
文本分類解決方法綜述
一、傳統文本分類方法
文本分類問題算是自然語言處理領域中一個非常經典的問題了,相關研究最早可以追溯到上世紀50年代,當時是通過專家規則(Pattern)進行分類,甚至在80年代初一度發展到利用知識工程建立專家系統,這樣做的好處是短平快的解決top問題,但顯然天花板非常低,不僅費時費力,覆蓋的範圍和準確率都非常有限。後來伴隨著統計學習方法的發展,特別是90年代後互聯網在線文本數量增長和機器學習學科的興起,逐漸形成了一套解決大規模文本分類問題的經典玩法,這個階段的主要套路是人工特征工程+淺層分類模型。整個文本分類問題就拆分成了特征工程和分類器兩部分。
1.1 特征工程
特征工程在機器學習中往往是最耗時耗力的,但卻極其的重要。抽象來講,機器學習問題是把數據轉換成信息再提煉到知識的過程,特征是“數據-->信息”的過程,決定了結果的上限,而分類器是“信息-->知識”的過程,則是去逼近這個上限。然而特征工程不同於分類器模型,不具備很強的通用性,往往需要結合對特征任務的理解。文本分類問題所在的自然語言領域自然也有其特有的特征處理邏輯,傳統分本分類任務大部分工作也在此處。文本特征工程分為文本預處理、特征提取、文本表示
1)文本預處理
文本預處理過程是在文本中提取關鍵詞表示文本的過程,中文文本處理中主要包括文本分詞和去停用詞兩個階段。之所以進行分詞,是因為很多研究表明特征粒度為詞粒度遠好於字粒度,其實很好理解,因為大部分分類算法不考慮詞序信息,基於字粒度顯然損失了過多“n-gram”信息。具體到中文分詞,不同於英文有天然的空格間隔,需要設計復雜的分詞算法。傳統算法主要有基於字符串匹配的正向/逆向/雙向最大匹配;基於理解的句法和語義分析消歧;基於統計的互信息/CRF方法。近年來隨著深度學習的應用,WordEmbedding + Bi-LSTM+CRF方法
2)特征提取
向量空間模型的文本表示方法的特征提取對應特征項的選擇和特征權重計算兩部分。特征選擇的基本思路是根據某個評價指標獨立的對原始特征項(詞項)進行評分排序,從中選擇得分最高的一些特征項,過濾掉其余的特征項。常用的評價有文檔頻率、互信息、信息增益、χ2統計量等。特征權重主要是經典的TF-IDF方法及其擴展方法,主要思路是一個詞的重要度與在類別內的詞頻成正比,與所有類別出現的次數成反比。
3)文本表示
文本表示的目的是把文本預處理後的轉換成計算機可理解的方式,是決定文本分類質量最重要的部分。傳統做法常用詞袋模型(BOW, Bag Of Words)或向量空間模型(Vector Space Model),最大的不足是忽略文本上下文關系,每個詞之間彼此獨立,並且無法表征語義信息。詞袋模型的示例如下:( 0, 0, 0, 0, .... , 1, ... 0, 0, 0, 0) 一般來說詞庫量至少都是百萬級別,因此詞袋模型有個兩個最大的問題:高緯度、高稀疏性。詞袋模型是向量空間模型的基礎,因此向量空間模型通過特征項選擇降低維度,通過特征權重計算增加稠密性。
傳統做法在文本表示方面除了向量空間模型,還有基於語義的文本表示方法,比如LDA主題模型、LSI/PLSI概率潛在語義索引等方法,一般認為這些方法得到的文本表示可以認為文檔的深層表示,而word embedding文本分布式表示方法則是深度學習方法的重要基礎。
1.2 分類器
分類器基本都是統計分類方法了,基本上大部分機器學習方法都在文本分類領域有所應用,比如樸素貝葉斯分類算法(Na?ve Bayes)、KNN、SVM、最大熵和神經網絡等等。
二、深度學習文本分類方法
