為什麽索引會增加速度,DB在執行一條Sql語句的時候,默認的方式是根據搜索條件進行全表掃描,遇到匹配條件的就加入搜索結果集合。如果我們對某一字段增加索引,查詢時就會先去索引列表中一次定位到特定值的行數,大大減少遍歷匹配的行數,所以能明顯增加查詢的速度。那麽在任何時候都應該加索引麽?這裏有幾個反例:1、如果每次都需要取到所有表記錄,無論如何都必須進行全表掃描了,那麽是否加索引也沒有意義了。2、對非唯一的字段,例如“性別”這種大量重復值的字段,增加索引也沒有什麽意義。3、對於記錄比較少的表,增加索引不會帶來速度的優化反而浪費了存儲空間,因為索引是需要存儲空間的,而且有個致命缺點是對於update/insert/delete的每次執行,字段的索引都必須重新計算更新。 那麽在什麽時候適合加上索引呢?我們看一個Mysql手冊中舉的例子,這裏有一條sql語句: SELECT c.companyID, c.companyName FROM Companies c, User u WHERE c.companyID = u.fk_companyID AND c.numEmployees >= 0 AND c.companyName LIKE ‘%i%‘ AND u.groupID IN (SELECT g.groupID FROM Groups g WHERE g.groupLabel = ‘Executive‘) 這條語句涉及3個表的聯接,並且包括了許多搜索條件比如大小比較,Like匹配等。在沒有索引的情況下Mysql需要執行的掃描行數是77721876行。而我們通過在companyID和groupLabel兩個字段上加上索引之後,掃描的行數只需要134行。在Mysql中可以通過Explain Select來查看掃描次數。可以看出來在這種聯表和復雜搜索條件的情況下,索引帶來的性能提升遠比它所占據的磁盤空間要重要得多。
create table person(id int identity(1,1))或者id int primary key identity(1,1)
alter table person add id int identity(1,1) [表示從1開的之後每次都自增長1]
CASE WHEN:
SELECT SUM(population),
CASE country WHEN ‘中國‘ THEN ‘亞洲‘
WHEN ‘印度‘ THEN ‘亞洲‘
WHEN ‘日本‘ THEN ‘亞洲‘
WHEN ‘美國‘ THEN ‘北美洲‘
WHEN ‘加拿大‘ THEN ‘北美洲‘
WHEN ‘墨西哥‘ THEN ‘北美洲‘
ELSE ‘其他‘ END
CASE WHEN salary <= 500 THEN ‘1‘
WHEN salary > 500 AND salary <= 600 THEN ‘2‘
WHEN salary > 600 AND salary <= 800 THEN ‘3‘
WHEN salary > 800 AND salary <= 1000 THEN ‘4‘
ELSE NULL END;
UPDATE XPALLET SET STOCK_STATUS CASE When STOCK_STATUS<>‘0‘ THEN ‘0‘ END
以後批量更新記得要直接在下面弄一個集合然後在上面應用,還有一個不要隨便用static這個關鍵字要考慮寫一個方法來進行查詢
UPDATE [MO_ROUTING] SET [XREM_DATE1]=‘2017-08-24‘,[XC0LOR_WARNING]=N‘4‘
FROM (SELECT [MO_ROUTING].[MO_ROUTING_ID]
FROM [MO_ROUTING] AS [MO_ROUTING]
WHERE [MO_ROUTING].[MO_ROUTING_ID] IN (‘0794EBE8-DA28-477A-3DA5- 11919AC17B9E‘,‘59119A86-743B-4996-83CD-11919AC1E20C‘,‘715BFA76-1F3A-4712-612C-11919AC218D6‘)) AS subNode
WHERE [MO_ROUTING].[MO_ROUTING_ID] = [subNode].[MO_ROUTING_ID]
