
12、python全棧之路-並發編程之多進程
十二、並發編程之多進程
http://www.cnblogs.com/linhaifeng/articles/6817679.html
理論:http://www.cnblogs.com/linhaifeng/articles/7430066.html
鏈接:http://www.cnblogs.com/linhaifeng/articles/7428874.html
1、必備理論基礎
1.1 操作系統的作用
1:隱藏醜陋復雜的硬件接口,提供良好的抽象接口
2:管理、調度進程,並且將多個進程對硬件的競爭變得有序
1.2 多道技術
1.產生背景:針對單核,實現並發
ps:
現在的主機一般是多核,那麽每個核都會利用多道技術
有4個cpu,運行於cpu1的某個程序遇到io阻塞,會等到io結束再重新調度,會被調度到4個cpu中的任意一個,具體由操作系統調度算法決定。
2.空間上的復用:如內存中同時有多道程序
3.時間上的復用:復用一個cpu的時間片
強調:遇到io切,占用cpu時間過長也切,核心在於切之前將進程的狀態保存下來,這樣才能保證下次切換回來時,能基於上次切走的位置繼續運行
2、多進程
2.1 什麽是進程
進程:正在進行的一個過程或者說一個任務。而負責執行任務則是cpu。
舉例(單核+多道,實現多個進程的並發執行):
egon在一個時間段內有很多任務要做:python
egon備一會課,再去跟李傑的女朋友聊聊天,再去打一會王者榮耀....這就保證了每個任務都在進行中。
2.2 進程與程序的區別
程序僅僅只是一堆代碼而已,而進程指的是程序的運行過程。
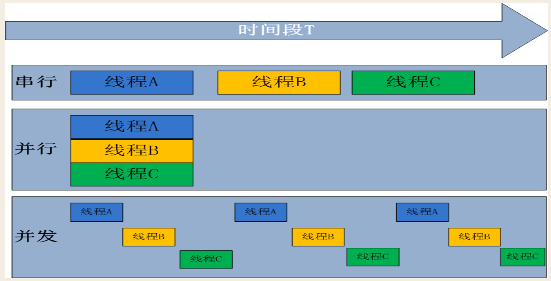
2.3 並發與並行
2.3.1 並發
並發:是偽並行,即看起來是同時運行。單個cpu+多道技術就可以實現並發,(並行也屬於並發)
2.3.2 並行
並行:同時運行,只有具備多個cpu才能實現並行
2.4 阻塞與非阻塞
2.4.1 阻塞
#阻塞調用是指調用結果返回之前,當前線程會被掛起(如遇到
#舉例:
#1. 同步調用:apply一個累計1億次的任務,該調用會一直等待,直到任務返回結果為止,但並未阻塞住(即便是被搶走cpu的執行權限,那也是處於就緒態);
#2. 阻塞調用:當socket工作在阻塞模式的時候,如果沒有數據的情況下調用recv函數,則當前線程就會被掛起,直到有數據為止。
2.4.2 非阻塞
#非阻塞和阻塞的概念相對應,指在不能立刻得到結果之前也會立刻返回,同時該函數不會阻塞當前線程。
2.4.3 小結
阻塞與非阻塞針對的是進程或線程:阻塞是當請求不能滿足的時候就將進程掛起,而非阻塞則不會阻塞當前進程
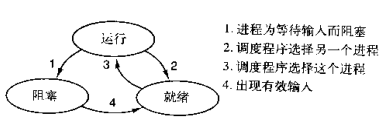
2.5 進程的狀態
一個進程由三種狀態:
2.6 進程的創建
2.6.1 進程的創建
1. 系統初始化(查看進程linux中用ps命令,windows中用任務管理器,前臺進程負責與用戶交互,後臺運行的進程與用戶無關,運行在後臺並且只在需要時才喚醒的進程,稱為守護進程,如電子郵件、web頁面、新聞、打印)
2. 一個進程在運行過程中開啟了子進程(如nginx開啟多進程,os.fork,subprocess.Popen等)
3. 用戶的交互式請求,而創建一個新進程(如用戶雙擊暴風影音)
4. 一個批處理作業的初始化(只在大型機的批處理系統中應用)
進程都是由操作系統開啟的,開進程時先給操作系統發信號,再由操作系統開啟進程
2.6.2 創建的子進程UNIX和windows區別
1.相同的是:進程創建後,父進程和子進程有各自不同的地址空間(多道技術要求物理層面實現進程之間內存的隔離),任何一個進程的在其地址空間中的修改都不會影響到另外一個進程。
2.不同的是:在UNIX中,子進程的初始地址空間是父進程的一個副本,提示:子進程和父進程是可以有只讀的共享內存區的。但是對於windows系統來說,從一開始父進程與子進程的地址空間就是不同的。
linux子進程和父進程的初始狀態一樣
windows子進程和父進程的初始狀態就不同
2.7 終止進程
1. 正常退出(自願,如用戶點擊交互式頁面的叉號,或程序執行完畢調用發起系統調用正常退出,在linux中用exit,在windows中用ExitProcess)
2. 出錯退出(自願,python a.py中a.py不存在)
3. 嚴重錯誤(非自願,執行非法指令,如引用不存在的內存,1/0等,可以捕捉異常,try...except...)
