
Hadoop(十二)MapReduce概述
前言
前面以前把關於HDFS集群的所有知識給講解完了,接下來給大家分享的是MapReduce這個Hadoop的並行計算框架。
一、背景
1)爆炸性增長的Web規模數據量
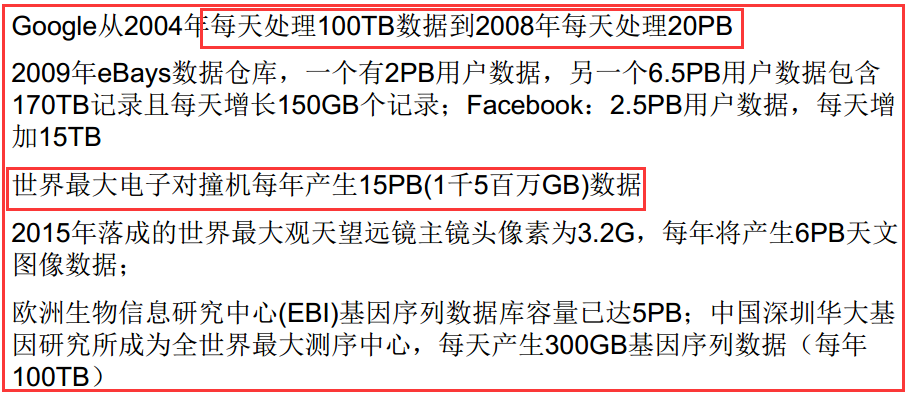
2)超大的計算量/計算復雜度

3)並行計算大趨所勢

二、大數據的並行計算
1)一個大數據若可以分為具有同樣計算過程的數據塊,並且這些數據塊之間不存在數據依賴關系,則提高處理速度最好的辦法就是並行計算。
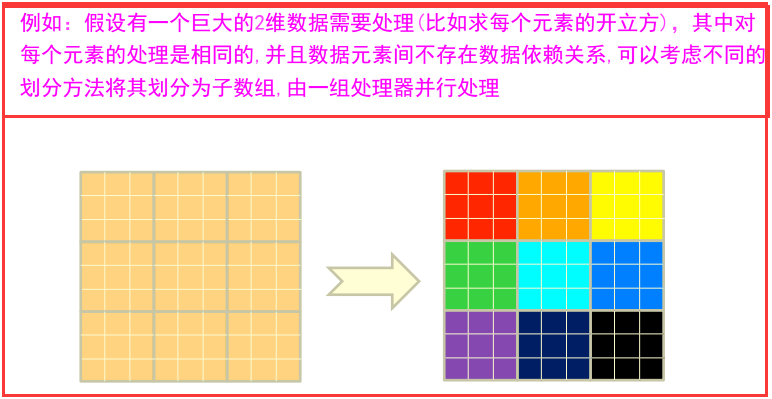
2)大數據並行計算
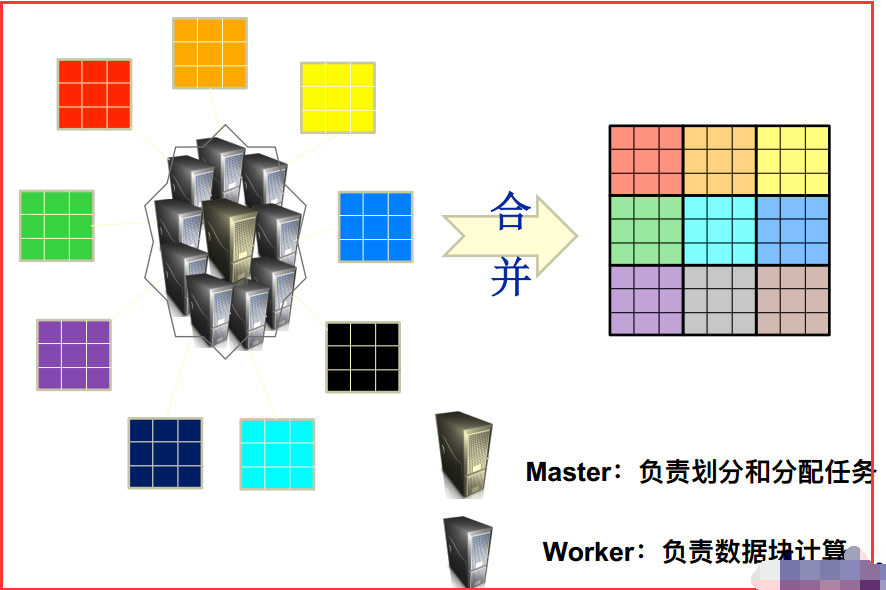
三、Hadoop的MapReduce概述
3.1、需要MapReduce原因