上文介紹了傳統的文本分類做法,傳統做法主要問題的文本表示是高緯度高稀疏的,特征表達能力很弱,而且神經網絡很不擅長對此類數據的處理;此外需要人工進行特征工程,成本很高。而深度學習最初在之所以圖像和語音取得巨大成功,一個很重要的原因是圖像和語音原始數據是連續和稠密的,有局部相關性。應用深度學習解決大規模文本分類問題最重要的是解決文本表示,再利用CNN/RNN等網絡結構自動獲取特征表達能力,去掉繁雜的人工特征工程,端到端的解決問題。接下來會分別介紹:
分布式表示(Distributed Representation)其實Hinton 最早在1986年就提出了,基本思想是將每個詞表達成 n 維稠密、連續的實數向量,與之相對的one-hot encoding向量空間只有一個維度是1,其余都是0。分布式表示最大的優點是具備非常powerful的特征表達能力,比如 n 維向量每維 k 個值,可以表征 個概念。事實上,不管是神經網絡的隱層,還是多個潛在變量的概率主題模型,都是應用分布式表示。下圖是03年Bengio在 A Neural Probabilistic Language Model 的網絡結構:

這篇文章提出的神經網絡語言模型(NNLM,Neural Probabilistic Language Model)采用的是文本分布式表示,即每個詞表示為稠密的實數向量。NNLM模型的目標是構建語言模型:

詞的分布式表示即詞向量(word embedding)是訓練語言模型的一個附加產物,即圖中的Matrix C。
盡管Hinton 86年就提出了詞的分布式表示,Bengio 03年便提出了NNLM,詞向量真正火起來是google Mikolov 13年發表的兩篇word2vec的文章 Efficient Estimation of Word Representations in Vector Space 和 Distributed Representations of Words and Phrases and their Compositionality,更重要的是發布了簡單好用的word2vec工具包,在語義維度上得到了很好的驗證,極大的推進了文本分析的進程。下圖是文中提出的CBOW 和 Skip-Gram兩個模型的結構,基本類似於NNLM,不同的是模型去掉了非線性隱層,預測目標不同,CBOW是上下文詞預測當前詞,Skip-Gram則相反。

除此之外,提出了Hierarchical Softmax 和 Negative Sample兩個方法,很好的解決了計算有效性,事實上這兩個方法都沒有嚴格的理論證明,有些trick之處,非常的實用主義。詳細的過程不再闡述了,有興趣深入理解word2vec的,推薦讀讀這篇很不錯的paper:word2vec Parameter Learning Explained。額外多提一點,實際上word2vec學習的向量和真正語義還有差距,更多學到的是具備相似上下文的詞,比如“good”“bad”相似度也很高,反而是文本分類任務輸入有監督的語義能夠學到更好的語義表示,有機會後續系統分享下。
至此,文本的表示通過詞向量的表示方式,把文本數據從高緯度高稀疏的神經網絡難處理的方式,變成了類似圖像、語音的的連續稠密數據。深度學習算法本身有很強的數據遷移性,很多之前在圖像領域很適用的深度學習算法比如CNN等也可以很好的遷移到文本領域了,下一小節具體闡述下文本分類領域深度學習的方法。
2.2 深度學習文本分類模型
詞向量解決了文本表示的問題,該部分介紹的文本分類模型則是利用CNN/RNN等深度學習網絡及其變體解決自動特征提取(即特征表達)的問題。
1)fastText
fastText 是上文提到的 word2vec 作者 Mikolov 轉戰 Facebook 後16年7月剛發表的一篇論文 Bag of Tricks for Efficient Text Classification。把 fastText 放在此處並非因為它是文本分類的主流做法,而是它極致簡單,模型圖見下:

原理是把句子中所有的詞向量進行平均(某種意義上可以理解為只有一個avg pooling特殊CNN),然後直接接 softmax 層。其實文章也加入了一些 n-gram 特征的 trick 來捕獲局部序列信息。文章倒沒太多信息量,算是“水文”吧,帶來的思考是文本分類問題是有一些“線性”問題的部分[from項亮],也就是說不必做過多的非線性轉換、特征組合即可捕獲很多分類信息,因此有些任務即便簡單的模型便可以搞定了。
2)TextCNN
本篇文章的題圖選用的就是14年這篇文章提出的TextCNN的結構(見下圖)。fastText 中的網絡結果是完全沒有考慮詞序信息的,而它用的 n-gram 特征 trick 恰恰說明了局部序列信息的重要意義。卷積神經網絡(CNN Convolutional Neural Network)最初在圖像領域取得了巨大成功,CNN原理就不講了,核心點在於可以捕捉局部相關性,具體到文本分類任務中可以利用CNN來提取句子中類似 n-gram 的關鍵信息。
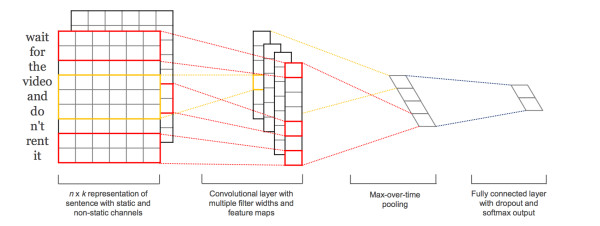
TextCNN的詳細過程原理圖見下:
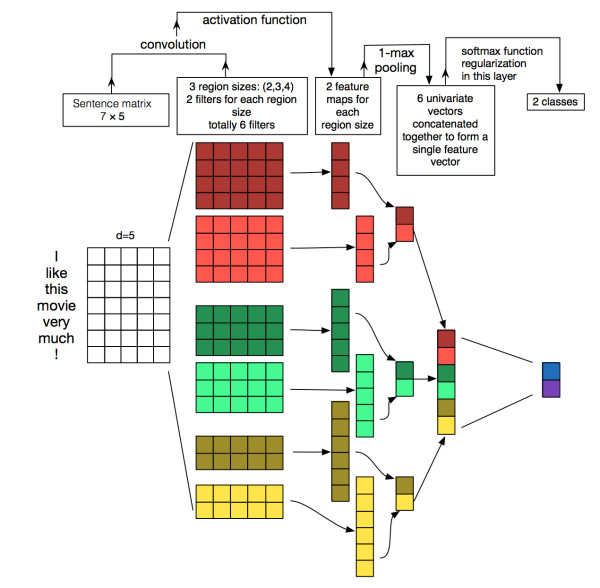
TextCNN詳細過程:第一層是圖中最左邊的7乘5的句子矩陣,每行是詞向量,維度=5,這個可以類比為圖像中的原始像素點了。然後經過有 filter_size=(2,3,4) 的一維卷積層,每個filter_size 有兩個輸出 channel。第三層是一個1-max pooling層,這樣不同長度句子經過pooling層之後都能變成定長的表示了,最後接一層全連接的 softmax 層,輸出每個類別的概率。
特征:這裏的特征就是詞向量,有靜態(static)和非靜態(non-static)方式。static方式采用比如word2vec預訓練的詞向量,訓練過程不更新詞向量,實質上屬於遷移學習了,特別是數據量比較小的情況下,采用靜態的詞向量往往效果不錯。non-static則是在訓練過程中更新詞向量。推薦的方式是 non-static 中的 fine-tunning方式,它是以預訓練(pre-train)的word2vec向量初始化詞向量,訓練過程中調整詞向量,能加速收斂,當然如果有充足的訓練數據和資源,直接隨機初始化詞向量效果也是可以的。
通道(Channels):圖像中可以利用 (R, G, B) 作為不同channel,而文本的輸入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),實踐中也有利用靜態詞向量和fine-tunning詞向量作為不同channel的做法。
一維卷積(conv-1d):圖像是二維數據,經過詞向量表達的文本為一維數據,因此在TextCNN卷積用的是一維卷積。一維卷積帶來的問題是需要設計通過不同 filter_size 的 filter 獲取不同寬度的視野。
Pooling層:利用CNN解決文本分類問題的文章還是很多的,比如這篇 A Convolutional Neural Network for Modelling Sentences 最有意思的輸入是在 pooling 改成 (dynamic) k-max pooling ,pooling階段保留 k 個最大的信息,保留了全局的序列信息。比如在情感分析場景,舉個例子:

雖然前半部分體現情感是正向的,全局文本表達的是偏負面的情感,利用 k-max pooling能夠很好捕捉這類信息。
3)TextRNN