4. 被其他進程殺死(非自願,如kill -9)
3、開啟子進程multiprocessing
3.1 方式一
定義一個函數
from multiprocessing import Process
import time
def work(name):
print(‘%s is piaoing‘ %name)
time.sleep(3)
print(‘%s piao end‘ %name)
if __name__ == ‘__main__‘: #在windows系統上必須要在__main__下調用
# Process(target=work,kwargs={‘name‘:‘alex‘})
p=Process(target=work,args=(‘alex‘,)) #target函數名,args參數
p.start()
print(‘主‘)
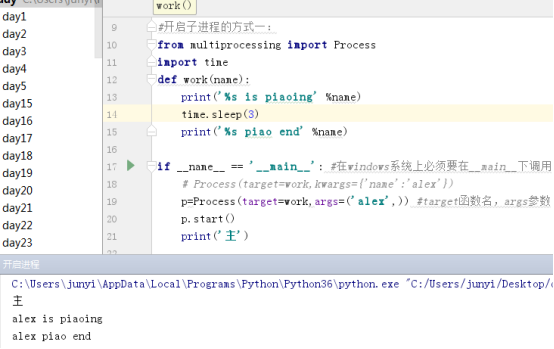
子進程結束後,子進程的資源由父進程回收掉,所以主進程要在子進程結束後再終止,如果子進程沒有終止而主進程突然被終止,那麽子進程的資源無法回收,會成為僵屍進程。
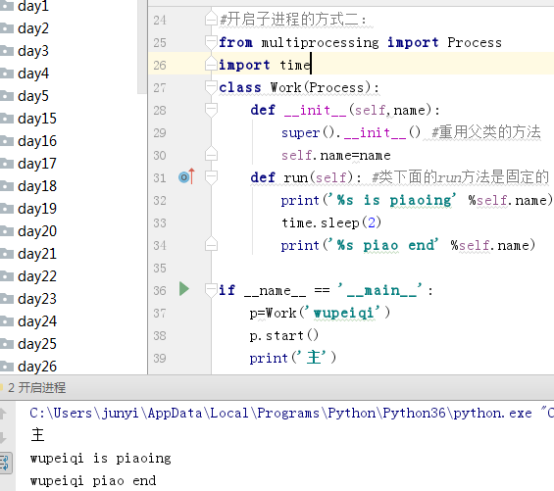
3.2 方式二
from multiprocessing import Process
import time
class Work(Process):
def __init__(self,name):
super().__init__() #重用父類的方法
self.name=name
def run(self): #類下面的run方法是固定的
print(‘%s is piaoing‘ %self.name)
time.sleep(2)
print(‘%s piao end‘ %self.name)
if __name__ == ‘__main__‘:
p=Work(‘wupeiqi‘)
p.start()
print(‘主‘)
3.3 開啟多個子進程
3.3.1 例一
from multiprocessing import Process
import time,random
def work(name):
print(‘%s is piaoing‘ %name)
time.sleep(random.randint(1,3))
print(‘%s piao end‘ %name)
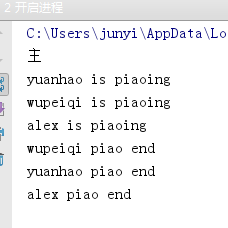
if __name__ == ‘__main__‘:
p1=Process(target=work,args=(‘alex‘,))
p2=Process(target=work,args=(‘wupeiqi‘,))
p3=Process(target=work,args=(‘yuanhao‘,))
p1.start()
p2.start()
p3.start()
print(‘主‘)
3.3.2 os.getpid()
os.getpid() 查看進程的id號
os.getppid() 查看進程的父進程的id號
from multiprocessing import Process
import time,random,os
def work():
print(‘子進程的pid:%s,父進程的pid:%s‘ %(os.getpid(),os.getppid()))
time.sleep(3)
if __name__ == ‘__main__‘:
p1=Process(target=work)
p2=Process(target=work)
p3=Process(target=work)
p1.start()
p2.start()
p3.start()
print(‘主‘,os.getpid(),os.getppid())
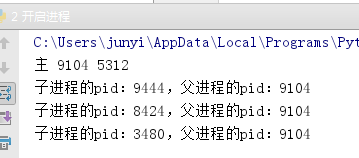
主進程的父進程是pycharm的進程號
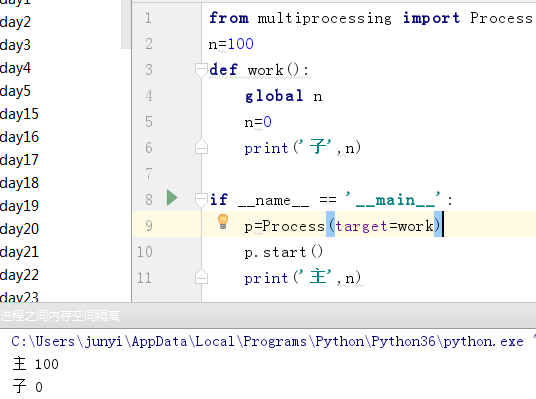
3.4 進程之間內存空間隔離
from multiprocessing import Process
n=100
def work():
global n
n=0
print(‘子‘,n)
if __name__ == ‘__main__‘:
p=Process(target=work)
p.start()
print(‘主‘,n)
4、套接字的並發
服務端:
import socket
from multiprocessing import Process
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind((‘127.0.0.1‘,8012))
