
數據結構基礎
存儲結構分為:
1,隨機存取,即可隨意直接存取任意一個元素,通過下標直接存取出任何一個元素;通過地址直接訪問任意一個空間
2,順序存取,只能從前往後逐個訪問。
3,索引存取,為某個關鍵字建立索引表,從表中取得地址。索引存取多用在數據管理過程中。
4,散列存取。
有1千萬條重復的短信,以文本形式保存,一行一條,有重復。請在5分鐘時間內找出重復出現最多的10條短信?
答:用哈希表的方法。
1)將1千萬條短信分成若幹組,進行邊掃描邊建散列表的方法。第一次掃描,取首字節、尾字節、中間任意兩個字節作為hash code,插入到Hash table中,並記錄其地址、信息長度和重復次數。同Hash code且等長就疑似為相同,比較一下,若相同則加1次Hash table,將重復次數加1。一次掃描後,已經記錄了各自的重復次數,進行第2次hash table的處理。用線性時間選擇可在O(n)的級別上完成前10條的尋找。分組後每組中的top10必須保證各不相同,可用hash來保證,也可以用hash值來保證。
深度優先遍歷(DFS)類似於樹的前序遍歷。
廣度優先遍歷(BFS)類似於樹的按層次遍歷。
哈夫曼編碼:abcdabaa,a編碼0(1位),b編碼10(2位),c編碼110(3位),d編碼111(3位),總長度:1*4+2*2+3*1+3*1=14
http://www.cnblogs.com/huangxincheng/archive/2012/11/25/2788268.html
Trie樹,又稱為單詞查找樹、字典樹。經常用於搜索引擎系統用於文本詞頻統計。
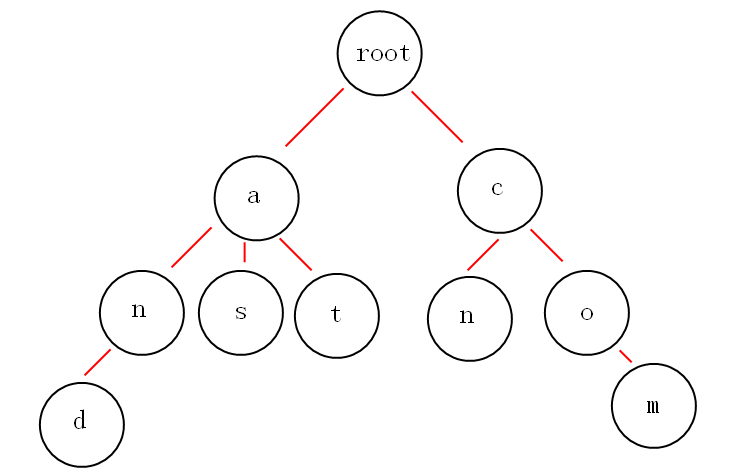
從上面的圖中,我們或多或少的可以發現一些好玩的特性。
第一:根節點不包含字符,除根節點外的每一個子節點都包含一個字符。
第二:從根節點到某一節點,路徑上經過的字符連接起來,就是該節點對應的字符串。
第三:每個單詞的公共前綴作為一個字符節點保存。
二:使用範圍
既然學Trie樹,我們肯定要知道這玩意是用來幹嘛的。
第一:詞頻統計。
可能有人要說了,詞頻統計簡單啊,一個hash或者一個堆就可以打完收工,但問題來了,如果內存有限呢?還能這麽
玩嗎?所以這裏我們就可以用trie樹來壓縮下空間,因為公共前綴都是用一個節點保存的。
第二: 前綴匹配
就拿上面的圖來說吧,如果我想獲取所有以"a"開頭的字符串,從圖中可以很明顯的看到是:and,as,at,如果不用trie樹,
你該怎麽做呢?很顯然樸素的做法時間復雜度為O(N2) ,那麽用Trie樹就不一樣了,它可以做到h,h為你檢索單詞的長度,
可以說這是秒殺的效果。
快速排序的空間復雜度?
數據結構基礎