一定要記得寫別名,這樣的會簡潔很多:
SELECT A.ITEM_ID ,
A.ITEM_FEATURE_ID ,
A.WAREHOUSE_ID ,
A.BIN_ID ,
A.ITEM_LOT_ID ,
A.INVENTORY_QTY ,
A.SECOND_QTY
FROM ITEM_WAREHOUSE_BIN AS A
LEFT JOIN ISSUE_RECEIPT_D AS B ON A.ITEM_ID = B.ITEM_ID
AND A.ITEM_FEATURE_ID = B.ITEM_FEATURE_ID
AND A.WAREHOUSE_ID = B.WAREHOUSE_ID
AND A.BIN_ID = B.BIN_ID
AND A.ITEM_LOT_ID = B.ITEM_LOT_ID
AND A.INVENTORY_QTY > 0
AND A.SECOND_QTY > 0
LEFT JOIN ISSUE_RECEIPT AS C ON A.Owner_Org_ROid = C.Owner_Org_ROid;
攔截的地址:
就是說在攔截數據庫的時候就是當你用的是哪個地址的時候就用哪一個地址,比如說你用的是公司的就是公司的地址,你用本地就本地的地址
以後代碼的修改一定要修改一個類之後就立馬調試一下,不然返回修改會特別難受
一定要記得前面如果關聯的時候有給表取別名的話一定要記得在後面一樣也要用別名
上面那個是界面上的字段,下面是更新數據庫裏面的
修改sa的密碼:
可以先用window登進去之後安全性中的sa點屬性就可以改密碼,而且每一個網址對應的sa其實是不一樣的,也就是說這些密碼也是不一樣的
而且可以同時連接好幾個數據庫的呢,點完這個之後就會又多一個數據庫,也是可以相互切換操作的
SQL 對大小寫不敏感!裏面是不需要進行分號隔開的,裏面分為DDL(數據庫定義語言)和DML(數據庫操作語言),數據庫定義語言主要包括:創建數據庫,表以及索引,修改這三個以及刪除(create,drop,alter),數據庫操作語言就是包括增刪改查
create index:
增加索引的好處就是 首先明白為什麽索引會增加速度,DB在執行一條Sql語句的時候,默認的方式是根據搜索條件進行全表掃描,遇到匹配條件的就加入搜索結果集合。如果我們對某一字段增加索引,查詢時就會先去索引列表中一次定位到特定值的行數,大大減少遍歷匹配的行數,所以能明顯增加查詢的速度。那麽在任何時候都應該加索引麽?這裏有幾個反例:1、如果每次都需要取到所有表記錄,無論如何都必須進行全表掃描了,那麽是否加索引也沒有意義了。2、對非唯一的字段,例如“性別”這種大量重復值的字段,增加索引也沒有什麽意義。3、對於記錄比較少的表,增加索引不會帶來速度的優化反而浪費了存儲空間,因為索引是需要存儲空間的,而且有個致命缺點是對於update/insert/delete的每次執行,字段的索引都必須重新計算更新。 那麽在什麽時候適合加上索引呢?我們看一個Mysql手冊中舉的例子,這裏有一條sql語句: SELECT c.companyID, c.companyName FROM Companies c, User u WHERE c.companyID = u.fk_companyID AND c.numEmployees >= 0 AND c.companyName LIKE ‘%i%‘ AND u.groupID IN (SELECT g.groupID FROM Groups g WHERE g.groupLabel = ‘Executive‘) 這條語句涉及3個表的聯接,並且包括了許多搜索條件比如大小比較,Like匹配等。在沒有索引的情況下Mysql需要執行的掃描行數是77721876行。而我們通過在companyID和groupLabel兩個字段上加上索引之後,掃描的行數只需要134行。在Mysql中可以通過Explain Select來查看掃描次數。可以看出來在這種聯表和復雜搜索條件的情況下,索引帶來的性能提升遠比它所占據的磁盤空間要重要得多。
create table person(id int identity(1,1))或者id int primary key identity(1,1)
alter table person add id int identity(1,1) [表示從1開的之後每次都自增長1]