phone.listen(5)
print(‘starting...‘)
def talk(conn):
print(phone)
while True: #通信循環
try:
data=conn.recv(1024) #最大收1024
print(data)
if not data:break #針對linux
conn.send(data.upper())
except Exception:
break
conn.close()
if __name__ == ‘__main__‘:
while True:
conn,addr=phone.accept()
print(‘IP:%s,PORT:%s‘ %(addr[0],addr[1]))
p=Process(target=talk,args=(conn,))
p.start()
print(‘===?>‘)
phone.close()
客戶端:
import socket
#1、買手機
phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
#2、打電話
phone.connect((‘127.0.0.1‘,8012))
#3、發收消息
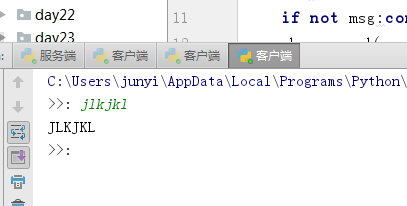
while True:
msg=input(‘>>: ‘).strip()
if not msg:continue
phone.send(msg.encode(‘utf-8‘))
data=phone.recv(1024)
print(data.decode(‘utf-8‘))
#4、掛電話
phone.close()
服務端開的進程數最好最多開的數目和cup的核數一樣多
os.cpu_count() 查看cpu核數
5、join()方法
from multiprocessing import Process
import time
def work(name,n):
print(‘%s is piaoing‘ %name)
time.sleep(n)
print(‘%s piao end‘ %name)
if __name__ == ‘__main__‘:
start_time=time.time()
p1=Process(target=work,args=(‘alex‘,1))
p2=Process(target=work,args=(‘wupeiqi‘,2))
p3=Process(target=work,args=(‘yuanhao‘,3))
# p1.start()
# p2.start()
# p3.start()
# p3.join() #主進程等,等待子進程結束後,主進程再執行後面的代碼
# p2.join() #主進程等,等待子進程結束後,主進程再執行後面的代碼
# p1.join() #主進程等,等待子進程結束後,主進程再執行後面的代碼
p_l=[p1,p2,p3]
for p in p_l:
p.start()
for p in p_l:
p.join()#主進程等,等待子進程結束後,主進程再執行後面的代碼
stop_time=time.time()
print(‘主‘,(stop_time-start_time))
6、terminate()和is_alive()(了解)
terminate() 關閉進程,不會立即關閉,所以is_alive立刻查看的結果可能還是存活,如果被關閉的進程有子進程,這個方法並不會把子進程也關閉,所以這個方法不要用
is_alive() 查看進程是否存活,True為存活,False為不存活
from multiprocessing import Process
import time
def work(name,n):
print(‘%s is piaoing‘ %name)
time.sleep(n)
print(‘%s piao end‘ %name)
if __name__ == ‘__main__‘:
p1=Process(target=work,args=(‘alex‘,1))
p1.start()
p1.terminate()
time.sleep(1)
print(p1.is_alive())
print(‘主‘)
7、name()和pid()(了解)
name()獲取進程名
pid()獲取進程pid不要用,一般用os.getpid()
8、socketserver
實現ftp server端和client端的交互
服務端:
import socketserver
class MyServer(socketserver.BaseRequestHandler):
def handle(self):
conn = self.request
