
[翻譯]——SQL Server索引的介紹:SQL Server索引級的階梯
SQL Server索引的介紹:SQL Server索引級的階梯
By David Durant, 2014/11/05 (first published: 2011/02/17)
該系列
本文是樓梯系列的一部分:SQL Server索引的階梯
索引是數據庫設計的基礎,並告訴開發人員使用數據庫非常了解設計器的意圖。不幸的是,當性能問題出現時,索引常常被添加到事後。這裏最後是一個簡單的系列文章,它應該能讓任何數據庫專業人員快速“跟上”他們的步伐
第一個層次引入了SQL Server索引:使SQL Server能夠在最少的時間內找到或修改請求數據的數據庫對象,使用最少的系統資源來達到最大的性能。好的索引還允許SQL服務器實現最大的並發性,因此由一個用戶運行的查詢對其他用戶運行的查詢幾乎沒有影響。最後,索引提供了一種有效的方法來強制執行數據完整性,在創建唯一索引時保證鍵值的唯一性。這個級別是一個介紹;它涵蓋了概念和用法,但將物理細節留給了稍後的層次。
對於數據庫開發人員來說,對索引的深入理解對於一個以上的原因是非常重要的:當一個SQL Server請求從客戶端到達時,SQL Server只有兩種可能的方法來訪問請求的行:
它可以掃描包含數據的表中的每一行,從第一行開始,一直到最後一行,檢查每一行,看它是否滿足請求標準。
或者,如果有一個有益的索引可用,它可以使用索引來定位所請求的數據。
第一個選項總是對SQL Server可用。如果您已經指示SQL Server創建一個有益的索引,那麽第二個選項只能是可用的,但是它可以導致顯著的性能改進,我們稍後將在這個層次上演示。
因為索引有與它們相關的開銷(它們占用空間,它們必須與表保持同步),它們不需要SQL Server。有一個完全沒有索引的數據庫是可能的。它可能會表現得很差,它肯定會有數據完整性問題,但是SQL Server會允許它。
然而,這不是我們想要的。我們都想要一個性能良好的數據庫,具有數據完整性,同時,將索引開銷保持在最小值。這個水平將使我們朝著這個目標前進。
示例數據庫
通過StairWay,我們將用例子來說明關鍵的概念。這些示例基於Microsoft AdventureWorks示例數據庫。我們關註的是“銷售訂單“”的功能。5個表將提供事務性和非事務性數據的良好組合;客戶,銷售人員,產品,銷售訂單,和銷售細節。為了保持註意力集中,我們使用了列的一個子集。
AdventureWorks是標準化的,所以銷售人員信息被分解成三個表;銷售人員、雇員和聯系。對於一些示例,我們將它們作為單個表進行處理。我們將使用的完整的表集以及它們之間的關系如圖1.1所示
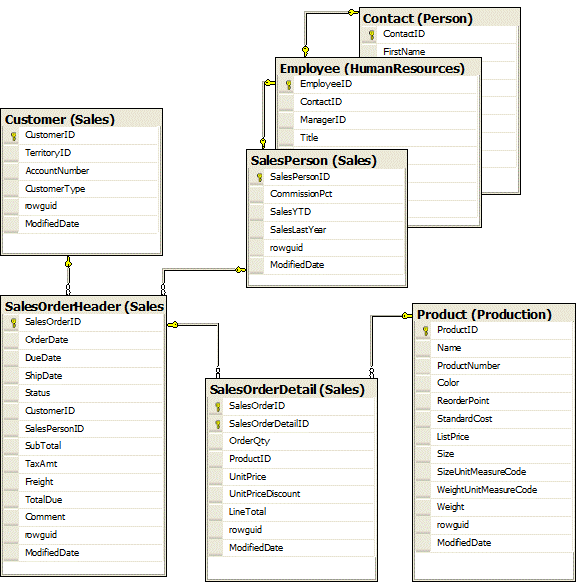
圖1.1:將在此StairWay上使用的AdventureWorks表
註:
在這個階梯級顯示的所有TSQL代碼都可以連同文章一起下載(參見本文底部的鏈接)
索引是什麽?