盡管TextCNN能夠在很多任務裏面能有不錯的表現,但CNN有個最大問題是固定 filter_size 的視野,一方面無法建模更長的序列信息,另一方面 filter_size 的超參調節也很繁瑣。CNN本質是做文本的特征表達工作,而自然語言處理中更常用的是遞歸神經網絡(RNN, Recurrent Neural Network),能夠更好的表達上下文信息。具體在文本分類任務中,Bi-directional RNN(實際使用的是雙向LSTM)從某種意義上可以理解為可以捕獲變長且雙向的的 "n-gram" 信息。
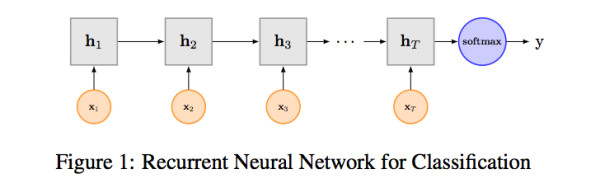
RNN算是在自然語言處理領域非常一個標配網絡了,在序列標註/命名體識別/seq2seq模型等很多場景都有應用,Recurrent Neural Network for Text Classification with Multi-Task Learning文中介紹了RNN用於分類問題的設計,下圖LSTM用於網絡結構原理示意圖,示例中的是利用最後一個詞的結果直接接全連接層softmax輸出了。
4)TextRNN + Attention
CNN和RNN用在文本分類任務中盡管效果顯著,但都有一個不足的地方就是不夠直觀,可解釋性不好,特別是在分析badcase時候感受尤其深刻。而註意力(Attention)機制是自然語言處理領域一個常用的建模長時間記憶機制,能夠很直觀的給出每個詞對結果的貢獻,基本成了Seq2Seq模型的標配了。實際上文本分類從某種意義上也可以理解為一種特殊的Seq2Seq,所以考慮把Attention機制引入近來,研究了下學術界果然有類似做法。
Attention機制介紹:
詳細介紹Attention恐怕需要一小篇文章的篇幅,感興趣的可參考14年這篇paper NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE。
以機器翻譯為例簡單介紹下,下圖中 是源語言的一個詞,
是目標語言的一個詞,機器翻譯的任務就是給定源序列得到目標序列。翻譯
的過程產生取決於上一個詞
和源語言的詞的表示
(
的 bi-RNN 模型的表示),而每個詞所占的權重是不一樣的。比如源語言是中文 “我 / 是 / 中國人” 目標語言 “i / am / Chinese”,翻譯出“Chinese”時候顯然取決於“中國人”,而與“我 / 是”基本無關。下圖公式,
則是翻譯英文第
個詞時,中文第
個詞的貢獻,也就是註意力。顯然在翻譯“Chinese”時,“中國人”的註意力值非常大。
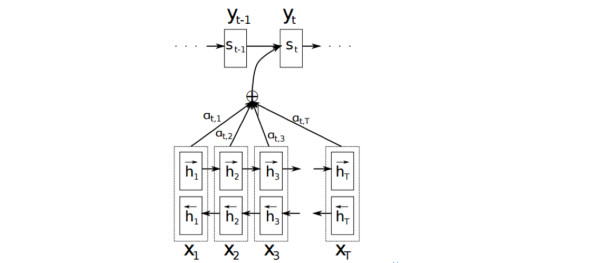
Attention的核心point是在翻譯每個目標詞(或預測商品標題文本所屬類別)所用的上下文是不同的,這樣的考慮顯然是更合理的。
TextRNN + Attention 模型:
我們參考了這篇文章 Hierarchical Attention Networks for Document Classification,下圖是模型的網絡結構圖,它一方面用層次化的結構保留了文檔的結構,另一方面在word-level和sentence-level。淘寶標題場景只需要 word-level 這一層的 Attention 即可。
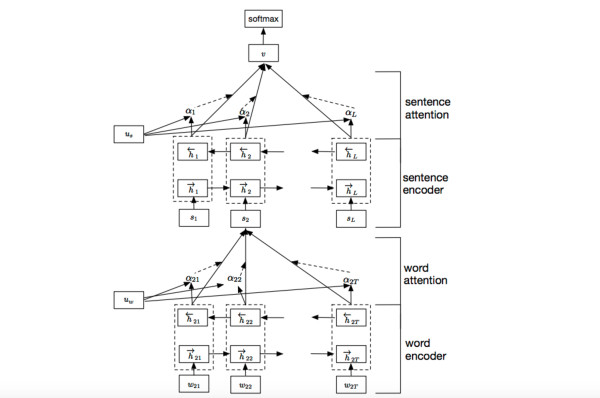
加入Attention之後最大的好處自然是能夠直觀的解釋各個句子和詞對分類類別的重要性。
5)TextRCNN(TextRNN + CNN)
我們參考的是中科院15年發表在AAAI上的這篇文章 Recurrent Convolutional Neural Networks for Text Classification 的結構:
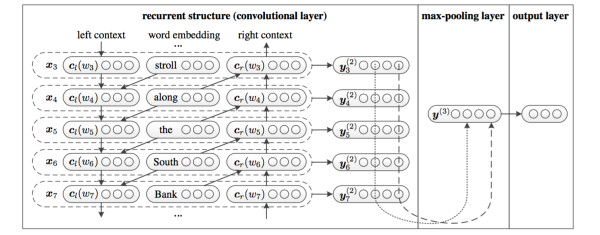
利用前向和後向RNN得到每個詞的前向和後向上下文的表示:
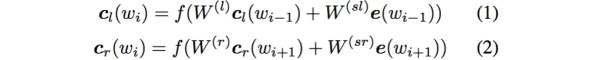