conn.sendall(bytes(‘歡迎致電 10086,請輸入1xxx,0轉人工服務.‘,encoding=‘utf-8‘))
Flag = True
while Flag:
data = conn.recv(1024).decode(‘utf-8‘)
if data == ‘exit‘:
Flag = False
elif data == ‘0‘:
conn.sendall(bytes(‘通過可能會被錄音.balabala一大推‘,encoding=‘utf-8‘))
else:
conn.sendall(bytes(‘請重新輸入.‘,encoding=‘utf-8‘))
if __name__ == ‘__main__‘:
server = socketserver.ThreadingTCPServer((‘127.0.0.1‘,8008),MyServer)
server.serve_forever()
客戶端:
import socket
ip_port = (‘127.0.0.1‘,8008)
sk = socket.socket()
sk.connect(ip_port)
sk.settimeout(5)
while True:
data = sk.recv(1024).decode(‘utf-8‘)
print(‘receive:‘,data)
inp = input(‘please input:‘)
sk.sendall(bytes(inp,encoding=‘utf-8‘))
if inp == ‘exit‘:
break
sk.close()
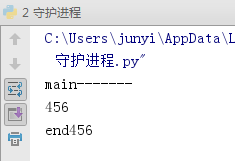
9、守護進程
主進程創建守護進程
其一:守護進程會在主進程代碼執行結束後就終止
其二:守護進程內無法再開啟子進程,否則拋出異常:AssertionError: daemonic processes are not allowed to have children
註意:進程之間是互相獨立的,主進程代碼運行結束,守護進程隨即終止
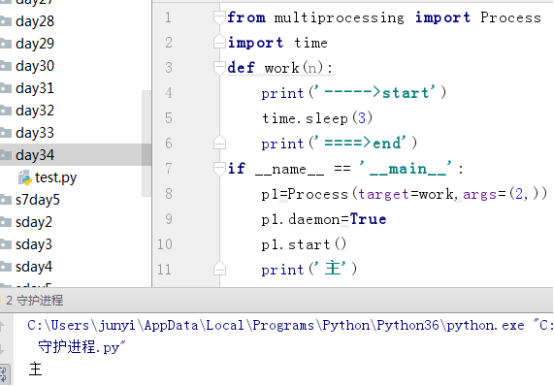
#主進程代碼運行完畢,守護進程就會結束
from multiprocessing import Process
import time
def foo():
print(123)
time.sleep(1)
print("end123")
def bar():
print(456)
time.sleep(3)
print("end456")
if __name__ == ‘__main__‘:
p1=Process(target=foo)
p2=Process(target=bar)
p1.daemon=True
p1.start()
p2.start()
print("main-------")
10、互斥鎖
進程之間數據不共享,但是共享同一套文件系統,所以訪問同一個文件,或同一個打印終端,是沒有問題的,
競爭帶來的結果就是錯亂,如何控制,就是加鎖處理
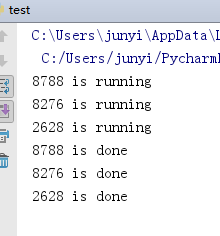
10.1 多個進程共享同一打印終端
10.1.1 不加鎖
並發運行,效率高,但競爭同一打印終端,帶來了打印錯亂
from multiprocessing import Process
import os,time
def work():
print(‘%s is running‘ %os.getpid())
time.sleep(2)
print(‘%s is done‘ %os.getpid())
if __name__ == ‘__main__‘:
for i in range(3):
p=Process(target=work)
p.start()
10.1.2 加鎖
由並發變成了串行,犧牲了運行效率,但避免了競爭
from multiprocessing import Process,Lock
import os,time
def work(lock):
lock.acquire()
print(‘%s is running‘ %os.getpid())
time.sleep(2)
print(‘%s is done‘ %os.getpid())
lock.release()
if __name__ == ‘__main__‘:
lock=Lock()
for i in range(3):
p=Process(target=work,args=(lock,))
p.start()
10.2 多個進程共享同一文件
文件當數據庫,模擬搶票
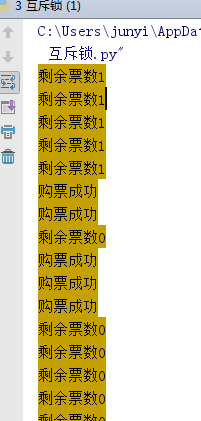
