
Python Day36 python多線程
一、什麽是線程:
在傳統操作系統中,每個進程有一個地址空間,而且默認就有一個控制線程
線程顧名思義,就是一條流水線工作的過程,一條流水線必須屬於一個車間,一個車間的工作過程是一個進程
車間負責把資源整合到一起,是一個資源單位,而一個車間內至少有一個流水線
流水線的工作需要電源,電源就相當於cpu
所以,進程只是用來把資源集中到一起(進程只是一個資源單位,或者說資源集合),而線程才是cpu上的執行單位。
多線程(即多個控制線程)的概念是,在一個進程中存在多個控制線程,多個控制線程共享該進程的地址空間,相當於一個車間內有多條流水線,都共用一個車間的資源。
例如,北京地鐵與上海地鐵是不同的進程,而北京地鐵裏的13號線是一個線程,北京地鐵所有的線路共享北京地鐵所有的資源,比如所有的乘客可以被所有線路拉。
二、 線程的創建開銷小:
如果我們的軟件是一個工廠,該工廠有多條流水線,流水線工作需要電源,電源只有一個即cpu(單核cpu)
一個車間就是一個進程,一個車間至少一條流水線(一個進程至少一個線程)
創建一個進程,就是創建一個車間(申請空間,在該空間內建至少一條流水線)
而建線程,就只是在一個車間內造一條流水線,無需申請空間,所以創建開銷小
進程之間是競爭關系,線程之間是協作關系?
車間直接是競爭/搶電源的關系,競爭(不同的進程直接是競爭關系,是不同的程序員寫的程序運行的,迅雷搶占其他進程的網速,360把其他進程當做病毒幹死)
一個車間的不同流水線式協同工作的關系(同一個進程的線程之間是合作關系,是同一個程序寫的程序內開啟動,迅雷內的線程是合作關系,不會自己幹自己)
三、線程與進程的區別:
1.線程共享創建它的進程的地址空間,進程有自己的地址空間。
2.線程直接訪問進程的數據段;進程擁有父進程的數據段的自身副本。
3.線程可以直接與其他線程的過程;過程必須使用進程間通信與兄弟姐妹的過程。
4.很容易創建新線程;新工藝要求父進程復制。
5.線程可以對相同進程的線程進行相當的控制;進程只能對子進程進行控制。
6.對主線程的更改(取消、優先級更改等)可能影響進程的其他線程的行為;對父進程的更改不會影響子進程。
四、 為何要用多線程:
多線程指的是,在一個進程中開啟多個線程,簡單的講:如果多個任務共用一塊地址空間,那麽必須在一個進程內開啟多個線程。詳細的講分為4點:
1. 多線程共享一個進程的地址空間
2. 線程比進程更輕量級,線程比進程更容易創建可撤銷,在許多操作系統中,創建一個線程比創建一個進程要快10-100倍,在有大量線程需要動態和快速修改時,這一特性很有用
3. 若多個線程都是cpu密集型的,那麽並不能獲得性能上的增強,但是如果存在大量的計算和大量的I/O處理,擁有多個線程允許這些活動彼此重疊運行,從而會加快程序執行的速度。
4. 在多cpu系統中,為了最大限度的利用多核,可以開啟多個線程,比開進程開銷要小的多。(這一條並不適用於python)
五、 多線程的應用舉例:
開啟一個字處理軟件進程,該進程肯定需要辦不止一件事情,比如監聽鍵盤輸入,處理文字,定時自動將文字保存到硬盤,這三個任務操作的都是同一塊數據,因而不能用多進程。只能在一個進程裏並發地開啟三個線程,如果是單線程,那就只能是,鍵盤輸入時,不能處理文字和自動保存,自動保存時又不能輸入和處理文字。
六、 threading模塊介紹:
multiprocess模塊的完全模仿了threading模塊的接口,二者在使用層面,有很大的相似性,因而不再詳細介紹
七、開啟線程的兩種方式:
#方式一 from threading import Thread import time def sayhi(name): time.sleep(2) print(‘%s say hello‘ %name) if __name__ == ‘__main__‘: t=Thread(target=sayhi,args=(‘egon‘,)) t.start() print(‘主線程‘) 方式一
#方式二 from threading import Thread import time class Sayhi(Thread): def __init__(self,name): super().__init__() self.name=name def run(self): time.sleep(2) print(‘%s say hello‘ % self.name) if __name__ == ‘__main__‘: t = Sayhi(‘egon‘) t.start() print(‘主線程‘) 方式二
八、在一個進程下開啟多個線程與在一個進程下開啟多個子進程的區別:
from threading import Thread from multiprocessing import Process import os def work(): print(‘hello‘) if __name__ == ‘__main__‘: #在主進程下開啟線程 t=Thread(target=work) t.start() print(‘主線程/主進程‘) ‘‘‘ 打印結果: hello 主線程/主進程 ‘‘‘ #在主進程下開啟子進程 t=Process(target=work) t.start() print(‘主線程/主進程‘) ‘‘‘ 打印結果: 主線程/主進程 hello ‘‘‘ 誰的開啟速度快
from threading import Thread from multiprocessing import Process import os def work(): print(‘hello‘,os.getpid()) if __name__ == ‘__main__‘: #part1:在主進程下開啟多個線程,每個線程都跟主進程的pid一樣 t1=Thread(target=work) t2=Thread(target=work) t1.start() t2.start() print(‘主線程/主進程pid‘,os.getpid()) #part2:開多個進程,每個進程都有不同的pid p1=Process(target=work) p2=Process(target=work) p1.start() p2.start() print(‘主線程/主進程pid‘,os.getpid()) 瞅一瞅pid
from threading import Thread from multiprocessing import Process import os def work(): global n n=0 if __name__ == ‘__main__‘: # n=100 # p=Process(target=work) # p.start() # p.join() # print(‘主‘,n) #毫無疑問子進程p已經將自己的全局的n改成了0,但改的僅僅是它自己的,查看父進程的n仍然為100 n=1 t=Thread(target=work) t.start() t.join() print(‘主‘,n) #查看結果為0,因為同一進程內的線程之間共享進程內的數據 同一進程內的線程共享該進程的數據?