這樣詞的表示就變成詞向量和前向後向上下文向量concat起來的形式了,即:
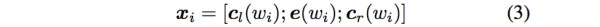
最後再接跟TextCNN相同卷積層,pooling層即可,唯一不同的是卷積層 filter_size = 1就可以了,不再需要更大 filter_size 獲得更大視野,這裏詞的表示也可以只用雙向RNN輸出。
三、一點經驗
理論和實踐之間的Gap往往差異巨大,學術paper更關註的是模型架構設計的新穎性等,更重要的是新的思路;而實踐最重要的是在落地場景的效果,關註的點和方法都不一樣。這部分簡單梳理實際做項目過程中的一點經驗教訓。
模型顯然並不是最重要的:不能否認,好的模型設計對拿到好結果的至關重要,也更是學術關註熱點。但實際使用中,模型的工作量占的時間其實相對比較少。雖然在第二部分介紹了5種CNN/RNN及其變體的模型,實際中文本分類任務單純用CNN已經足以取得很不錯的結果了,我們的實驗測試RCNN對準確率提升大約1%,並不是十分的顯著。最佳實踐是先用TextCNN模型把整體任務效果調試到最好,再嘗試改進模型。
理解你的數據:雖然應用深度學習有一個很大的優勢是不再需要繁瑣低效的人工特征工程,然而如果你只是把他當做一個黑盒,難免會經常懷疑人生。一定要理解你的數據,記住無論傳統方法還是深度學習方法,數據 sense 始終非常重要。要重視 badcase 分析,明白你的數據是否適合,為什麽對為什麽錯。
關註叠代質量 - 記錄和分析你的每次實驗:叠代速度是決定算法項目成敗的關鍵,學過概率的同學都很容易認同。而算法項目重要的不只是叠代速度,一定要關註叠代質量。如果你沒有搭建一個快速實驗分析的套路,叠代速度再快也只會替你公司心疼寶貴的計算資源。建議記錄每次實驗,實驗分析至少回答這三個問題:為什麽要實驗?結論是什麽?下一步怎麽實驗?
超參調節:超參調節是各位調參工程師的日常了,推薦一篇文本分類實踐的論文 A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification,裏面貼了一些超參的對比實驗,如果你剛開始啟動文本分析任務,不妨按文章的結果設置超參,怎麽最快的得到超參調節其實是一個非常重要的問題,可以讀讀 蕭瑟的這篇文章 深度學習網絡調參技巧 - 知乎專欄。
一定要用 dropout:有兩種情況可以不用:數據量特別小,或者你用了更好的正則方法,比如bn。實際中我們嘗試了不同參數的dropout,最好的還是0.5,所以如果你的計算資源很有限,默認0.5是一個很好的選擇。
fine-tuning 是必選的:上文聊到了,如果只是使用word2vec訓練的詞向量作為特征表示,我賭你一定會損失很大的效果。
未必一定要 softmax loss: 這取決與你的數據,如果你的任務是多個類別間非互斥,可以試試著訓練多個二分類器,也就是把問題定義為multi lable 而非 multi class,我們調整後準確率還是增加了>1%。
類目不均衡問題:基本是一個在很多場景都驗證過的結論:如果你的loss被一部分類別dominate,對總體而言大多是負向的。建議可以嘗試類似 booststrap 方法調整 loss 中樣本權重方式解決。
避免訓練震蕩:默認一定要增加隨機采樣因素盡可能使得數據分布iid,默認shuffle機制能使得訓練結果更穩定。如果訓練模型仍然很震蕩,可以考慮調整學習率或 mini_batch_size。
沒有收斂前不要過早的下結論:玩到最後的才是玩的最好的,特別是一些新的角度的測試,不要輕易否定,至少要等到收斂吧。
本文來源:雷鋒網(https://www.leiphone.com/news/201710/lcuWi98knUcroL6j.html)
文本分類解決方法綜述