我們從一個簡短的故事開始我們的索引研究,它使用的是一個古老的,但經過驗證的技術,我們將在本文中引用它來介紹索引的基本概念。
你離開家去辦事。當你回來的時候,你會從你女兒的壘球教練那裏得到一個信息。三名女孩,特雷西,麗貝卡和艾米已經失去了他們的球隊帽子。你能不能在運動用品店轉一下,給姑娘們買帽子。他們的父母會在下一場比賽中給你報銷。
你認識那些女孩,你也認識他們的父母。但你不知道他們的帽子大小。在你鎮上的某個地方有三個住宅,每個都包含你需要的信息。沒問題,你就打電話給父母,把帽子的尺寸拿出來。你拿著你的手機,伸手去拿一個索引——你的電話簿的白頁。
你需要到達的第一個居住地是海倫·邁耶。估計“邁耶”將位於人口中間,你就會跳到白頁中間;只有發現你在頁面上,標題寫著“kline - koerber”。你向前跳躍,到達“nagle - nyeong”頁面。在“maldonado - nagle”頁面上,你可以看到一個更小的跳轉。當你意識到你現在正處於正確的頁面時,你會向下瀏覽頁面,直到到達“Meyer,Helen”線,並獲得電話號碼。使用電話號碼,你可以到達邁耶住所,獲取你需要的信息。
你再重復這個過程兩次,到達另外兩個住處,再獲得兩個帽子大小。
您剛剛使用了一個索引,並且使用它的方式與SQL服務器使用索引的方式相同;因為在白頁和SQL Server索引之間有很大的相似點和不同之處。
實際上,您剛才使用的索引代表了SQL Server支持的兩個SQL Server索引類型:集群化和非集群化。白色頁面最好表示非聚集索引的概念。因此,在這個級別,我們引入了非聚集索引。隨後的級別將引入集群索引,並對這兩種類型進行深入挖掘。
非聚集索引
白色頁面類似於非聚集索引,因為它們不是數據本身的組織;但更確切地說,是一種機制,或者地圖,來幫助你獲取這些數據。數據本身就是我們需要聯系的人。電話公司沒有把城鎮的住宅安排成一個有意義的順序,把房子從一個地方搬到另一個地方,這樣所有的女孩都住在同一個壘球隊的隔壁,而房子不是由居民的姓組織的。相反,它會給你一本書,裏面有每個住宅的入口。這些條目由白色頁面的搜索鍵排序;姓,名,中間名和街道地址。每個條目包含搜索鍵和允許您訪問該住所的數據塊;電話號碼。
就像進入白頁一樣,SQL Server非聚集索引中的每個條目由兩個部分組成:
1、搜索鍵,如姓-名-中間名。在SQL Server術語中,這是索引鍵。
2、與電話號碼相同用途的書簽,允許SQL Server直接導航到表中對應於該索引條目的行。
此外,SQL Server非集群索引項有一些內部使用的頭信息,可能包含一些可選信息。這兩種方法都將在以後的水平上進行討論;在這個時候,對非聚集索引的理解也不是很重要。
與白頁一樣,在搜索鍵序列中維護一個SQL Server索引,以便在一組小的“跳轉”中訪問任何特定的條目。給定搜索鍵,SQL Server可以快速獲取該鍵的索引條目。與白頁不同的是,SQL Server索引是動態的。也就是說,每次添加一行、刪除或有修改的搜索鍵列值時,SQL服務器都會更新索引。
就像在白頁裏的條目順序不同於城鎮裏的地理順序一樣;非聚集索引中的條目序列與表中的行序列不相同。索引中的第一個條目可能是表中的最後一行,而索引中的第二個條目可能是表中的第一行。如果事實,不像一個索引,它的條目總是有意義的序列;一個表的行可以完全沒有排序。
當您創建一個索引時,SQL Server生成並在底層表中的每一行的索引中保持一個條目(當我們覆蓋篩選的索引時,在以後的級別中會遇到這個一般規則的例外情況)。您可以在表上創建多個非聚集索引,但您不能有一個索引,該索引包含來自多個表的數據。
最大的區別是:SQL Server不能使用電話。它必須使用索引條目中的bookmark部分中的信息導航到表的相應行。每當SQL Server需要數據行中的任何信息,而不是對應的索引項,比如Tracy Meyer的壘球帽大小時,就需要這樣做。因此,為了更好的類比,一個白頁的條目包含一組GPS坐標而不是一個電話號碼。然後使用GPS坐標導航到由白頁條目表示的住所。
