
Java並發--並發容器之ConcurrentHashMap
下面這部分內容轉載自:
http://www.haogongju.net/art/2350374
JDK5中添加了新的concurrent包,相對同步容器而言,並發容器通過一些機制改進了並發性能。因為同步容器將所有對容器狀態的訪問都
串行化了,這樣保證了線程的安全性,所以這種方法的代價就是嚴重降低了並發性,當多個線程競爭容器時,吞吐量嚴重降低。因此Java5.0開
始針對多線程並發訪問設計,提供了並發性能較好的並發容器,引入了java.util.concurrent包。與Vector和Hashtable、
Collections.synchronizedXxx()同步容器等相比,util.concurrent中引入的並發容器主要解決了兩個問題:
1)根據具體場景進行設計,盡量避免synchronized,提供並發性。
2)定義了一些並發安全的復合操作,並且保證並發環境下的叠代操作不會出錯。
util.concurrent中容器在叠代時,可以不封裝在synchronized中,可以保證不拋異常,但是未必每次看到的都是"最新的、當前的"數據。
下面是對並發容器的簡單介紹:
ConcurrentHashMap代替同步的Map(Collections.synchronized(new HashMap())),眾所周知,HashMap是根據散列值分段存儲的,同步Map在同步的時候鎖住了所有的段,而ConcurrentHashMap加鎖的時候根據散列值鎖住了散列值鎖對應的那段,因此提高了並發性能。ConcurrentHashMap也增加了對常用復合操作的支持,比如"若沒有則添加":putIfAbsent(),替換:replace()。這2個操作都是原子操作。
CopyOnWriteArrayList和CopyOnWriteArraySet分別代替List和Set,主要是在遍歷操作為主的情況下來代替同步的List和同步的Set,這也就是上面所述的思路:叠代過程要保證不出錯,除了加鎖,另外一種方法就是"克隆"容器對象。
ConcurrentLinkedQuerue是一個先進先出的隊列。它是非阻塞隊列。
ConcurrentSkipListMap可以在高效並發中替代SoredMap(例如用Collections.synchronzedMap包裝的TreeMap)。
ConcurrentSkipListSet可以在高效並發中替代SoredSet(例如用Collections.synchronzedSet包裝的TreeMap)。
本篇文章著重講解2個並發容器:ConcurrentHashMap和CopyOnWriteArrayList其中的ConcurrentHashMap,CopyOnWriteArrayList在下一篇文章中講述。
原文鏈接:http://www.iteye.com/topic/1103980
大家都知道HashMap是非線程安全的,Hashtable是線程安全的,但是由於Hashtable是采用synchronized進行同步,相當於所有線程進行讀寫時都去競爭一把鎖,導致效率非常低下。
ConcurrentHashMap可以做到讀取數據不加鎖,並且其內部的結構可以讓其在進行寫操作的時候能夠將鎖的粒度保持地盡量地小,不用對整個ConcurrentHashMap加鎖。
ConcurrentHashMap的內部結構
ConcurrentHashMap為了提高本身的並發能力,在內部采用了一個叫做Segment的結構,一個Segment其實就是一個類Hash Table的結構,Segment內部維護了一個鏈表數組,我們用下面這一幅圖來看下ConcurrentHashMap的內部結構:
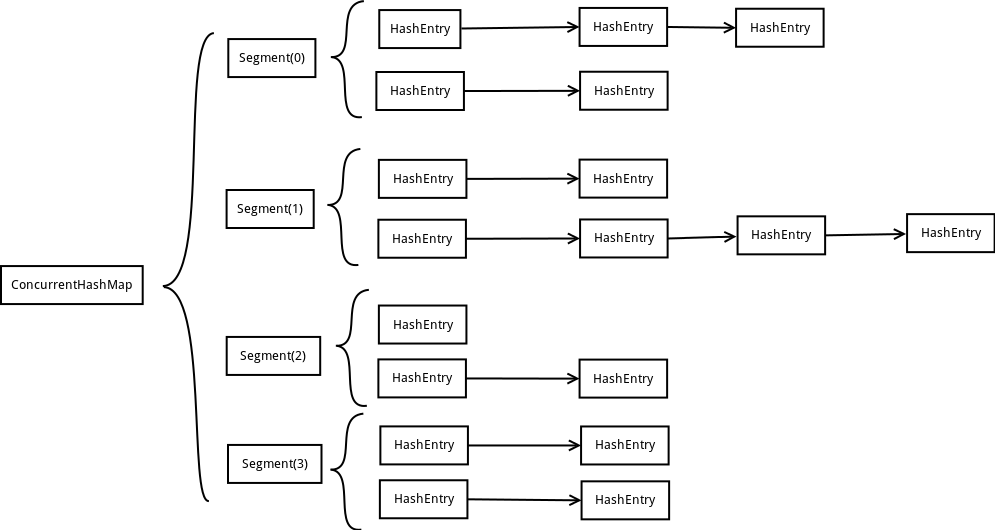
從上面的結構我們可以了解到,ConcurrentHashMap定位一個元素的過程需要進行兩次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的鏈表的頭部,因此,這一種結構的帶來的副作用是Hash的過程要比普通的HashMap要長,但是帶來的好處是寫操作的時候可以只對元素所在的Segment進行加鎖即可,不會影響到其他的Segment,這樣,在最理想的情況下,ConcurrentHashMap可以最高同時支持Segment數量大小的寫操作(剛好這些寫操作都非常平均地分布在所有的Segment上),所以,通過這一種結構,ConcurrentHashMap的並發能力可以大大的提高。
Segment
我們再來具體了解一下Segment的數據結構:
1 static final class Segment<K,V> extends ReentrantLock implements Serializable {
2 transient volatile int count;
3 transient int modCount;
4 transient int threshold;
5 transient volatile HashEntry<K,V>[] table;
6 final float loadFactor;
7 }
詳細解釋一下Segment裏面的成員變量的意義:
- count:Segment中元素的數量
- modCount:對table的大小造成影響的操作的數量(比如put或者remove操作)
- threshold:閾值,Segment裏面元素的數量超過這個值依舊就會對Segment進行擴容