CASE WHEN:
SELECT SUM(population),
CASE country WHEN ‘中國‘ THEN ‘亞洲‘
WHEN ‘印度‘ THEN ‘亞洲‘
WHEN ‘日本‘ THEN ‘亞洲‘
WHEN ‘美國‘ THEN ‘北美洲‘
WHEN ‘加拿大‘ THEN ‘北美洲‘
WHEN ‘墨西哥‘ THEN ‘北美洲‘
ELSE ‘其他‘ END
CASE WHEN salary <= 500 THEN ‘1‘
WHEN salary > 500 AND salary <= 600 THEN ‘2‘
WHEN salary > 600 AND salary <= 800 THEN ‘3‘
WHEN salary > 800 AND salary <= 1000 THEN ‘4‘
ELSE NULL END;
UPDATE XPALLET SET STOCK_STATUS CASE When STOCK_STATUS<>‘0‘ THEN ‘0‘ END
以後批量更新記得要直接在下面弄一個集合然後在上面應用,還有一個不要隨便用static這個關鍵字要考慮寫一個方法來進行查詢
UPDATE [MO_ROUTING] SET [XREM_DATE1]=‘2017-08-24‘,[XC0LOR_WARNING]=N‘4‘
FROM (SELECT [MO_ROUTING].[MO_ROUTING_ID]
FROM [MO_ROUTING] AS [MO_ROUTING]
WHERE [MO_ROUTING].[MO_ROUTING_ID] IN (‘0794EBE8-DA28-477A-3DA5- 11919AC17B9E‘,‘59119A86-743B-4996-83CD-11919AC1E20C‘,‘715BFA76-1F3A-4712-612C-11919AC218D6‘)) AS subNode
WHERE [MO_ROUTING].[MO_ROUTING_ID] = [subNode].[MO_ROUTING_ID]
一定要記得寫別名,這樣的會簡潔很多:
SELECT A.ITEM_ID ,
A.ITEM_FEATURE_ID ,
A.WAREHOUSE_ID ,
A.BIN_ID ,
A.ITEM_LOT_ID ,
A.INVENTORY_QTY ,
A.SECOND_QTY
FROM ITEM_WAREHOUSE_BIN AS A
LEFT JOIN ISSUE_RECEIPT_D AS B ON A.ITEM_ID = B.ITEM_ID
AND A.ITEM_FEATURE_ID = B.ITEM_FEATURE_ID
AND A.WAREHOUSE_ID = B.WAREHOUSE_ID
AND A.BIN_ID = B.BIN_ID
AND A.ITEM_LOT_ID = B.ITEM_LOT_ID
AND A.INVENTORY_QTY > 0
AND A.SECOND_QTY > 0
LEFT JOIN ISSUE_RECEIPT AS C ON A.Owner_Org_ROid = C.Owner_Org_ROid;
攔截的地址:
就是說在攔截數據庫的時候就是當你用的是哪個地址的時候就用哪一個地址,比如說你用的是公司的就是公司的地址,你用本地就本地的地址
以後代碼的修改一定要修改一個類之後就立馬調試一下,不然返回修改會特別難受
一定要記得前面如果關聯的時候有給表取別名的話一定要記得在後面一樣也要用別名
上面那個是界面上的字段,下面是更新數據庫裏面的


 而且一般都是主外鍵的關系,不然的話也沒有什麽意義(主外鍵就是外鍵的值必須是主鍵裏面有的,不然就加不進去)
inner join和join是一樣的:內連接
left join和left outer join是一樣的:左(外)連接
right join和right outer join是一樣的:左(外)連接
full join和full outer join是一樣的:全(外)連接
一般用的最多的就是Left Join,基本上只用這個
記住裏面的SQL文件.sql只能將其保存在數據庫指定的文件夾之中,就是點完保存之後的那個文件夾,不然的話是保存不下來的:D:\我的文檔\SQL Server Management Studio(eg:我的電腦上路徑是這樣的)
