
一臉懵逼學習Storm---(一個開源的分布式實時計算系統)
1:什麽是Storm?
Storm是一個開源的分布式實時計算系統,可以簡單、可靠的處理大量的數據流。被稱作“實時的hadoop”。Storm有很多使用場景:如實時分析,在線機器學習,持續計算, 分布式RPC,ETL等等。Storm支持水平擴展,具有高容錯性,保證每個消息都會得到處理,而且處理速度很快(在一個小集群中,每個結點每秒可以處理 數以百萬計的消息)。Storm的部署和運維都很便捷,而且更為重要的是可以使用任意編程語言來開發應用。
2:Storm的特點:
(1)編程模型簡單
在大數據處理方面相信大家對hadoop已經耳熟能詳,基於Google Map/Reduce來實現的Hadoop為開發者提供了map、reduce原語,使並行批處理程序變得非常地簡單和優美。
同樣,Storm也為大數據 的實時計算提供了一些簡單優美的原語,這大大降低了開發並行實時處理的任務的復雜性,幫助你快速、高效的開發應用。
(2)可擴展
在Storm集群中真正運行topology的主要有三個實體:工作進程、線程和任務。Storm集群中的每臺機器上都可以運行多個工作進程,每個 工作進程又可創建多個線程,每個線程可以執行多個任務,任務是真正進行數據處理的實體,我們開發的spout、bolt就是作為一個或者多個任務的方式執 行的。
因此,計算任務在多個線程、進程和服務器之間並行進行,支持靈活的水平擴展。
(3)高可靠性
Storm可以保證spout發出的每條消息都能被“完全處理”,這也是直接區別於其他實時系統的地方,如S4。
spout發出的消息後續可能會觸發產生成千上萬條消息,可以形象的理解為一棵消息樹,其中spout發出的消息為樹根,Storm會跟蹤 這棵消息樹的處理情況,只有當這棵消息樹中的所有消息都被處理了,Storm才會認為spout發出的這個消息已經被“完全處理”。如果這棵消息樹中的任 何一個消息處理失敗了,或者整棵消息樹在限定的時間內沒有“完全處理”,那麽spout發出的消息就會重發。
(4)高容錯性
如果在消息處理過程中出了一些異常,Storm會重新安排這個出問題的處理單元。Storm保證一個處理單元永遠運行(除非你顯式殺掉這個處理單元)。
當然,如果處理單元中存儲了中間狀態,那麽當處理單元重新被Storm啟動的時候,需要應用自己處理中間狀態的恢復。
(5)Storm集群和Hadoop集群表面上看很類似。Hadoop上運行的是MapReduce jobs,而在Storm上運行的是拓撲(topology);
Hadoop擅長於分布式離線批處理,而Storm設計為支持分布式實時計算;
Hadoop新的spark組件提供了在hadoop平臺上運行storm的可能性;
3:Storm的基本概念:
在深入理解Storm之前,需要了解一些概念:
Topologies : 拓撲,也俗稱一個任務
Spouts : 拓撲的消息源
Bolts : 拓撲的處理邏輯單元
tuple:消息元組
Streams : 流
Stream groupings :流的分組策略
Tasks : 任務處理單元
Executor :工作線程
Workers :工作進程
Configuration : topology的配置
4:Storm與Hadoop的對比:
(1)Topology 與 Mapreduce :
一個關鍵的區別是: 一個MapReduce job最終會結束, 而一個topology永遠會運行(除非你手動kill掉)
(2)Nimbus 與 ResourManager:
在Storm的集群裏面有兩種節點: 控制節點(master node)和工作節點(worker node)。控制節點上面運行一個叫Nimbus後臺程序,它的作用類似Hadoop裏面的JobTracker。Nimbus負責在集群裏面分發代碼,分配計算任務給機器, 並且監控狀態。
(3)Supervisor (worker進程)與NodeManager(YarnChild):
每一個工作節點上面運行一個叫做Supervisor的節點。Supervisor會監聽分配給它那臺機器的工作,根據需要啟動/關閉工作進程。每一個工作進程執行一個topology的一個子集;一個運行的topology由運行在很多機器上的很多工作進程組成。
5:Storm 體系架構:
(1)Nimbus和Supervisor之間的所有協調工作都是通過Zookeeper集群完成。:
(2)Nimbus進程和Supervisor進程都是快速失敗(fail-fast)和無狀態的。所有的狀態要麽在zookeeper裏面, 要麽在本地磁盤上。
(3)這也就意味著你可以用kill -9來殺死Nimbus和Supervisor進程, 然後再重啟它們,就好像什麽都沒有發生過。這個設計使得Storm異常的穩定。
5.1:Storm中的Nimbus和Supervisor: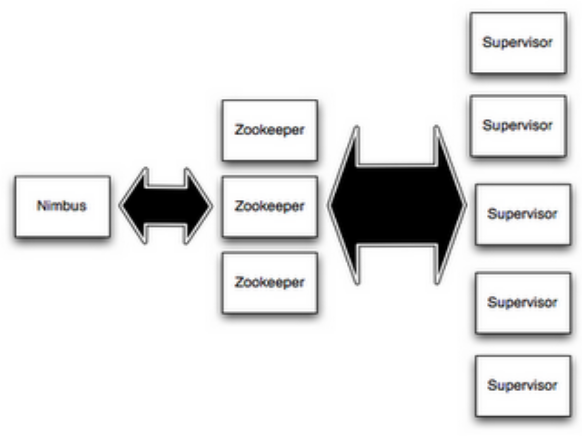
5.2:Storm中的Topologies:
一個topology是spouts和bolts組成的圖, 通過stream groupings將圖中的spouts和bolts連接起來,如下圖: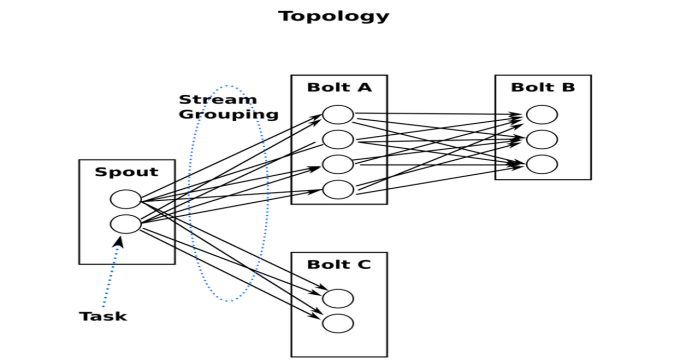
5.3:Storm中的Stream
消息流stream是storm裏的關鍵抽象;
一個消息流是一個沒有邊界的tuple序列, 而這些tuple序列會以一種分布式的方式並行地創建和處理;
通過對stream中tuple序列中每個字段命名來定義stream;
在默認的情況下,tuple的字段類型可以是:integer,long,short, byte,string,double,float,boolean和byte array;
可以自定義類型(只要實現相應的序列化器)。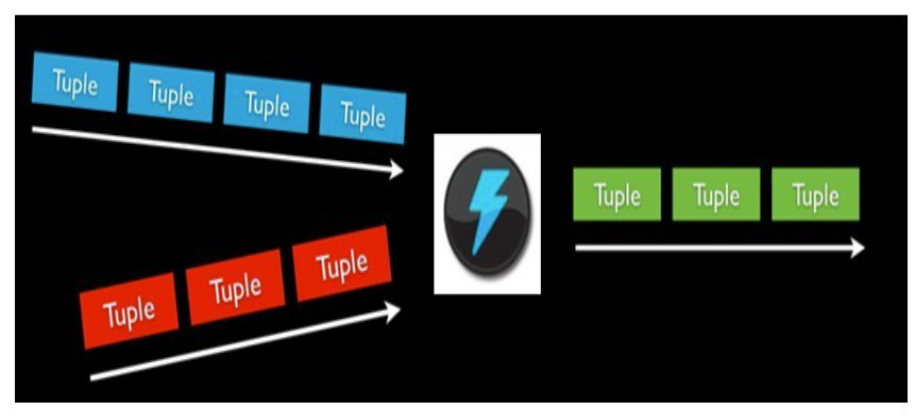
5.4:Storm中的Spouts
消息源spout是Storm裏面一個topology裏面的消息生產者;
一般來說消息源會從一個外部源讀取數據並且向topology裏面發出消息:tuple;
Spouts可以是可靠的也可以是不可靠的:如果這個tuple沒有被storm成功處理,可靠的消息源spouts可以重新發射一個tuple, 但是不可靠的消息源spouts一旦發出一個tuple就不能重發了;
消息源可以發射多條消息流stream:
使用OutputFieldsDeclarer.declareStream來定義多個stream,
然後使用SpoutOutputCollector來發射指定的stream。
5.4:Storm中的Bolts
所有的消息處理邏輯被封裝在bolts裏面;
Bolts可以做很多事情:過濾,聚合,查詢數據庫等等。
Bolts可以簡單的做消息流的傳遞,也可以通過多級Bolts的組合來完成復雜的消息流處理;比如求TopN、聚合操作等(如果要把這個過程做得更具有擴展性那麽可能需要更多的步驟)。
Bolts可以發射多條消息流:
使用OutputFieldsDeclarer.declareStream定義stream;
使用OutputCollector.emit來選擇要發射的stream;