10.2.1 不加鎖
#文件db的內容為:{"count":1}
#註意一定要用雙引號,不然json無法識別
from multiprocessing import Process,Lock
import time,json,random
def search():
dic=json.load(open(‘db.txt‘))
print(‘\033[43m剩余票數%s\033[0m‘ %dic[‘count‘])
def get():
dic=json.load(open(‘db.txt‘))
time.sleep(0.1) #模擬讀數據的網絡延遲
if dic[‘count‘] >0:
dic[‘count‘]-=1
time.sleep(0.2) #模擬寫數據的網絡延遲
json.dump(dic,open(‘db.txt‘,‘w‘))
print(‘\033[43m購票成功\033[0m‘)
def task(lock):
search()
get()
if __name__ == ‘__main__‘:
lock=Lock()
for i in range(30): #模擬並發100個客戶端搶票
p=Process(target=task,args=(lock,))
p.start()
10.2.2 加鎖
購票行為由並發變成了串行,犧牲了運行效率,但保證了數據安全
#文件db的內容為:{"count":1}
#註意一定要用雙引號,不然json無法識別
from multiprocessing import Process,Lock
import time,json,random
def search():
dic=json.load(open(‘db.txt‘))
print(‘\033[43m剩余票數%s\033[0m‘ %dic[‘count‘])
def get():
dic=json.load(open(‘db.txt‘))
time.sleep(0.1) #模擬讀數據的網絡延遲
if dic[‘count‘] >0:
dic[‘count‘]-=1
time.sleep(0.2) #模擬寫數據的網絡延遲
json.dump(dic,open(‘db.txt‘,‘w‘))
print(‘\033[43m購票成功\033[0m‘)
def task(lock):
search()
lock.acquire()
get()
lock.release()
if __name__ == ‘__main__‘:
lock=Lock()
for i in range(5): #模擬並發100個客戶端搶票
p=Process(target=task,args=(lock,))
p.start()

10.3 總結
#加鎖可以保證多個進程修改同一塊數據時,同一時間只能有一個任務可以進行修改,即串行的修改,沒錯,速度是慢了,但犧牲了速度卻保證了數據安全。
雖然可以用文件共享數據實現進程間通信,但問題是:
1.效率低(共享數據基於文件,而文件是硬盤上的數據)
2.需要自己加鎖處理
#因此我們最好找尋一種解決方案能夠兼顧:1、效率高(多個進程共享一塊內存的數據)2、幫我們處理好鎖問題。這就是mutiprocessing模塊為我們提供的基於消息的IPC通信機制:隊列和管道。
11、隊列
#1 隊列和管道都是將數據存放於內存中
#2 隊列又是基於(管道+鎖)實現的,可以讓我們從復雜的鎖問題中解脫出來,
我們應該盡量避免使用共享數據,盡可能使用消息傳遞和隊列,避免處理復雜的同步和鎖問題,而且在進程數目增多時,往往可以獲得更好的可獲展性。
11.1 創建隊列的類
Queue([maxsize]):創建共享的進程隊列,Queue是多進程安全的隊列,可以使用Queue實現多進程之間的數據傳遞。
參數:maxsize是隊列中允許最大項數,省略則無大小限制。
11.2 主要方法
11.2.1 q.put()
用以插入數據到隊列中,put方法還有兩個可選參數:blocked和timeout。如果blocked為True(默認值),並且timeout為正值,該方法會阻塞timeout指定的時間,直到該隊列有剩余的空間。如果超時,會拋出Queue.Full異常。如果blocked為False,但該Queue已滿,會立即拋出Queue.Full異常。
11.2.2 q.get()
可以從隊列讀取並且刪除一個元素。同樣,get方法有兩個可選參數:blocked和timeout。如果blocked為True(默認值),並且timeout為正值,那麽在等待時間內沒有取到任何元素,會拋出Queue.Empty異常。如果blocked為False,有兩種情況存在,如果Queue有一個值可用,則立即返回該值,否則,如果隊列為空,則立即拋出Queue.Empty異常.