linq的關聯查詢(linq多個條件的聯合查詢在這個文件夾中專門的一個文件說明)
Sum()函數裏面是需要寫個匿名方法的,用Linq寫(查一下,回憶一下這個關聯查詢,還有linq 裏面的一些方法,分析一下下面的linq)
linq必須使用於實現了IEnumerable<T>接口的對象,也就是說必須是泛型集合
下面一段代碼的解釋:http://www.cnblogs.com/wangfuyou/p/6180557.html 1(AsEnumerable(),裏面有連接SQL Server的代碼)
而且一般都是主外鍵的關系,不然的話也沒有什麽意義(主外鍵就是外鍵的值必須是主鍵裏面有的,不然就加不進去)
inner join和join是一樣的:內連接
left join和left outer join是一樣的:左(外)連接
right join和right outer join是一樣的:左(外)連接
full join和full outer join是一樣的:全(外)連接
一般用的最多的就是Left Join,基本上只用這個
記住裏面的SQL文件.sql只能將其保存在數據庫指定的文件夾之中,就是點完保存之後的那個文件夾,不然的話是保存不下來的:D:\我的文檔\SQL Server Management Studio(eg:我的電腦上路徑是這樣的)
linq的關聯查詢(linq多個條件的聯合查詢在這個文件夾中專門的一個文件說明)
Sum()函數裏面是需要寫個匿名方法的,用Linq寫(查一下,回憶一下這個關聯查詢,還有linq 裏面的一些方法,分析一下下面的linq)
linq必須使用於實現了IEnumerable<T>接口的對象,也就是說必須是泛型集合
下面一段代碼的解釋:http://www.cnblogs.com/wangfuyou/p/6180557.html 1(AsEnumerable(),裏面有連接SQL Server的代碼)
 throw new BusinessRuleException("傳票:mSPLIT_DOC_NO 對應的此道工序轉移總量不可大於拆分數量!");(代碼裏面報錯 )
審核時,單頭和單身都會審核,所以e取得的實體可能是單頭也可能是單身
if (string.IsNullOrEmpty(e.Path))
{所以要加上這個
throw new BusinessRuleException("傳票:mSPLIT_DOC_NO 對應的此道工序轉移總量不可大於拆分數量!");(代碼裏面報錯 )
審核時,單頭和單身都會審核,所以e取得的實體可能是單頭也可能是單身
if (string.IsNullOrEmpty(e.Path))
{所以要加上這個
 SELECT * FROM (SELECT TOP 1000 SALES_ISSUE.DOC_NO+‘-‘+CAST(SALES_ISSUE_D.SequenceNumber AS NVARCHAR(20)) AS DOC_NO
FROM SALES_ISSUE_D AS SALES_ISSUE_D
INNER JOIN SALES_ISSUE ON SALES_ISSUE_D.SALES_ISSUE_ID=SALES_ISSUE.SALES_ISSUE_ID
WHERE
--SALES_ISSUE_D.SOURCE_ID_ROid=‘‘
--AND
SALES_ISSUE.ApproveStatus<>‘V‘
ORDER BY SALES_ISSUE.DOC_NO,SALES_ISSUE_D.SequenceNumber) AS A
UNION ALL
SELECT * FROM (SELECT TOP 1000 SALES_RETURN_RECEIPT.DOC_NO+‘-‘+CAST(SALES_RETURN_RECEIPT_D.SequenceNumber AS NVARCHAR(20)) AS DOC_NO
FROM SALES_RETURN_RECEIPT_D AS SALES_RETURN_RECEIPT_D
INNER JOIN SALES_RETURN_RECEIPT ON SALES_RETURN_RECEIPT_D.SALES_RETURN_RECEIPT_ID=SALES_RETURN_RECEIPT.SALES_RETURN_RECEIPT_ID