九、守護線程
無論是進程還是線程,都遵循:守護xxx會等待主xxx運行完畢後被銷毀
需要強調的是:運行完畢並非終止運行
1.對主進程來說,運行完畢指的是主進程代碼運行完畢
2.對主線程來說,運行完畢指的是主線程所在的進程內所有非守護線程統統運行完畢,主線程才算運行完畢
詳細解釋:
1 主進程在其代碼結束後就已經算運行完畢了(守護進程在此時就被回收),然後主進程會一直等非守護的子進程都運行完畢後回收子進程的資源(否則會產生僵屍進程),才會結束, 2 主線程在其他非守護線程運行完畢後才算運行完畢(守護線程在此時就被回收)。因為主線程的結束意味著進程的結束,進程整體的資源都將被回收,而進程必須保證非守護線程都運行完畢後才能結束。
from threading import Thread import time def sayhi(name): time.sleep(2) print(‘%s say hello‘ %name) if __name__ == ‘__main__‘: t=Thread(target=sayhi,args=(‘egon‘,)) t.setDaemon(True) #必須在t.start()之前設置 t.start() print(‘主線程‘) print(t.is_alive()) ‘‘‘ 主線程 True ‘‘‘
十、GIL介紹
GIL本質就是一把互斥鎖,既然是互斥鎖,所有互斥鎖的本質都一樣,都是將並發運行變成串行,以此來控制同一時間內共享數據只能被一個任務所修改,進而保證數據安全。
可以肯定的一點是:保護不同的數據的安全,就應該加不同的鎖。
要想了解GIL,首先確定一點:每次執行python程序,都會產生一個獨立的進程。例如python test.py,python aaa.py,python bbb.py會產生3個不同的python進程
#1 所有數據都是共享的,這其中,代碼作為一種數據也是被所有線程共享的(test.py的所有代碼以及Cpython解釋器的所有代碼) 例如:test.py定義一個函數work(代碼內容如下圖),在進程內所有線程都能訪問到work的代碼,於是我們可以開啟三個線程然後target都指向該代碼,能訪問到意味著就是可以執行。 #2 所有線程的任務,都需要將任務的代碼當做參數傳給解釋器的代碼去執行,即所有的線程要想運行自己的任務,首先需要解決的是能夠訪問到解釋器的代碼。
綜上:
如果多個線程的target=work,那麽執行流程是
多個線程先訪問到解釋器的代碼,即拿到執行權限,然後將target的代碼交給解釋器的代碼去執行
解釋器的代碼是所有線程共享的,所以垃圾回收線程也可能訪問到解釋器的代碼而去執行,這就導致了一個問題:對於同一個數據100,可能線程1執行x=100的同時,而垃圾回收執行的是回收100的操作,解決這種問題沒有什麽高明的方法,就是加鎖處理,如下圖的GIL,保證python解釋器同一時間只能執行一個任務的代碼
