
數據處理不等式:Data Processing Inequality
我是在差分隱私下看到的,新解決方案的可用性肯定小於原有解決方案的可用性,也就是說信息的後續處理只會降低所擁有的信息量。
那麽如果這麽說的話為什麽還要做特征工程呢,這是因為該不等式有一個巨大的前提就是數據處理方法無比的強大,比如很多的樣本要分類,我們做特征提取後,SVM效果很好 ,但是如果用DNN之類的CNN、AuToEncoder,那麽效果反而不如原來特征。這樣就能理解了,DNN提取能力更強,那麽原始就要有更多的信息,在新特征下無論怎麽提取,信息就那麽多。
信息量越多越好麽?肯定不是,否則為什麽PCA要做降噪和去冗余呢?我們的目的是有效的信息最大化。
另外一種理解就是從互信息不為0(信息損失)來解釋。
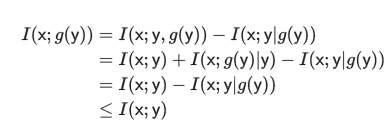
從而
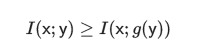
那麽如何在處理過程中不丟失有效信息呢?這時候就需要數學上的充分統計量,也就是g是y的充分統計量。
數據處理不等式:Data Processing Inequality
相關推薦
數據處理不等式:Data Processing Inequality
ext right 工程 log src enter 可用 proc 互信 我是在差分隱私下看到的,新解決方案的可用性肯定小於原有解決方案的可用性,也就是說信息的後續處理只會降低所擁有的信息量。 那麽如果這麽說的話為什麽還要做特征工程呢,這是因為該不等式有一個巨大
資料處理不等式:Data Processing Inequality
我是在差分隱私下看到的,新解決方案的可用性肯定小於原有解決方案的可用性,也就是說資訊的後續處理只會降低所擁有的資訊量。 那麼如果這麼說的話為什麼還要做特徵工程呢,這是因為該不等式有一個巨大的前提就是資料處理方法無比的強大,比如很多的樣本要分類,我們做特徵提取後,SVM效果很好 ,但是如果用DNN之類
視音頻數據處理入門:FLV封裝格式解析
tail rip 主頁 typedef gda ack print 地址 視頻 ===================================================== 視音頻數據處理入門系列文章: 視音頻數據處理入門:RGB、YUV像素數據處理 視音頻數
微軟開源大規模數據處理項目 Data Accelerator
和數 代碼 接收器 監控 開源 github 使用 blank -o 微軟開源了一個原為內部使用的大規模數據處理項目 Data Accelerator。自 2017 年開發以來,該項目已經大規模應用在各種微軟產品工作管道上。 據微軟官方開源博客介紹,Data Accele
海量數據處理:Hash映射 + Hash_map統計 + 堆/快速/歸並排序
針對 內存 value 快速 round div ack 數據處理 訪問 海量日誌數據,提取出某日訪問百度次數最多的那個IP。 既然是海量數據處理,那麽可想而知,給我們的數據那就一定是海量的。 針對這個數據的海量,我們如何著手呢?對的,無非就是分而治之/hash映射 +
前端數據處理:參數的獲取和組織發送
字符 字符串 div ren pri 其他 發送 其中 處理 1.var t = $(this); 當前DOM節點為開始 2.var uid = t.parent("dd).attr("perid"); 利用jquery獲取當前DOM節點父子,兄弟的屬性值 3."<d
python數據處理:pandas基礎
log eat ges 處理 保留 sed lang sce rop 本文資料來源: Python for Data Anylysis: Chapter 5 10 mintues to pandas: http://pandas.pydata.org/pandas-
產品經理最花時間的2件事:異常邏輯梳理與數據處理
處理 新的 att files 漏鬥 流程 計時 現實 需要 冰山:異常邏輯梳理 也許你用了九牛二虎之力,終於把產品的主流程梳理清楚了,但是你看到的只是產品冰山海面上的那10%,剩下的90%是海面下各種情況的異常邏輯。 ? 10%的冰山和90%的冰山 任何一個產品功能邏輯
R實戰 第三篇:數據處理