創建並從非聚集索引中受益
我們通過查詢示例數據庫來結束這個級別。請確保您使用的是用於SQL Server 2005的AdventureWorks版本,它可以被SQL Server 2008使用。AdventureWorks2008數據庫有一個不同的表結構,下面的查詢將會失敗。我們每次都會運行相同的查詢;但是,在創建表上的索引之前,第一個執行將會發生,第二個執行將在我們創建一個索引之後。每次,SQL Server都會告訴我們在檢索請求信息時做了多少工作。我們將在我們的聯系表中尋找“海倫·梅耶”排(她的排在桌子中間)。最初,表在FirstName列或LastName列上都沒有索引。為了確保您能多次運行這個例子,請確保我們將在第三批處理的索引不存在,通過運行以下代碼:
1 IF EXISTS (SELECT * FROM sys.indexes 2 WHERE OBJECT_ID = OBJECT_ID(‘Person.Contact‘) 3 AND name = ‘FullName‘) 4 DROP INDEX Person.Contact.FullName;
清單1.1 -確保索引不存在
1 SET STATISTICS io ON 2 SET STATISTICS time ON 3 GO
清單1.2 -打開統計數據
上面的批處理通知SQL Server,我們希望我們的查詢將性能信息作為輸出的一部分返回。
第二個命令批處理:
1 SELECT * 2 FROM Person.Contact 3 WHERE FirstName = ‘Helen‘ 4 AND LastName = ‘Meyer‘; 5 GO
清單1.3 -檢索一些數據
第二批檢索“海倫·邁耶”行:
584 Helen Meyer [email protected] 0-519-555-0112
加上以下的業績信息:
Table ‘Contact‘. Scan count 1, logical reads 569.
SQL Server Execution Times: CPU time = 3 ms.
這個輸出告訴我們,我們的請求執行了569個邏輯IOs,需要大約3毫秒的處理器時間。處理器時間的值可能不同。
第三個命令批處理:
1 CREATE NONCLUSTERED INDEX FullName
2 ON Person.Contact
3 ( LastName, FirstName );
4 GO
清單1.4—創建非聚集索引
此批處理在Contact表的第一個和最後一個名稱列上創建一個非聚集的復合索引。復合索引是一個索引,包含多個列來確定索引行序列。
第四個命令批處理:
1 SELECT * 2 FROM Person.Contact 3 WHERE FirstName = ‘Helen‘ 4 AND LastName = ‘Meyer‘; 5 GO
清單1.3(再一次)
這最後一批是我們最初的SELECT語句的重新執行。我們得到和以前一樣的行;但這一次的性能統計數據是不同的
Table ‘Contact‘. Scan count 1, logical reads 4.
SQL Server Execution Times: CPU time = 0 ms.
這個輸出告訴我們,我們的請求只需要4個邏輯IOs;而且需要一個不可估量的少量處理器時間來檢索“海倫·梅耶”行。
結論
創建良好的索引可以極大地提高數據庫性能。在下一層,我們將開始研究索引的物理結構。我們將研究為什麽這個非聚集索引對這個查詢如此有利,為什麽可能不總是這樣。未來的級別將包括其他類型的索引、索引的額外收益、與索引相關的成本、監視和維護索引和最佳實踐;所有的目標都是為您提供必要的知識,以便為您自己的數據庫中的表創建最佳索引方案。
本文翻譯網址:http://www.sqlservercentral.com/articles/Stairway+Series/72284/
[翻譯]——SQL Server索引的介紹:SQL Server索引級的階梯