十一、GIL與Lock:
IL保護的是解釋器級的數據,保護用戶自己的數據則需要自己加鎖處理
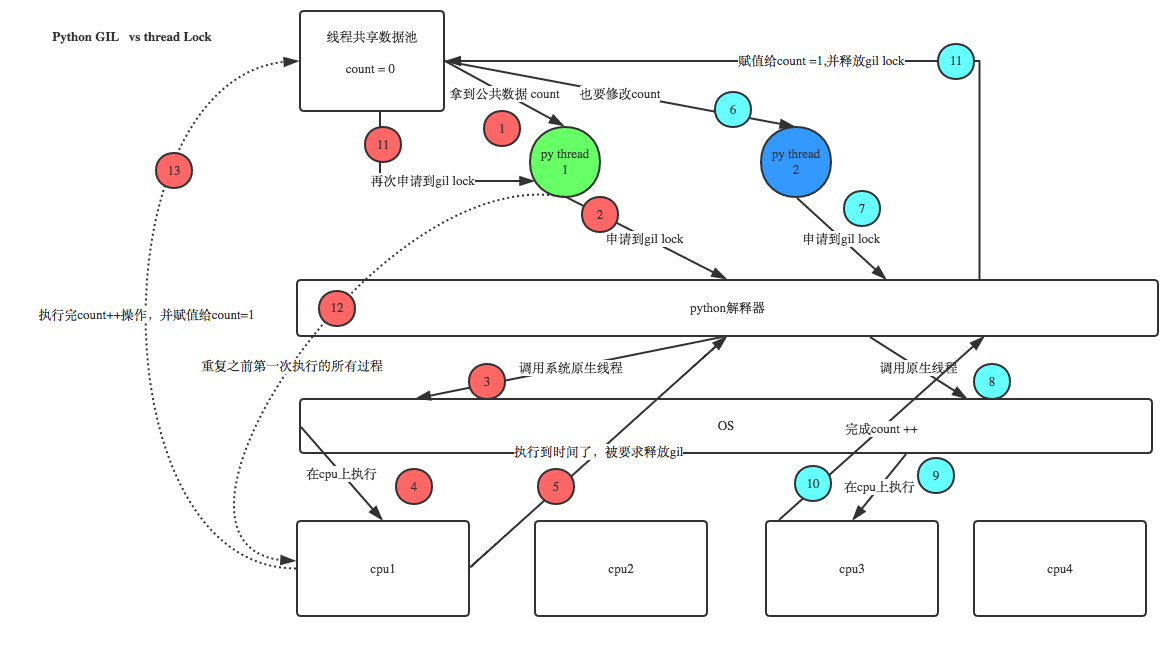
十二、GIL與多線程
有了GIL的存在,同一時刻同一進程中只有一個線程被執行
聽到這裏,有的同學立馬質問:進程可以利用多核,但是開銷大,而python的多線程開銷小,但卻無法利用多核優勢,也就是說python沒用了,php才是最牛逼的語言?
別著急啊,老娘還沒講完呢。
要解決這個問題,我們需要在幾個點上達成一致:
1. cpu到底是用來做計算的,還是用來做I/O的? 2. 多cpu,意味著可以有多個核並行完成計算,所以多核提升的是計算性能 3. 每個cpu一旦遇到I/O阻塞,仍然需要等待,所以多核對I/O操作沒什麽用處
一個工人相當於cpu,此時計算相當於工人在幹活,I/O阻塞相當於為工人幹活提供所需原材料的過程,工人幹活的過程中如果沒有原材料了,則工人幹活的過程需要停止,直到等待原材料的到來。
如果你的工廠幹的大多數任務都要有準備原材料的過程(I/O密集型),那麽你有再多的工人,意義也不大,還不如一個人,在等材料的過程中讓工人去幹別的活,
反過來講,如果你的工廠原材料都齊全,那當然是工人越多,效率越高
結論:
對計算來說,cpu越多越好,但是對於I/O來說,再多的cpu也沒用
當然對運行一個程序來說,隨著cpu的增多執行效率肯定會有所提高(不管提高幅度多大,總會有所提高),這是因為一個程序基本上不會是純計算或者純I/O,所以我們只能相對的去看一個程序到底是計算密集型還是I/O密集型,從而進一步分析python的多線程到底有無用武之地
#分析: 我們有四個任務需要處理,處理方式肯定是要玩出並發的效果,解決方案可以是: 方案一:開啟四個進程 方案二:一個進程下,開啟四個線程 #單核情況下,分析結果: 如果四個任務是計算密集型,沒有多核來並行計算,方案一徒增了創建進程的開銷,方案二勝 如果四個任務是I/O密集型,方案一創建進程的開銷大,且進程的切換速度遠不如線程,方案二勝 #多核情況下,分析結果: 如果四個任務是計算密集型,多核意味著並行計算,在python中一個進程中同一時刻只有一個線程執行用不上多核,方案一勝 如果四個任務是I/O密集型,再多的核也解決不了I/O問題,方案二勝 #結論:現在的計算機基本上都是多核,python對於計算密集型的任務開多線程的效率並不能帶來多大性能上的提升,甚至不如串行(沒有大量切換),但是,對於IO密集型的任務效率還是有顯著提升的。
Python Day36 python多線程