INNER JOIN SALES_RETURN_D ON SALES_RETURN_RECEIPT_D.SOURCE_ID_ROid=SALES_RETURN_D.SALES_RETURN_D_ID
WHERE
--SALES_RETURN_D.SOURCE_ID.ROid=‘‘
-- AND
SALES_RETURN_RECEIPT.ApproveStatus<>‘V‘
ORDER BY DOC_NO) AS B
必須放在子查詢中,還有就是相加的時候需要將int轉換成varchar
而且裏面必須是有top或者for XML,否則,ORDER BY 子句在視圖、內聯函數、派生表、子查詢和公用表表達式中無效。
還有就是記得在後面等於界面上的值的時候要將其註釋掉,以後跟代碼的時候再測試,不然的話就無法檢驗自己寫的是對是錯
還有就是只有是內嵌select的時候才可以將其別名。字段,不然的話本來就有的表取別名,就像上面的SALES_RETURN_RECEIPT_D ,就可以直接在最下面用別名來排序,不能用別名點字段,因為這個表裏是沒有這個字段的,但是你查詢(這個相當於是總的查詢的字段是可以寫的)
還有就是像這種的一但全部選擇發現有錯誤的時候就需要將其分開來測試,就比如像union前面和後面分別進行測試就可以了
GUID賦值就是下面那樣賦值:
‘00000000-0000-0000-0000-000000000000‘
‘CDCAB790-A674-8BD3-F817-C04C90B7CACD‘ ,
linq集合
var ValidSN2 = (from vsn in ValidSN1
select new
{
itemId=vsn["ITEM_ID"],
itemFeId=vsn["ITEM_FEATURE_ID"]
}).Distinct();
沒有那些Sum以及Count等函數的時候就需要把那個Group by給mark掉了
SELECT * FROM (SELECT TOP 1000 SALES_ISSUE.DOC_NO+‘-‘+CAST(SALES_ISSUE_D.SequenceNumber AS NVARCHAR(20)) AS DOC_NO
FROM SALES_ISSUE_D AS SALES_ISSUE_D
INNER JOIN SALES_ISSUE ON SALES_ISSUE_D.SALES_ISSUE_ID=SALES_ISSUE.SALES_ISSUE_ID
WHERE
--SALES_ISSUE_D.SOURCE_ID_ROid=‘‘
--AND
SALES_ISSUE.ApproveStatus<>‘V‘
ORDER BY SALES_ISSUE.DOC_NO,SALES_ISSUE_D.SequenceNumber) AS A
UNION ALL
SELECT * FROM (SELECT TOP 1000 SALES_RETURN_RECEIPT.DOC_NO+‘-‘+CAST(SALES_RETURN_RECEIPT_D.SequenceNumber AS NVARCHAR(20)) AS DOC_NO
FROM SALES_RETURN_RECEIPT_D AS SALES_RETURN_RECEIPT_D
INNER JOIN SALES_RETURN_RECEIPT ON SALES_RETURN_RECEIPT_D.SALES_RETURN_RECEIPT_ID=SALES_RETURN_RECEIPT.SALES_RETURN_RECEIPT_ID
INNER JOIN SALES_RETURN_D ON SALES_RETURN_RECEIPT_D.SOURCE_ID_ROid=SALES_RETURN_D.SALES_RETURN_D_ID
WHERE
--SALES_RETURN_D.SOURCE_ID.ROid=‘‘
-- AND
SALES_RETURN_RECEIPT.ApproveStatus<>‘V‘
ORDER BY DOC_NO) AS B
必須放在子查詢中,還有就是相加的時候需要將int轉換成varchar
而且裏面必須是有top或者for XML,否則,ORDER BY 子句在視圖、內聯函數、派生表、子查詢和公用表表達式中無效。
