
MongoDB oplog詳解
MongoDB oplog詳解
轉文1:oplog簡介
oplog是local庫下的一個固定集合,Secondary就是通過查看Primary 的oplog這個集合來進行復制的。每個節點都有oplog,記錄這從主節點復制過來的信息,這樣每個成員都可以作為同步源給其他節點。
Oplog 可以說是Mongodb Replication的紐帶了。
2:副本集數據同步的過程
副本集中數據同步的詳細過程:Primary節點寫入數據,Secondary通過讀取Primary的oplog得到復制信息,開始復制數據並且將復制信息寫入到自己的oplog。如果某個操作失敗(只有當同步源的數據損壞或者數據與主節點不一致時才可能發生),則備份節點停止從當前數據源復制數據。如果某個備份節點由於某些原因掛掉了,當重新啟動後,就會自動從oplog的最後一個操作開始同步,同步完成後,將信息寫入自己的oplog,由於復制操作是先復制數據,復制完成後再寫入oplog,有可能相同的操作會同步兩份,不過MongoDB在設計之初就考慮到這個問題,將oplog的同一個操作執行多次,與執行一次的效果是一樣的。
-
作用:
當Primary進行寫操作的時候,會將這些寫操作記錄寫入Primary的Oplog 中,而後Secondary會將Oplog 復制到本機並應用這些操作,從而實現Replication的功能。
同時由於其記錄了Primary上的寫操作,故還能將其用作數據恢復。
可以簡單的將其視作Mysql中的binlog。
3:oplog的增長速度
oplog是固定大小,他只能保存特定數量的操作日誌,通常oplog使用空間的增長速度跟系統處理寫請求的速度相當,如果主節點上每分鐘處理1KB的寫入數據,那麽oplog每分鐘大約也寫入1KB數據。如果單次操作影響到了多個文檔(比如刪除了多個文檔或者更新了多個文檔)則oplog可能就會有多條操作日誌。db.testcoll.remove() 刪除了1000000個文檔,那麽oplog中就會有1000000條操作日誌。如果存在大批量的操作,oplog有可能很快就會被寫滿了。
-
大小:
Oplog 是一個capped collection。
在64位的Linux, Solaris, FreeBSD, and Windows 系統中,Mongodb默認將其大小設置為可用disk空間的5%(默認最小為1G,最大為50G),或也可以在mongodb復制集實例初始化之前將mongo.conf中oplogSize設置為我們需要的值。
local.oplog.rs 一個capped collection集合.可在命令行下使用--oplogSize 選項設置該集合大小尺寸.
但是由於Oplog 其保證了復制的正常進行,以及數據的安全性和容災能力。
4:oplog註意事項:
local.oplog.rs特殊的集合。用來記錄Primary節點的操作。
為了提高復制的效率,復制集中的所有節點之間會相互的心跳檢測(ping)。每個節點都可以從其他節點上獲取oplog。
oplog中的一條操作。不管執行多少次效果是一樣的
5:oplog的大小
第一次啟動復制集中的節點時,MongoDB會建立Oplog,會有一個默認的大小,這個大小取決於機器的操作系統
rs.printReplicationInfo() 查看 oplog 的狀態,輸出信息包括 oplog 日誌大小,操作日誌記錄的起始時間。
db.getReplicationInfo() 可以用來查看oplog的狀態、大小、存儲的時間範圍。
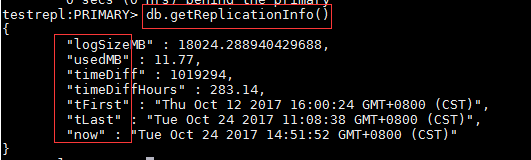
oplog的大小
capped collection是MongoDB中一種提供高性能插入、讀取和刪除操作的固定大小集合,當集合被填滿的時候,新的插入的文檔會覆蓋老的文檔。
所以,oplog表使用capped collection是合理的,因為不可能無限制的增長oplog。MongoDB在初始化副本集的時候都會有一個默認的oplog大小:
- 在64位的Linux,Solaris,FreeBSD以及Windows系統上,MongoDB會分配磁盤剩余空間的5%作為oplog的大小,如果這部分小於1GB則分配1GB的空間
