
Streaming SQL for Apache Kafka
KSQL是基於Kafka的Streams API進行構建的流式SQL引擎,KSQL降低了進入流處理的門檻,提供了一個簡單的、完全交互式的SQL接口,用於處理Kafka的數據。 KSQL是一套基於Apache 2.0許可開源的、分布式的、可擴展的、可靠的和實時的組件。支持多種流式操作,包括聚合(aggregate)、連接(join)、時間窗口(window)、會話(session)等等。KSQL的兩個核心概念是流(Stream)和表(Table)【參見:http://www.cnblogs.com/tgzhu/p/7660838.html】,集成流和表,允許將代表當前狀態的表與代表當前發生事件的流連接在一起。
KSQL項目介紹
事實上,KSQL與關系型數據庫中的SQL還是有很大不同的。傳統的SQL都是即時的一次性操作,不管是查詢還是更新都是在當前的數據集上進行。KSQL的查詢和更新是持續進行的,而且數據集可以源源不斷地增加。簡言之,KSQL所做的其實是轉換操作,也就是流式處理。 項目目前還處於開發者預覽階段,在可預料的條件下,KSQL在實時監控、安全檢測、在線數據集成、應用開發等場景擁有極大的潛力,具體介紹如下:
1、實時監控實時分析
CREATE TABLE error_counts AS
SELECT error_code, count(*)FROM monitoring_stream
WINDOW TUMBLING (SIZE
其中的一個用途是定義定制的業務級度量,這些度量是實時計算的,您可以監視和警報,就像您的CPU負載一樣。另一個用途是在KSQL中定義應用程序的正確性的概念,並檢查它在生產過程中是否會遇到這個問題。通常,當我們想到監控時,我們會想到計數器和儀表跟蹤低水平的性能統計。這些類型的測量器通常可以告訴你CPU負載很高,但是它們不能真正告訴你你的應用程序是否在做它應該做的事情。KSQL允許從應用程序生成的原始事件流中定義定制指標,無論它們是日誌事件、數據庫更新還是其他類型的事件。
例如,一個web應用程序可能需要檢查,每次新客戶註冊一個受歡迎的電子郵件,創建一個新的用戶記錄,並且他們的信用卡被計費。這些功能可能分布在不同的服務或應用程序中,您可能希望監視每個新客戶在SLA中發生的每一件事,比如30秒。
2、安全性和異常檢測
CREATE STREAM possible_fraud AS
SELECT card_number, count(*)
FROM authorization_attempts
WINDOW TUMBLING (SIZE 5 SECONDS)
GROUP BY card_number
HAVING count(*) > 3;
KSQL把事件流轉換成包含數值的時間序列數據,通過可視化工具把這些數據展示在UI上,可以檢測到很多威脅安全的行為,比如欺詐、入侵等等
3、在線數據集成
CREATE STREAM vip_users AS
SELECT userid, page, action
FROM clickstream c
LEFT JOIN users u ON c.userid = u.user_id
WHERE u.level = ‘Platinum‘;
大部分的數據處理都會經歷 ETL(Extract—Transform—Load)這樣的過程,而這樣的系統通常都是通過定時的批次作業來完成數據處理的,但批次作業所帶來的延時在很多時候是無法被接受的。而通過使用 KSQL 和 Kafka 連接器,可以將批次數據集成轉變成在線數據集成。比如,通過流與表的連接,可以用存儲在數據表裏的元數據來填充事件流裏的數據,或者在將數據傳輸到其他系統之前過濾掉數據裏的敏感信息。
4、應用開發
對於復雜的應用來說,使用 Kafka 的原生 Streams API 或許會更合適。不過,對於簡單的應用來說,或者對於不喜歡 Java 編程的人來說,KSQL 會是更好的選擇。
KSQL架構
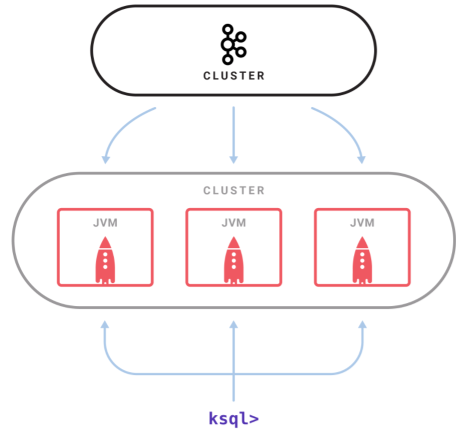
- KSQL 是一個獨立運行的服務器,多個 KSQL 服務器可以組成集群,可以動態地添加服務器實例。
- 集群具有容錯機制,如果一個服務器失效,其他服務器就會接管它的工作。
- KSQL 命令行客戶端通過 REST API 向集群發起查詢操作,可以查看流和表的信息、查詢數據以及查看查詢狀態。
- 因為是基於 Streams API 構建的,所以 KSQL 也沿襲了 Streams API 的彈性、狀態管理和容錯能力,同時也具備了僅一次(exactly once)語義。KSQL 服務器內嵌了這些特性,並增加了一個分布式 SQL 引擎、用於提升查詢性能的自動字節碼生成機制,以及用於執行查詢和管理的 REST API。
KSQL中的核心抽象
KSQL在內部使用Kafka的Streams API,並且它們共享與Kafka流處理相同的核心抽象。 KSQL有兩個核心抽象,它們映射到Kafka Streams中的兩個核心抽象,並允許您操縱Kafka主題:
1、流:流是無限制的結構化數據序列(“事實”)。 示例 :一個金融交易流,“Alice向Bob發送了100美元,然後查理向鮑勃發送了50美元”。 流中的事實是不可變的,這意味著可以將新事實插入到流中,但是現有事實永遠不會被更新或刪除。 流可以從Kafka主題創建,或者從現有的流和表中派生。
CREATE STREAM pageviews (viewtime BIGINT, userid VARCHAR, pageid VARCHAR)
WITH (kafka_topic=‘pageviews‘, value_format=’JSON’);
2、表:一個表是一個流或另一個表的視圖,它代表了一個不斷變化的事實的集合。示例 :一個包含最新財務信息的表, “Bob的經常帳戶余額為$150”。它相當於傳統的數據庫表,但通過流化等流語義來豐富。表中的事實是可變的,這意味著可以將新的事實插入到表中,現有的事實可以被更新或刪除。可以從Kafka主題中創建表,也可以從現有的流和表中派生表。
CREATE TABLE users (registertime BIGINT, gender VARCHAR, regionid VARCHAR, userid VARCHAR)
WITH (kafka_topic=‘users‘, value_format=‘DELIMITED‘);
KSQL簡化了流應用程序,因為它完全集成了表和流的概念,允許使用表示現在發生的事件的流來連接表示當前狀態的表。 Apache Kafka中的一個主題可以表示為KSQL中的STREAM或TABLE,具體取決於主題處理的預期語義。 例如,如果要將主題中的數據作為一系列獨立值讀取,則可以使用CREATE STREAM。此類流的一個例子是捕獲頁面視圖事件,其中每個頁面視圖事件都不相關且獨立於另一個頁面視圖事件。另一方面,如果您希望將某個主題中的數據讀取為可更新的值的集合,那麽您將使用CREATE TABLE。在KSQL中應該讀取一個主題的示例,它捕獲用戶元數據,其中每個事件代表特定用戶id的最新元數據,如用戶的姓名、地址或首選項。
參考資料:
- https://github.com/confluentinc/ksql
- https://www.confluent.io/product/ksql/
- http://geek.csdn.net/news/detail/235801
Streaming SQL for Apache Kafka