
一個完整的大作業
阿新 • • 發佈:2017-10-29
www. 有一個 最新 find box 技術分享 ade blog 提取
本次爬取小說的網站為136書屋。
先打開花千骨小說的目錄頁,是這樣的。
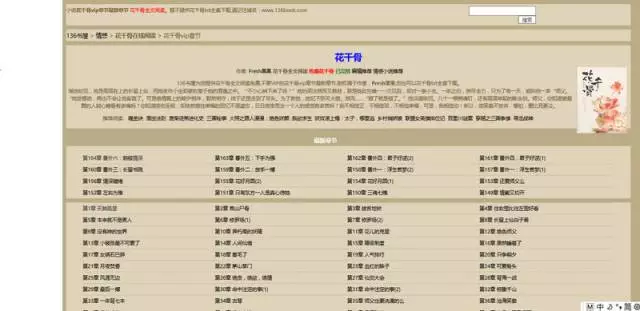
我們的目的是找到每個目錄對應的url,並且爬取其中地正文內容,然後放在本地文件中。
2.網頁結構分析
首先,目錄頁左上角有幾個可以提高你此次爬蟲成功後成就感的字眼:暫不提供花千骨txt全集下載。
繼續往下看,發現是最新章節板塊,然後便是全書的所有目錄。我們分析的對象便是全書所有目錄。點開其中一個目錄,我們便可以都看到正文內容。
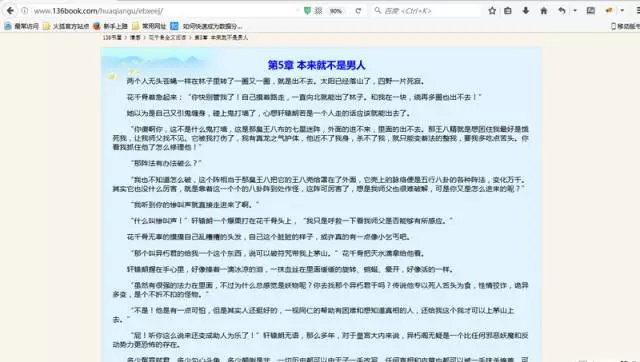
按F12打開審查元素菜單。可以看到網頁前端的內容都包含在這裏。
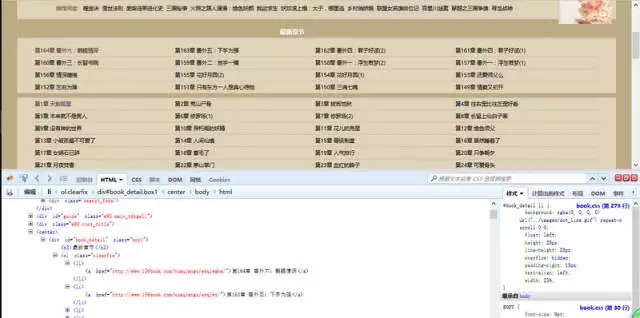
我們的目的是要找到所有目錄的對應鏈接地址,爬取每個地址中的文本內容。
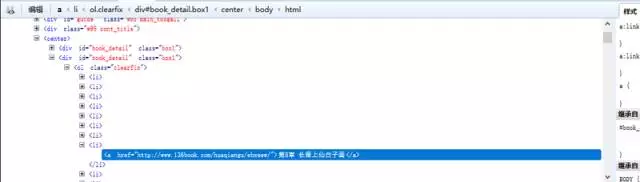
有耐心的朋友可以在裏面找到對應的章節目錄內容。有一個簡便方法是點擊審查元素中左上角箭頭標誌的按鈕,然後選中相應元素,對應的位置就會加深顯示。
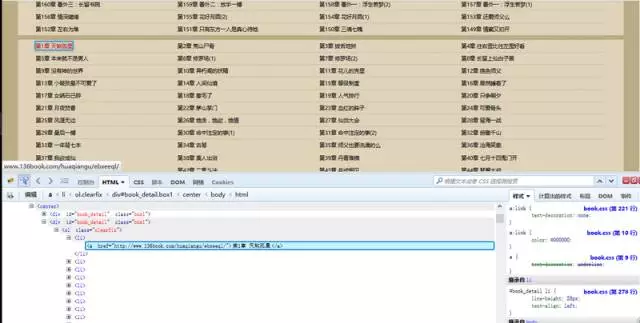
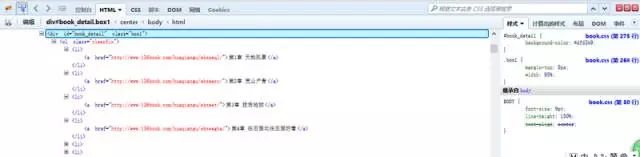
這樣我們可以看到,每一章的鏈接地址都是有規則地存放在<li>中。而這些<li>又放在<div id=”book_detail” class=”box1″>中。
我不停地強調“我們的目的”是要告訴大家,思路很重要。爬蟲不是約pao,蒙頭就上不可取。
3.單章節爬蟲
剛才已經分析過網頁結構。我們可以直接在瀏覽器中打開對應章節的鏈接地址,然後將文本內容提取出來。
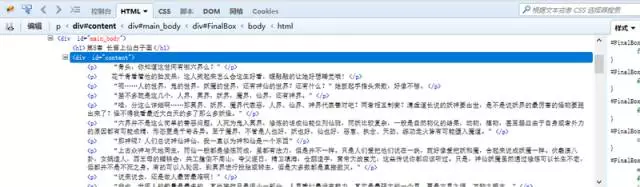
我們要爬取的內容全都包含在這個<div>裏面。
代碼整理如下
from urllib import request from bs4 import BeautifulSoupif __name__ == ‘__main__‘: # 第8章的網址 url = ‘http://www.136book.com/huaqiangu/ebxeew/‘ head = {} # 使用代理 head[‘User-Agent‘] = ‘Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19‘ req = request.Request(url, headers = head) response= request.urlopen(req) html = response.read() # 創建request對象 soup = BeautifulSoup(html, ‘lxml‘) # 找出div中的內容 soup_text = soup.find(‘div‘, id = ‘content‘) # 輸出其中的文本 print(soup_text.text)
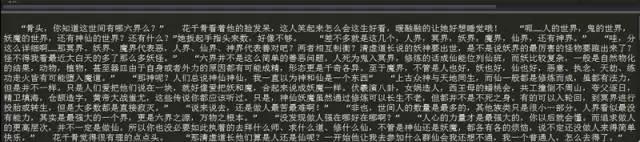
運行結果如下:
一個完整的大作業