11.2.3 q.get_nowait()
同q.get(False)
11.2.4 q.put_nowait()
同q.put(False)
11.2.5 q.empty()
調用此方法時q為空則返回True,該結果不可靠,比如在返回True的過程中,如果隊列中又加入了項目。
11.2.6 q.full()
調用此方法時q已滿則返回True,該結果不可靠,比如在返回True的過程中,如果隊列中的項目被取走。
11.2.7 q.qsize()
返回隊列中目前項目的正確數量,結果也不可靠,理由同q.empty()和q.full()一樣
11.3 應用
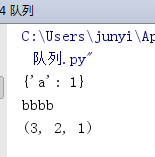
from multiprocessing import Queue
q=Queue(3)
q.put({‘a‘:1})
q.put(‘bbbb‘)
q.put((3,2,1))
# q.put_nowait(1111111)
print(q.get())
print(q.get())
print(q.get())
# print(q.get_nowait())
12、生產者消費者模型
在並發編程中使用生產者和消費者模式能夠解決絕大多數並發問題。該模式通過平衡生產線程和消費線程的工作能力來提高程序的整體處理數據的速度。
生產者:生產數據
消費者:處理數據
生產者消費者模型:解耦,加入隊列,解決生產者與消費者之間的速度差

from multiprocessing import Queue,Process
import time,random
def producer(name,q):
for i in range(10):
time.sleep(random.randint(1,3))
res=‘泔水%s‘ %i
q.put(res)
print(‘廚師 %s 生產了 %s‘ %(name,res))
def consumer(name,q):
while True:
res=q.get()
if res is None:break
time.sleep(random.randint(1,3))
print(‘%s 吃了 %s‘ %(name,res))
if __name__ == ‘__main__‘:
q=Queue()
p1=Process(target=producer,args=(‘egon‘,q))
c1=Process(target=consumer,args=(‘alex‘,q))
p1.start()
c1.start()
p1.join()
q.put(None)

13、joinablequeue
from multiprocessing import JoinableQueue,Process
import time,random
def producer(name,q,food):
for i in range(1):
time.sleep(random.randint(1,3))
res=‘%s%s‘ %(food,i)
q.put(res)
print(‘廚師 %s 生產了 %s‘ %(name,res))
q.join()
def consumer(name,q):
while True:
res=q.get()
if res is None:break
time.sleep(random.randint(1,3))
print(‘%s 吃了 %s‘ %(name,res))
q.task_done() # 隊列中減一個
if __name__ == ‘__main__‘:
q=JoinableQueue()
p1=Process(target=producer,args=(1,q,‘泔水‘))
p2=Process(target=producer,args=(2,q,‘骨頭‘))
p3=Process(target=producer,args=(3,q,‘饅頭‘))
c1=Process(target=consumer,args=(‘alex‘,q))
c2=Process(target=consumer,args=(‘wupeiqi‘,q))
c1.daemon=True
c2.daemon=True
p1.start()
p2.start()
p3.start()
c1.start()
c2.start()
p1.join()
p2.join()
p3.join()
14、共享內存
from multiprocessing import Manager,Process,Lock
def work(d,lock):
with lock:
temp=d[‘count‘]
d[‘count‘]=temp-1
if __name__ == ‘__main__‘:
m=Manager()
d=m.dict({"count":100})
# m.list()
lock=Lock()
p_l=[]
for i in range(100):
p=Process(target=work,args=(d,lock))
p_l.append(p)
p.start()
for obj in p_l:
obj.join()
print(d)
15、進程池
15.1 創建進程池的類
如果指定numprocess為3,則進程池會從無到有創建三個進程,然後自始至終使用這三個進程去執行所有任務,不會開啟其他進程
Pool([numprocess [,initializer [, initargs]]]):創建進程池
#為什麽要用進程池:為了實現並發,然後在並發的基礎上對進程數目進行控制
15.2 參數介紹