- 在64的OS X系統上會分配183MB
- 在32位的系統上則只分配48MB
oplog的大小設置是值得考慮的一個問題,如果oplog size過大,會浪費存儲空間;如果oplog size過小,老的oplog記錄很快就會被覆蓋,那麽宕機的節點就很容易出現無法同步數據的現象。
比如,基於上面的例子,我們停掉一個備份節點(port=33333),然後通過主節點插入以下記錄,然後查看oplog,發現以前的oplog已經被覆蓋了。
通過MongoDB shell連接上這個節點,會發現這個節點一直處於RECOVERING狀態。
解決方法:
數據同步
在副本集中,有兩種數據同步方式:
-
initial sync(初始化):這個過程發生在當副本集中創建一個新的數據庫或其中某個節點剛從宕機中恢復,或者向副本集中添加新的成員的時候,默認的,副本集中的節點會從離它最近的節點復制oplog來同步數據,這個最近的節點可以是primary也可以是擁有最新oplog副本的secondary節點。
- 該操作一般會重新初始化備份節點,開銷較大
- replication(復制):在初始化後這個操作會一直持續的進行著,以保持各個secondary節點之間的數據同步。
initial sync
當遇到上面例子中無法同步的問題時,只能使用以下兩種方式進行initial sync了
-
第一種方式就是停止該節點,然後刪除目錄中的文件,重新啟動該節點。這樣,這個節點就會執行initial sync
- 註意:通過這種方式,sync的時間是根據數據量大小的,如果數據量過大,sync時間就會很長
- 同時會有很多網絡傳輸,可能會影響其他節點的工作
- 第二種方式,停止該節點,然後刪除目錄中的文件,找一個比較新的節點,然後把該節點目錄中的文件拷貝到要sync的節點目錄中
通過上面兩種方式中的一種,都可以重新恢復"port=33333"的節點。改變一直處於RECOVERING狀態的錯誤。
6:oplog數據結構
下面來分析一下oplog中字段的含義,通過下面的命令取出一條oplog:
db.oplog.rs.find().skip(1).limit(1).toArray()
- ts: 8字節的時間戳,由4字節unix timestamp + 4字節自增計數表示。這個值很重要,在選舉(如master宕機時)新primary時,會選擇ts最大的那個secondary作為新primary
-
op:1字節的操作類型
- "i": insert
- "u": update
- "d": delete
- "c": db cmd
- "db":聲明當前數據庫 (其中ns 被設置成為=>數據庫名稱+ ‘.‘)
- "n": no op,即空操作,其會定期執行以確保時效性
- ns:操作所在的namespace
- o:操作所對應的document,即當前操作的內容(比如更新操作時要更新的的字段和值)
- o2: 在執行更新操作時的where條件,僅限於update時才有該屬性
查看oplog的信息
通過"db.printReplicationInfo()"命令可以查看oplog的信息
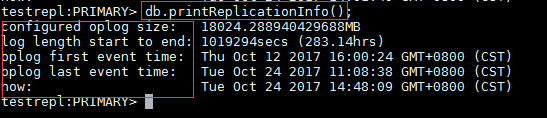
字段說明:
- configured oplog size: oplog文件大小
- log length start to end: oplog日誌的啟用時間段
- oplog first event time: 第一個事務日誌的產生時間
- oplog last event time: 最後一個事務日誌的產生時間
- now: 現在的時間
查看slave狀態
通過"db.printSlaveReplicationInfo()"可以查看slave的同步狀態
副本節點中執行db.printSlaveReplicationInfo()命令可以查看同步狀態信息
- source——從庫的IP及端口
- syncedTo——當前的同步情況,延遲了多久等信息
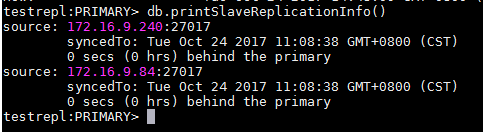
當我們插入一條新的數據,然後重新檢查slave狀態時,就會發現sync時間更新了
參考文章
MongoDB oplog詳解