
MySQL語句技巧
1、查詢時將時間戳格式化顯示:
SELECT FROM_UNIXTIME(1234567890, ‘%Y-%m-%d %H:%i:%S‘) FROM table_name
2、最高效的刪除重復記錄方法 ( 因為使用了ROWID)例子:
DELETE FROM EMP E WHERE E.ROWID > (SELECT MIN(X.ROWID) FROM EMP X WHERE X.EMP_NO = E.EMP_NO);
3、查詢一段時間內,每5分鐘間隔在線分時數據統計(eventtime是時間戳)
SELECT FROM_UNIXTIME(`eventtime`-`eventtime`% (5*60), ‘%Y-%m-%d %H:%i:%S‘) AS stime, count(distinct uid) uids
FROM 20170828_online WHERE eventtime>=1503921000 AND eventtime<=1503925200
GROUP BY stime;
4、將兩個表的查詢結果合並成一行
select A.newusers,B.pay from (SELECT COUNT(DISTINCT uid) AS newusers FROM applogs.20171025_firstentry WHERE game=12 AND client=1) AS A,
(SELECT SUM(money)/100 AS pay FROM applogs.20171025_paylog WHERE eventdate=flogindate AND game=12 AND client=1 ) AS B;
5、列轉行技巧
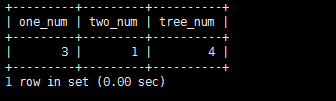
eg:統計id為1的記錄數,id為2的記錄數以及id為3的記錄數。
SELECT COUNT(CASE WHEN id=1 THEN 1 ELSE NULL END ) AS `one_num`,COUNT(CASE WHEN id=2 THEN 1 ELSE NULL END ) AS `two_num`,COUNT(CASE WHEN id=3 THEN 1 ELSE NULL END ) AS `tree_num` FROM test;
表數據:
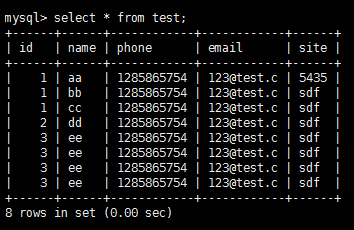
執行該語句的結果:
6、group_concat函數的使用方法
公式:group_concat([DISTINCT] 要連接的字段 [Order BY ASC/DESC 排序字段] [Separator ‘分隔符‘])
基礎表格:(以5中的表格數據為例)
(1)以id分組,把name字段的值放在同一結果行,以逗號分隔(默認)
SELECT id,GROUP_CONCAT(NAME) AS id_name FROM test GROUP BY id;
結果:
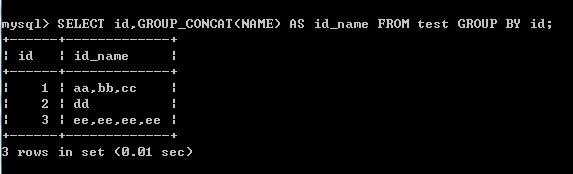
(2)以id分組,把name字段的值放在同一結果行,以分號分隔
SELECT id,GROUP_CONCAT(NAME SEPARATOR ‘;‘) AS id_name FROM test GROUP BY id;
結果:
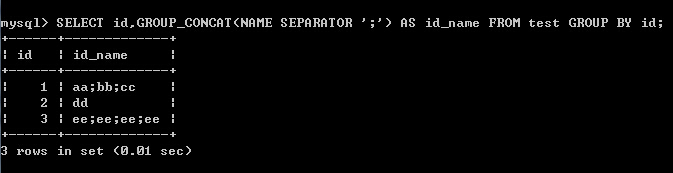
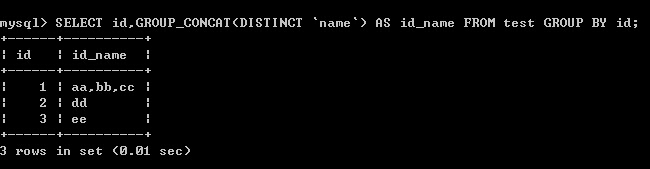
(3)以id分組,把去冗余的name字段的值放在同一結果行, 以逗號分隔
SELECT id,GROUP_CONCAT(DISTINCT `name`) AS id_name FROM test GROUP BY id;
結果:
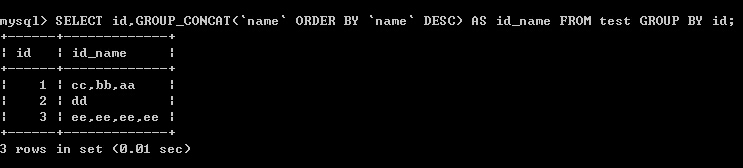
(4)以id分組,把name字段的值放在同一結果行,逗號分隔,以name排倒序
SELECT id,GROUP_CONCAT(`name` ORDER BY `name` DESC) AS id_name FROM test GROUP BY id;
結果:
7、插入數據出現UNIQUE索引或PRIMARY KEY沖突時就使用更新(ON DUPLICATE KEY UPDATE 語法)
(1) INSERT INTO `sy`.`day` (id, name, phone) VALUES(‘666‘, ‘xst‘, ‘10086‘) ON DUPLICATE KEY UPDATE name = VALUES(name),phone = VALUES(phone);
(2) INSERT INTO TABLE (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1; (UPDATE TABLE SET c=c+1 WHERE a=1;)
(3) INSERT INTO TABLE (a,b,c) VALUES (1,2,3),(2,5,7),(3,3,6),(4,8,2) ON DUPLICATE KEY UPDATE b=VALUES(b);
MySQL語句技巧