- table:鏈表數組,數組中的每一個元素代表了一個鏈表的頭部
- loadFactor:負載因子,用於確定threshold
HashEntry
Segment中的元素是以HashEntry的形式存放在鏈表數組中的,看一下HashEntry的結構:
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
可以看到HashEntry的一個特點,除了value以外,其他的幾個變量都是final的,這樣做是為了防止鏈表結構被破壞,出現ConcurrentModification的情況。
ConcurrentHashMap的初始化
下面我們來結合源代碼來具體分析一下ConcurrentHashMap的實現,先看下初始化方法:
1 public ConcurrentHashMap(int initialCapacity,
2 float loadFactor, int concurrencyLevel) {
3 if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
4 throw new IllegalArgumentException();
5
6 if (concurrencyLevel > MAX_SEGMENTS)
7 concurrencyLevel = MAX_SEGMENTS;
8
9 // Find power-of-two sizes best matching arguments
10 int sshift = 0;
11 int ssize = 1;
12 while (ssize < concurrencyLevel) {
13 ++sshift;
14 ssize <<= 1;
15 }
16 segmentShift = 32 - sshift;
17 segmentMask = ssize - 1;
18 this.segments = Segment.newArray(ssize);
19
20 if (initialCapacity > MAXIMUM_CAPACITY)
21 initialCapacity = MAXIMUM_CAPACITY;
22 int c = initialCapacity / ssize;
23 if (c * ssize < initialCapacity)
24 ++c;
25 int cap = 1;
26 while (cap < c)
27 cap <<= 1;
28
29 for (int i = 0; i < this.segments.length; ++i)
30 this.segments[i] = new Segment<K,V>(cap, loadFactor);
31 }
CurrentHashMap的初始化一共有三個參數,一個initialCapacity,表示初始的容量,一個loadFactor,表示負載參數,最後一個是concurrentLevel,代表ConcurrentHashMap內部的Segment的數量,ConcurrentLevel一經指定,不可改變,後續如果ConcurrentHashMap的元素數量增加導致ConrruentHashMap需要擴容,ConcurrentHashMap不會增加Segment的數量,而只會增加Segment中鏈表數組的容量大小,這樣的好處是擴容過程不需要對整個ConcurrentHashMap做rehash,而只需要對Segment裏面的元素做一次rehash就可以了。
整個ConcurrentHashMap的初始化方法還是非常簡單的,先是根據concurrentLevel來new出Segment,這裏Segment的數量是不大於concurrentLevel的最大的2的指數,就是說Segment的數量永遠是2的指數個,這樣的好處是方便采用移位操作來進行hash,加快hash的過程。接下來就是根據intialCapacity確定Segment的容量的大小,每一個Segment的容量大小也是2的指數,同樣使為了加快hash的過程。
這邊需要特別註意一下兩個變量,分別是segmentShift和segmentMask,這兩個變量在後面將會起到很大的作用,假設構造函數確定了Segment的數量是2的n次方,那麽segmentShift就等於32減去n,而segmentMask就等於2的n次方減一。
ConcurrentHashMap的get操作
前面提到過ConcurrentHashMap的get操作是不用加鎖的,我們這裏看一下其實現:
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
看第三行,segmentFor這個函數用於確定操作應該在哪一個segment中進行,幾乎對ConcurrentHashMap的所有操作都需要用到這個函數,我們看下這個函數的實現:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
這個函數用了位操作來確定Segment,根據傳入的hash值向右無符號右移segmentShift位,然後和segmentMask進行與操作,結合我們之前說的segmentShift和segmentMask的值,就可以得出以下結論:假設Segment的數量是2的n次方,根據元素的hash值的高n位就可以確定元素到底在哪一個Segment中。
在確定了需要在哪一個segment中進行操作以後,接下來的事情就是調用對應的Segment的get方法:
1 V get(Object key, int hash) {
2 if (count != 0) { // read-volatile
3 HashEntry<K,V> e = getFirst(hash);
4 while (e != null) {
5 if (e.hash == hash && key.equals(e.key)) {
6 V v = e.value;
7 if (v != null)
8 return v;
9 return readValueUnderLock(e); // recheck
10 }
11 e = e.next;
12 }
13 }
14 return null;
15 }
先看第二行代碼,這裏對count進行了一次判斷,其中count表示Segment中元素的數量,我們可以來看一下count的定義:
transient volatile int count;
可以看到count是volatile的,實際上這裏裏面利用了volatile的語義:
對volatile字段的寫入操作happens-before於每一個後續的同一個字段的讀操作。因為實際上put、remove等操作也會更新count的值,所以當競爭發生的時候,volatile的語義可以保證寫操作在讀操作之前,也就保證了寫操作對後續的讀操作都是可見的,這樣後面get的後續操作就可以拿到完整的元素內容。
然後,在第三行,調用了getFirst()來取得鏈表的頭部:
HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
return tab[hash & (tab.length - 1)];
}
同樣,這裏也是用位操作來確定鏈表的頭部,hash值和HashTable的長度減一做與操作,最後的結果就是hash值的低n位,其中n是HashTable的長度以2為底的結果。
在確定了鏈表的頭部以後,就可以對整個鏈表進行遍歷,看第4行,取出key對應的value的值,如果拿出的value的值是null,則可能這個key,value對正在put的過程中,如果出現這種情況,那麽就加鎖來保證取出的value是完整的,如果不是null,則直接返回value。
ConcurrentHashMap的put操作
看完了get操作,再看下put操作,put操作的前面也是確定Segment的過程,這裏不再贅述,直接看關鍵的segment的put方法:
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
首先對Segment的put操作是加鎖完成的,然後在第五行,如果Segment中元素的數量超過了閾值(由構造函數中的loadFactor算出)這需要進行對Segment擴容,並且要進行rehash,關於rehash的過程大家可以自己去了解,這裏不詳細講了。
第8和第9行的操作就是getFirst的過程,確定鏈表頭部的位置。
第11行這裏的這個while循環是在鏈表中尋找和要put的元素相同key的元素,如果找到,就直接更新更新key的value,如果沒有找到,則進入21行這裏,生成一個新的HashEntry並且把它加到整個Segment的頭部,然後再更新count的值。
ConcurrentHashMap的remove操作
Remove操作的前面一部分和前面的get和put操作一樣,都是定位Segment的過程,然後再調用Segment的remove方法:
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}
首先remove操作也是確定需要刪除的元素的位置,不過這裏刪除元素的方法不是簡單地把待刪除元素的前面的一個元素的next指向後面一個就完事了,我們之前已經說過HashEntry中的next是final的,一經賦值以後就不可修改,在定位到待刪除元素的位置以後,程序就將待刪除元素前面的那一些元素全部復制一遍,然後再一個一個重新接到鏈表上去,看一下下面這一幅圖來了解這個過程:

假設鏈表中原來的元素如上圖所示,現在要刪除元素3,那麽刪除元素3以後的鏈表就如下圖所示:

ConcurrentHashMap的size操作
在前面的章節中,我們涉及到的操作都是在單個Segment中進行的,但是ConcurrentHashMap有一些操作是在多個Segment中進行,比如size操作,ConcurrentHashMap的size操作也采用了一種比較巧的方式,來盡量避免對所有的Segment都加鎖。
前面我們提到了一個Segment中的有一個modCount變量,代表的是對Segment中元素的數量造成影響的操作的次數,這個值只增不減,size操作就是遍歷了兩次Segment,每次記錄Segment的modCount值,然後將兩次的modCount進行比較,如果相同,則表示期間沒有發生過寫入操作,就將原先遍歷的結果返回,如果不相同,則把這個過程再重復做一次,如果再不相同,則就需要將所有的Segment都鎖住,然後一個一個遍歷了,具體的實現大家可以看ConcurrentHashMap的源碼,這裏就不貼了。
另外2篇講述關於ConcurrentHashMap原理的兩篇文章:
《ConcurrentHashMap之實現細節》:http://www.iteye.com/topic/344876
《聊聊並發(四)深入分析ConcurrentHashMap》:http://ifeve.com/ConcurrentHashMap/
Java並發--並發容器之ConcurrentHashMap