Bolts的主要方法是execute,:
它以一個tuple作為輸入,使用OutputCollector來發射tuple;
通過調用OutputCollector的ack方法,以通知這個tuple的發射者spout;
Bolts一般的流程:
處理一個輸入tuple, 發射0個或者多個tuple, 然後調用ack通知storm自己已經處理過這個tuple了;
storm提供了一個IBasicBolt會自動調用ack。
5.5:Storm中的Stream groupings
定義一個topology的關鍵一步是定義每個bolt接收什麽樣的流作為輸入;
stream grouping就是用來定義一個stream應該如何分配數據給bolts;
Storm裏面有7種類型的stream grouping:
Shuffle Grouping——隨機分組, 隨機派發stream裏面的tuple,保證每個bolt接收到的tuple數目大致相同;
Fields Grouping——按字段分組, 比如按userid來分組, 具有同樣userid的tuple會被分到相同的Bolts裏的一個task, 而不同的userid則會被分配到不同的bolts裏的task;
All Grouping——廣播發送,對於每一個tuple,所有的bolts都會收到;
Global Grouping——全局分組, 這個tuple被分配到storm中的一個bolt的其中一個task。再具體一點就是分配給id值最低的那個task;
Non Grouping——不分組,這個分組的意思是說stream不關心到底誰會收到它的tuple。目前這種分組和Shuffle grouping是一樣的效果, 有一點不同的是storm會把這個bolt放到這個bolt的訂閱者同一個線程裏面去執行;
Direct Grouping——直接分組, 這是一種比較特別的分組方法,用這種分組意味著消息的發送者指定由消息接收者的哪個task處理這個消息。 只有被聲明為Direct Stream的消息流可以聲明這種分組方法。而且這種消息tuple必須使用emitDirect方法來發射。
消息處理者可以通過TopologyContext來獲取處理它的消息的task的id (OutputCollector.emit方法也會返回task的id);
Local or shuffle grouping——如果目標bolt有一個或者多個task在同一個工作進程中,tuple將會被隨機發生給這些tasks。否則,和普通的Shuffle Grouping行為一致。
5.6:Storm中的Workers
一個topology可能會在一個或者多個worker(工作進程)裏面執行;
每個worker是一個物理JVM並且執行整個topology的一部分;
比如,對於並行度是300的topology來說,如果我們使用50個工作進程來執行,那麽每個工作進程會處理其中的6個tasks;
Storm會盡量均勻的工作分配給所有的worker;
5.7:Storm中的Tasks
每一個spout和bolt會被當作很多task在整個集群裏執行
每一個executor對應到一個線程,在這個線程上運行多個task
stream grouping則是定義怎麽從一堆task發射tuple到另外一堆task
可以調用TopologyBuilder類的setSpout和setBolt來設置並行度(也就是有多少個task)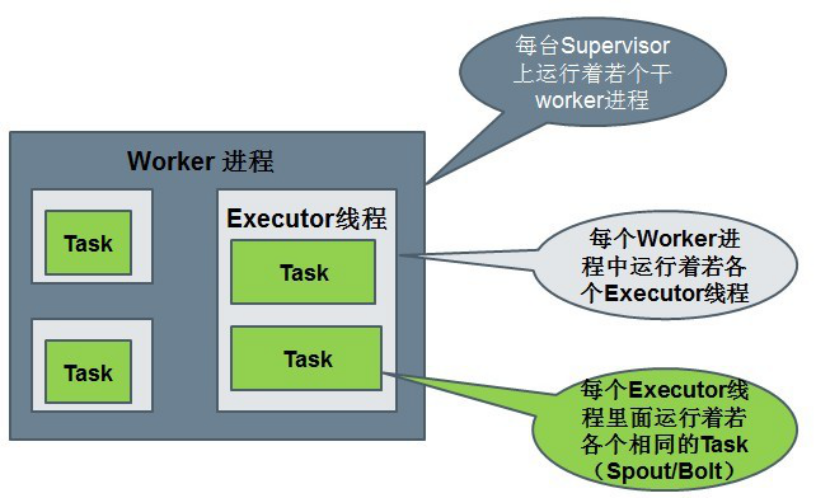
一臉懵逼學習Storm---(一個開源的分布式實時計算系統)