3.2、MapReduce簡介
1)產生MapReduce背景

2)整體認識
MapReduce是一種編程模型,用於大規模數據集(大於1TB)的並行運算,用於解決海量數據的計算問題。
MapReduce分成了兩個部分:
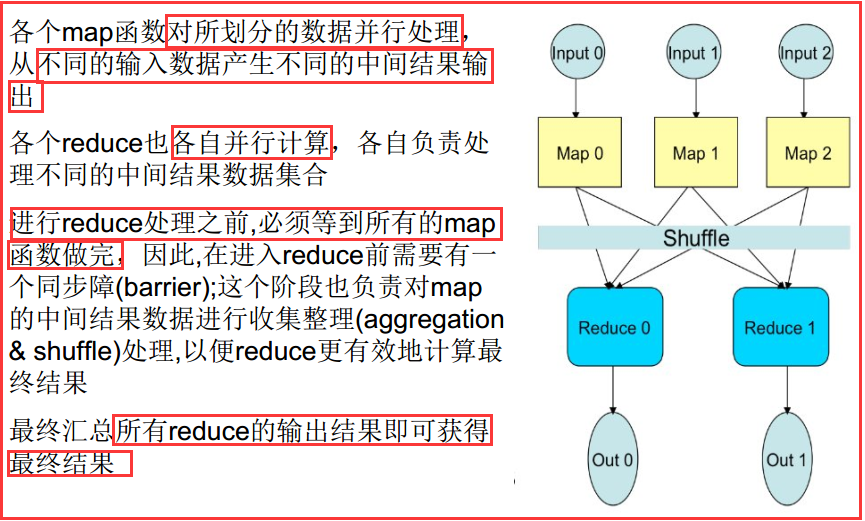
1)映射(Mapping)對集合裏的每個目標應用同一個操作。即,如果你想把表單裏每個單元格乘以二,那麽把這個函數單獨地應用在每個單元格上的操作就屬於mapping。
2)化簡(Reducing)遍歷集合中的元素來返回一個綜合的結果。即,輸出表單裏一列數字的和這個任務屬於reducing。
你向MapReduce框架提交一個計算作業時,它會首先把計算作業拆分成若幹個Map任務,然後分配到不同的節點上去執行,
Reduce任務的主要目標就是把前面若幹個Map的輸出匯總到一起並輸出。
MapReduce的偉大之處就在於編程人員在不會分布式並行編程的情況下,將自己的程序運行在分布式系統上。
3.3、MapReduce編程模型
1)MapReduce借鑒了函數式程序設計語言Lisp中的思想,定義了如下的Map和Reduce兩個抽象的編程接口。由用戶去編程實現:

註意:Map是一行一行去處理數據的。
2)詳細的處理過程
四、編寫MapReduce程序
4.1、數據樣式與環境
1)環境
我使用的是Maven,前面 有我配置的pom.xml文件。
2)數據樣式
這是一個專利引用文件,格式是這樣的:
專利ID:被引用專利ID
1,2
1,3
2,3
3,4
2,4
4.2、需求分析
1)需求
計算出被引用專利的次數
2)分析
從上面的數據分析出,我們需要的是一行數據中的後一個數據。分析一下:
在map函數中,輸入端v1代表的是一行數據,輸出端的k2可以代表是被引用的專利,在一行數據中所以v2可以被賦予為1。
在reduce函數中,k2還是被引用的專利,而[v2]是一個數據集,這裏是將k2相同的鍵的v2數據合並起來。最後輸出的是自己需要的數據k3代表的是被引用的專利,v3是引用的次數。
畫圖分析:

4.3、代碼實現
1)編寫一個解析類,用來解析數據文件中一行一行的數據。
import org.apache.hadoop.io.Text; public class PatentRecordParser { //1,2 //1,3 //2,3 //表示數據中的第一列 private String patentId; //表示數據中的第二列 private String refPatentId; //表示解析的當前行的數據是否有效 private boolean valid; public void parse(String line){ String[] strs = line.split(","); if (strs.length==2){ patentId = strs[0].trim(); refPatentId = strs[1].trim(); if (patentId.length()>0&&refPatentId.length()>0){ valid = true; } } } public void parse(Text line){ parse(line.toString()); } public String getPatentId() { return patentId; } public void setPatentId(String patentId) { this.patentId = patentId; } public String getRefPatentId() { return refPatentId; } public void setRefPatentId(String refPatentId) { this.refPatentId = refPatentId; } public boolean isValid() { return valid; } public void setValid(boolean valid) { this.valid = valid; } }
2)編寫PatentReference_0011去實現真正的計算
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; public class PatentReference_0011 extends Configured implements Tool { //-Dinput=/data/patent/cite75_99.txt public static class PatentMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ private PatentRecordParser parser = new PatentRecordParser(); private Text key = new Text(); //把進入reduce的value都設置成1 private IntWritable value = new IntWritable(1); //進入map端的數據,每次進入一行。 //MapReduce都是具有一定結構的數據,有一定含義的數據。 //進入時候map的k1(該行數據首個字符距離整個文檔首個字符的距離),v1(這行數據的字符串) @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { parser.parse(value); if (parser.isValid()){ this.key.set(parser.getRefPatentId()); context.write(this.key,this.value); } } } public static class PatentReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable iw:values){ count+=iw.get(); } context.write(key,new IntWritable(count)); //註意:在map或reduce上面的打印語句是沒有辦法輸出的,但會記錄到日誌文件當中。 } } @Override public int run(String[] args) throws Exception { //構建作業所處理的數據的輸入輸出路徑 Configuration conf = getConf(); Path input = new Path(conf.get("input")); Path output = new Path(conf.get("output")); //構建作業配置 Job job = Job.getInstance(conf,this.getClass().getSimpleName()+"Lance");//如果不指定取的名字就是當前類的類全名 //設置該作業所要執行的類 job.setJarByClass(this.getClass()); //設置自定義的Mapper類以及Map端數據輸出時的類型 job.setMapperClass(PatentMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //設置自定義的Reducer類以及輸出時的類型 job.setReducerClass(PatentReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //設置讀取最原始數據的格式信息以及 //數據輸出到HDFS集群中的格式信息 job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); //設置數據讀入和寫出的路徑到相關的Format類中 TextInputFormat.addInputPath(job,input); TextOutputFormat.setOutputPath(job,output); //提交作業 return job.waitForCompletion(true)?0:1; } public static void main(String[] args) throws Exception { System.exit( ToolRunner.run(new PatentReference_0011(),args) );; } }
3)使用Maven打包好,上傳到安裝配置好集群客戶端的Linux服務器中
4)運行測試

執行上面的語句,註意指定輸出路徑的時候,一定是集群中的路徑並且目錄要預先不存在,因為程序會自動去創建這個目錄。
5)然後我們可以去Web控制頁面去觀察htttp://ip:8088去查看作業的進度
喜歡就點“推薦”哦!
Hadoop(十二)MapReduce概述