還有就是記得在後面等於界面上的值的時候要將其註釋掉,以後跟代碼的時候再測試,不然的話就無法檢驗自己寫的是對是錯
還有就是只有是內嵌select的時候才可以將其別名。字段,不然的話本來就有的表取別名,就像上面的SALES_RETURN_RECEIPT_D ,就可以直接在最下面用別名來排序,不能用別名點字段,因為這個表裏是沒有這個字段的,但是你查詢(這個相當於是總的查詢的字段是可以寫的)
還有就是像這種的一但全部選擇發現有錯誤的時候就需要將其分開來測試,就比如像union前面和後面分別進行測試就可以了
GUID賦值就是下面那樣賦值:
‘00000000-0000-0000-0000-000000000000‘
‘CDCAB790-A674-8BD3-F817-C04C90B7CACD‘ ,
linq集合
var ValidSN2 = (from vsn in ValidSN1
select new
{
itemId=vsn["ITEM_ID"],
itemFeId=vsn["ITEM_FEATURE_ID"]
}).Distinct();
沒有那些Sum以及Count等函數的時候就需要把那個Group by給mark掉了
修改sa的密碼:
可以先用window登進去之後安全性中的sa點屬性就可以改密碼,而且每一個網址對應的sa其實是不一樣的,也就是說這些密碼也是不一樣的
而且可以同時連接好幾個數據庫的呢,點完這個之後就會又多一個數據庫,也是可以相互切換操作的
SQL 對大小寫不敏感!裏面是不需要進行分號隔開的,裏面分為DDL(數據庫定義語言)和DML(數據庫操作語言),數據庫定義語言主要包括:創建數據庫,表以及索引,修改這三個以及刪除(create,drop,alter),數據庫操作語言就是包括增刪改查
create index:
增加索引的好處就是 首先明白為什麽索引會增加速度,DB在執行一條Sql語句的時候,默認的方式是根據搜索條件進行全表掃描,遇到匹配條件的就加入搜索結果集合。如果我們對某一字段增加索引,查詢時就會先去索引列表中一次定位到特定值的行數,大大減少遍歷匹配的行數,所以能明顯增加查詢的速度。那麽在任何時候都應該加索引麽?這裏有幾個反例:1、如果每次都需要取到所有表記錄,無論如何都必須進行全表掃描了,那麽是否加索引也沒有意義了。2、對非唯一的字段,例如“性別”這種大量重復值的字段,增加索引也沒有什麽意義。3、對於記錄比較少的表,增加索引不會帶來速度的優化反而浪費了存儲空間,因為索引是需要存儲空間的,而且有個致命缺點是對於update/insert/delete的每次執行,字段的索引都必須重新計算更新。 那麽在什麽時候適合加上索引呢?我們看一個Mysql手冊中舉的例子,這裏有一條sql語句: SELECT c.companyID, c.companyName FROM Companies c, User u WHERE c.companyID = u.fk_companyID AND c.numEmployees >= 0 AND c.companyName LIKE ‘%i%‘ AND u.groupID IN (SELECT g.groupID FROM Groups g WHERE g.groupLabel = ‘Executive‘) 這條語句涉及3個表的聯接,並且包括了許多搜索條件比如大小比較,Like匹配等。在沒有索引的情況下Mysql需要執行的掃描行數是77721876行。而我們通過在companyID和groupLabel兩個字段上加上索引之後,掃描的行數只需要134行。在Mysql中可以通過Explain Select來查看掃描次數。可以看出來在這種聯表和復雜搜索條件的情況下,索引帶來的性能提升遠比它所占據的磁盤空間要重要得多。
create table person(id int identity(1,1))或者id int primary key identity(1,1)
alter table person add id int identity(1,1) [表示從1開的之後每次都自增長1]
CASE WHEN:
SELECT SUM(population),
CASE country WHEN ‘中國‘ THEN ‘亞洲‘
WHEN ‘印度‘ THEN ‘亞洲‘
