
Logistic Regression-Cost Fuction
1. 二分類問題
- 樣本:
,訓練樣本包含
個;
- 其中
,表示樣本
包含
個特征;
,目標值屬於0、1分類;
- 訓練數據:
輸入神經網絡時樣本數據的形狀:
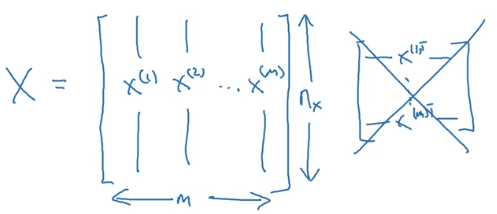
目標數據的形狀:
2. logistic Regression
邏輯回歸中,預測值:
其表示為1的概率,取值範圍在 之間。 引入Sigmoid函數,預測值:
其中
註意點:函數的一階導數可以用其自身表示,
這裏可以解釋梯度消失的問題,當 時,導數最大,但是導數最大為
,這裏導數僅為原函數值的0.25倍。 參數梯度下降公式的不斷更新,
會變得越來越小,每次叠代參數更新的步伐越來越小,最終接近於0,產生梯度消失的現象。
3. logistic回歸 損失函數
Loss function
一般經驗來說,使用平方錯誤(squared error)來衡量Loss Function:
但是,對於logistic regression 來說,一般不適用平方錯誤來作為Loss Function,這是因為上面的平方錯誤損失函數一般是非凸函數(non-convex),其在使用低度下降算法的時候,容易得到局部最優解,而不是全局最優解。因此要選擇凸函數。
邏輯回歸的Loss Function:
- 當
時,
。如果
越接近1,
,表示預測效果越好;如果
,表示預測效果越差;
- 當
時,
。如果
越接近0, - 我們的目標是最小化樣本點的損失Loss Function,損失函數是針對單個樣本點的。
Cost function
全部訓練數據集的Loss function總和的平均值即為訓練集的代價函數(Cost function)。
- Cost function是待求系數w和b的函數;
- 我們的目標就是叠代計算出最佳的w和b的值,最小化Cost function,讓其盡可能地接近於0。
################################################################################################################################################
Logistic Regression: Cost Function
To train the parameters ?? and ??, we need to define a cost function. Recap:
???(??) = ??(??????(??) + ??), where ??(??(??))= 1 ??(??) the i-th training example 1+ ?????(??)
?????????? {(??(1), ??(1) ), ? , (??(??), ??(??) )}, ???? ???????? ???(??) ≈ ??(??)
Loss (error) function:
The loss function measures the discrepancy between the prediction (???(??)) and the desired output (??(??)). In other words, the loss function computes the error for a single training example.
??(???(??), ??(??)) = 1 (???(??) ? ??(??))2 2
??(???(??), ??(??)) = ?( ??(??) log(???(??)) + (1 ? ??(??))log(1 ? ???(??))
-
If ??(??) = 1: ??(???(??), ??(??)) = ? log(???(??)) where log(???(??)) and ???(??) should be close to 1
-
If ??(??) = 0: ??(???(??), ??(??)) = ? log(1 ? ???(??)) where log(1 ? ???(??)) and ???(??) should be close to 0
Cost function
The cost function is the average of the loss function of the entire training set. We are going to find the parameters ?? ?????? ?? that minimize the overall cost function.
1?? 1??
??(??, ??) = ?? ∑ ??(???(??), ??(??)) = ? ?? ∑[( ??(??) log(???(??)) + (1 ? ??(??))log(1 ? ???(??))]??=1 ??=1
註意:
1)定義cost function的目的是為了訓練logistic 回歸模型的參數 w 和 b
loss fuction 是在單個訓練樣本上定義的,而cost fuction 是在全體訓練樣本上定義的
Logistic Regression-Cost Fuction