1 numprocess:要創建的進程數,如果省略,將默認使用cpu_count()的值
2 initializer:是每個工作進程啟動時要執行的可調用對象,默認為None
3 initargs:是要傳給initializer的參數組
15.3 主要方法
15.3.1 p.apply(func [, args [, kwargs]])
同步調用:提交完任務後,在原地等待任務結束,一旦結束可以立刻拿到結果
在一個池工作進程中執行func(*args,**kwargs),然後返回結果。需要強調的是:此操作並不會在所有池工作進程中並執行func函數。如果要通過不同參數並發地執行func函數,必須從不同線程調用p.apply()函數或者使用p.apply_async()
15.3.2 p.apply_async(func [, args [, kwargs]])
異步調用:提交完任務後,不會在原地等待任務結束,會繼續提交下一次任務,等到所有任務都結束後,才get結果
在一個池工作進程中執行func(*args,**kwargs),然後返回結果。此方法的結果是AsyncResult類的實例,callback是可調用對象,接收輸入參數。當func的結果變為可用時,將理解傳遞給callback。callback禁止執行任何阻塞操作,否則將接收其他異步操作中的結果。
15.3.3 p.close()
關閉進程池,防止進一步操作。如果所有操作持續掛起,它們將在工作進程終止前完成
15.3.4 p.jion()
等待所有工作進程退出。此方法只能在close()或teminate()之後調用
15.4 四種狀態
15.4.1 同步調用
提交完任務後,在原地等待任務結束,一旦結束可以立刻拿到結果
15.4.2 阻塞
正在運行的進程遇到io則進入阻塞狀態
15.4.3 異步調用
提交完任務後,不會在原地等待任務結束,會繼續提交下一次任務,等到所有任務都結束後,才get結果
15.4.4 非阻塞
可能是運行狀態,也可能是就緒狀態
15.5 例
from multiprocessing import Pool
import os,time,random
def work(n):
print(‘%s is working‘ %os.getpid())
# time.sleep(random.randint(1,3))
return n**2
if __name__ == ‘__main__‘:
p=Pool(2)
objs=[]
for i in range(10):
# 同步調用:提交完任務後,在原地等待任務結束,一旦結束可以立刻拿到結果
# res=p.apply(work,args=(i,))
# print(res)
# 異步調用:提交完任務後,不會在原地等待任務結束,會繼續提交下一次任務,等到所有任務都結束後,才get結果
obj=p.apply_async(work,args=(i,))
objs.append(obj)
p.close()
p.join()
for obj in objs:
print(obj.get())
print(‘主‘)
16、回調函數
需要回調函數的場景:進程池中任何一個任務一旦處理完了,就立即告知主進程:我好了額,你可以處理我的結果了。主進程則調用一個函數去處理該結果,該函數即回調函數
我們可以把耗時間(阻塞)的任務放到進程池中,然後指定回調函數(主進程負責執行),這樣主進程在執行回調函數時就省去了I/O的過程,直接拿到的是任務的結果。
#obj=p.apply_async(get,args=(url,),callback=parse)
from multiprocessing import Pool,Process
import requests
import os
import time,random
def get(url):
print(‘%s GET %s‘ %(os.getpid(),url))
response=requests.get(url)
time.sleep(random.randint(1,3))
if response.status_code == 200:
print(‘%s DONE %s‘ % (os.getpid(), url))
return {‘url‘:url,‘text‘:response.text}
def parse(dic):
print(‘%s PARSE %s‘ %(os.getpid(),dic[‘url‘]))
time.sleep(1)
res=‘%s:%s\n‘ %(dic[‘url‘],len(dic[‘text‘]))
with open(‘db.txt‘,‘a‘) as f:
f.write(res)
if __name__ == ‘__main__‘:
urls=[
‘https://www.baidu.com‘,
‘https://www.python.org‘,
‘https://www.openstack.org‘,
‘https://help.github.com/‘,
‘http://www.sina.com.cn/‘
]
p=Pool(2)
start_time=time.time()
objs=[]
for url in urls:
obj=p.apply_async(get,args=(url,),callback=parse) #主進程負責幹回調函數的活
objs.append(obj)
p.close()
p.join()
print(‘主‘,(time.time()-start_time))
12、python全棧之路-並發編程之多進程