WHEN ‘日本‘ THEN ‘亞洲‘
WHEN ‘美國‘ THEN ‘北美洲‘
WHEN ‘加拿大‘ THEN ‘北美洲‘
WHEN ‘墨西哥‘ THEN ‘北美洲‘
ELSE ‘其他‘ END
CASE WHEN salary <= 500 THEN ‘1‘
WHEN salary > 500 AND salary <= 600 THEN ‘2‘
WHEN salary > 600 AND salary <= 800 THEN ‘3‘
WHEN salary > 800 AND salary <= 1000 THEN ‘4‘
ELSE NULL END;
UPDATE XPALLET SET STOCK_STATUS CASE When STOCK_STATUS<>‘0‘ THEN ‘0‘ END
以後批量更新記得要直接在下面弄一個集合然後在上面應用,還有一個不要隨便用static這個關鍵字要考慮寫一個方法來進行查詢
UPDATE [MO_ROUTING] SET [XREM_DATE1]=‘2017-08-24‘,[XC0LOR_WARNING]=N‘4‘
FROM (SELECT [MO_ROUTING].[MO_ROUTING_ID]
FROM [MO_ROUTING] AS [MO_ROUTING]
WHERE [MO_ROUTING].[MO_ROUTING_ID] IN (‘0794EBE8-DA28-477A-3DA5- 11919AC17B9E‘,‘59119A86-743B-4996-83CD-11919AC1E20C‘,‘715BFA76-1F3A-4712-612C-11919AC218D6‘)) AS subNode
WHERE [MO_ROUTING].[MO_ROUTING_ID] = [subNode].[MO_ROUTING_ID]
一定要記得寫別名,這樣的會簡潔很多:
SELECT A.ITEM_ID ,
A.ITEM_FEATURE_ID ,
A.WAREHOUSE_ID ,
A.BIN_ID ,
A.ITEM_LOT_ID ,
A.INVENTORY_QTY ,
A.SECOND_QTY
FROM ITEM_WAREHOUSE_BIN AS A
LEFT JOIN ISSUE_RECEIPT_D AS B ON A.ITEM_ID = B.ITEM_ID
AND A.ITEM_FEATURE_ID = B.ITEM_FEATURE_ID
AND A.WAREHOUSE_ID = B.WAREHOUSE_ID
AND A.BIN_ID = B.BIN_ID
AND A.ITEM_LOT_ID = B.ITEM_LOT_ID
AND A.INVENTORY_QTY > 0
AND A.SECOND_QTY > 0
LEFT JOIN ISSUE_RECEIPT AS C ON A.Owner_Org_ROid = C.Owner_Org_ROid;
攔截的地址:
就是說在攔截數據庫的時候就是當你用的是哪個地址的時候就用哪一個地址,比如說你用的是公司的就是公司的地址,你用本地就本地的地址
以後代碼的修改一定要修改一個類之後就立馬調試一下,不然返回修改會特別難受
一定要記得前面如果關聯的時候有給表取別名的話一定要記得在後面一樣也要用別名
上面那個是界面上的字段,下面是更新數據庫裏面的
而且一般都是主外鍵的關系,不然的話也沒有什麽意義(主外鍵就是外鍵的值必須是主鍵裏面有的,不然就加不進去)
inner join和join是一樣的:內連接
left join和left outer join是一樣的:左(外)連接
right join和right outer join是一樣的:左(外)連接
full join和full outer join是一樣的:全(外)連接
一般用的最多的就是Left Join,基本上只用這個
記住裏面的SQL文件.sql只能將其保存在數據庫指定的文件夾之中,就是點完保存之後的那個文件夾,不然的話是保存不下來的:D:\我的文檔\SQL Server Management Studio(eg:我的電腦上路徑是這樣的)
linq的關聯查詢(linq多個條件的聯合查詢在這個文件夾中專門的一個文件說明)
Sum()函數裏面是需要寫個匿名方法的,用Linq寫(查一下,回憶一下這個關聯查詢,還有linq 裏面的一些方法,分析一下下面的linq)