ase 語言 dex test 矩陣 表達 set mat cond 在實際分析數據之前,必須對數據進行清理和轉化,使數據符合相應的格式,提高數據的質量。數據處理通常包括增加新的變量、處理缺失值、類型轉換、數據排序、數據集的合並和獲取子集等。 一,增加新的變量 通常需要
R實戰 第三篇:數據處理(基礎)
計算 edi 字符數 定義函數 空間 數值 sqrt 字符類 ceil 數據結構用於存儲數據,不同的數據結構對應不同的操作方法,對應不同的分析目的,應選擇合適的數據結構。在處理數據時,為了便於檢查數據對象,可以通過函數attributes(x)來查看數據對象的屬性,str(
知識篇:新一代的數據處理平臺Hadoop簡介
Hadoop在雲計算和大數據大行其道的今天,Hadoop及其相關技術起到了非常重要的作用,是這個時代不容忽視的一個技術平臺。事實上,由於其開源、低成本和和前所未有的擴展性,Hadoop正成為新一代的數據處理平臺。Hadoop是基於Java語言構建的一套分布式數據處理框架,從其歷史發展角度我們就可以看出,Had
kaggle入門項目:Titanic存亡預測(二)數據處理
理解 ima 簡單 標識符 數據處理 let ger 好的 元素 原kaggle比賽地址:https://www.kaggle.com/c/titanic 原kernel地址:A Data Science Framework: To Achieve 99% Accuracy
第十二節:pandas缺失數據處理
mage size img alt 替換 rop inf 圖片 pandas 1、isnull():檢查是否含有確實數據 2、fillna():填充缺失數據 3、dropna() :刪除缺失值 4、replace():替換值 第十二節:pandas缺失數據處理
教你如何迅速秒殺掉:99%的海量數據處理面試題(轉)
用法 10個 rdquo 其它 queue 既然 nbsp 分解 -o 教你如何迅速秒殺掉:99%的海量數據處理面試題本文經過大量細致的優化後,收錄於我的新書《編程之法:面試和算法心得》第六章中,新書目前已上架京東/當當 作者:July出處:結構之法算法之道blog
機器學習導圖系列(1):數據處理
探索 com machine 數學 選擇 機器學習算法 png 壓縮 網絡 機器學習導圖系列教程旨在幫助引導開發者對機器學習知識網絡有一個系統的概念,其中具體釋義並未完善,需要開發者自己探索才能對具體知識有深入的掌握。本項目靈感來自Daniel Formoso的github
MATLAB 常用數據處理命令
記錄 media sort 向量 排列 行號 常用 ascend des 1. 元素排序: sort(X)返回一個對X中的元素按升序排列的新向量 [Y,I]=sort(A,dim,mode) 若dim=1,則按列排;若dim=2,則按行排(dim默認為1) 若mode=as
數據說話了:6萬一房成“全球第二貴“ 狂跌的深圳房價5月又回暖?
國家 swd src alt 數據庫 還在 繼續 webp 數據管理 深圳是一個房價不低的城市,這點沒人敢說否。的確,深圳經過20年的樓市發展,從05年的6000元,到2008年的1萬,到2005年的3.5萬,到2017年的5萬,這就是房價的歷程。 但是3月樓市
python接口自動化5-Json數據處理
color post請求 交換 類型 解析 str encode con api 前言 有些post的請求參數是json格式的,這個前面第二篇post請求裏面提到過,需要導入json模塊處理。 一般常見的接口返回數據也是json格式的,我們在做判斷時候,往往只需要提取其
Python進行數據分析之一:相關Package的安裝
ans 防止 log matplot 行數據 解釋 原型 簡單 下載 一、為什麽要使用Python進行數據分析? python擁有一個巨大的活躍的科學計算社區,擁有不斷改良的庫,能夠輕松的集成C,C++,Fortran代碼(Cython項目),可以同時用於研究和原型的構建以
python pandas模塊,nba數據處理(1)
excel inpu con num 表結構 固定 sql 面向列 lines pandas提供了使我們能夠快速便捷地處理結構化數據的大量數據結構和函數。pandas兼具Numpy高性能的數組計算功能以及電子表格和關系型數據(如SQL)靈活的數據處理能力。它提供了復雜精細的