linq必須使用於實現了IEnumerable<T>接口的對象,也就是說必須是泛型集合
下面一段代碼的解釋:http://www.cnblogs.com/wangfuyou/p/6180557.html 1(AsEnumerable(),裏面有連接SQL Server的代碼)
throw new BusinessRuleException("傳票:mSPLIT_DOC_NO 對應的此道工序轉移總量不可大於拆分數量!");(代碼裏面報錯 )
審核時,單頭和單身都會審核,所以e取得的實體可能是單頭也可能是單身
if (string.IsNullOrEmpty(e.Path))
{所以要加上這個
SELECT * FROM (SELECT TOP 1000 SALES_ISSUE.DOC_NO+‘-‘+CAST(SALES_ISSUE_D.SequenceNumber AS NVARCHAR(20)) AS DOC_NO
FROM SALES_ISSUE_D AS SALES_ISSUE_D
INNER JOIN SALES_ISSUE ON SALES_ISSUE_D.SALES_ISSUE_ID=SALES_ISSUE.SALES_ISSUE_ID
WHERE
--SALES_ISSUE_D.SOURCE_ID_ROid=‘‘
--AND
SALES_ISSUE.ApproveStatus<>‘V‘
ORDER BY SALES_ISSUE.DOC_NO,SALES_ISSUE_D.SequenceNumber) AS A
UNION ALL
SELECT * FROM (SELECT TOP 1000 SALES_RETURN_RECEIPT.DOC_NO+‘-‘+CAST(SALES_RETURN_RECEIPT_D.SequenceNumber AS NVARCHAR(20)) AS DOC_NO
FROM SALES_RETURN_RECEIPT_D AS SALES_RETURN_RECEIPT_D
INNER JOIN SALES_RETURN_RECEIPT ON SALES_RETURN_RECEIPT_D.SALES_RETURN_RECEIPT_ID=SALES_RETURN_RECEIPT.SALES_RETURN_RECEIPT_ID
INNER JOIN SALES_RETURN_D ON SALES_RETURN_RECEIPT_D.SOURCE_ID_ROid=SALES_RETURN_D.SALES_RETURN_D_ID
WHERE
--SALES_RETURN_D.SOURCE_ID.ROid=‘‘
-- AND
SALES_RETURN_RECEIPT.ApproveStatus<>‘V‘
ORDER BY DOC_NO) AS B
必須放在子查詢中,還有就是相加的時候需要將int轉換成varchar
而且裏面必須是有top或者for XML,否則,ORDER BY 子句在視圖、內聯函數、派生表、子查詢和公用表表達式中無效。
還有就是記得在後面等於界面上的值的時候要將其註釋掉,以後跟代碼的時候再測試,不然的話就無法檢驗自己寫的是對是錯
還有就是只有是內嵌select的時候才可以將其別名。字段,不然的話本來就有的表取別名,就像上面的SALES_RETURN_RECEIPT_D ,就可以直接在最下面用別名來排序,不能用別名點字段,因為這個表裏是沒有這個字段的,但是你查詢(這個相當於是總的查詢的字段是可以寫的)
還有就是像這種的一但全部選擇發現有錯誤的時候就需要將其分開來測試,就比如像union前面和後面分別進行測試就可以了
GUID賦值就是下面那樣賦值:
‘00000000-0000-0000-0000-000000000000‘
‘CDCAB790-A674-8BD3-F817-C04C90B7CACD‘ ,
linq集合
var ValidSN2 = (from vsn in ValidSN1
select new
{
itemId=vsn["ITEM_ID"],
itemFeId=vsn["ITEM_FEATURE_ID"]
}).Distinct();
沒有那些Sum以及Count等函數的時候就需要把那個Group by給mark掉了
數據庫知識