
Ceph糾刪碼編碼機制調研
1 Ceph簡述
Ceph是一種性能優越,可靠性和可擴展性良好的統一的分布式雲存儲系統,提供對象存儲、塊存儲、文件存儲三種存儲服務。Ceph文件系統中不區分節點中心,在理論上可以實現系統規模的無限擴展。Ceph文件系統使用了較為簡單的數據地址管理方法,通過計算的方式直接得到數據存放的位置。其客戶端程序只需要根據數據ID經過簡單的計算就可以決定數據存放的位置。
2 存儲容錯機制簡述
2.1 副本冗余容錯機制
基於副本冗余的容錯機制是將原始數據復制成多份,每一份稱為一個副本。將這些副本分別存放在集群中的不同節點上,當集群中有些節點出現故障時,只要其余健康節點中任一個節點擁有副本,用戶就可以獲取該數據。當前眾多存儲系統(包括Ceph)都采用副本數為3的副本冗余容錯機制,這種機制能很好地保證數據可靠性,但也會極大降低存儲空間利用率。
在Ceph中,用戶可以根據需要創建存儲池,並設置存儲池中數據的副本數目,每個數據副本被分到不同的對象存儲設備(OSD)上,當存儲設備中有故障,可以從其他健康的設備上獲取數據。
2.2 糾刪碼容錯機制
在存儲系統中,糾刪碼技術主要是通過利用糾刪碼算法將原始的數據進行編碼得到冗余,並將數據和冗余一並存儲起來,以達到容錯的目的。其基本思想是將k塊原始的數據元素通過一定的編碼計算,得到m塊冗余元素。對於這k+m塊的元素,當其中任意的m塊元素出錯(包括數據和冗余出錯)時,均可以通過對應的重構算法恢復出原來的k塊數據。基於糾刪碼的方法與傳統的副本冗余技術相比,具有冗余度低、磁盤利用率高等優點。
3 糾刪碼簡述
3.1 糾刪碼中相關概念
數據塊大小指的是數據塊進行編碼計算時,數據分塊(原始數據塊Di或校驗數據塊Cj)的大小,在不同的存儲系統中數據塊大小不同,在RAID存儲系統中,常見的分塊大小是4KB~128KB,在分布式存儲系統中數據塊較大,一般為64MB大小。
條帶是糾錯編碼存儲一次性讀入或寫入數據的大小,在系統碼中,一個條帶往往包含了k個原始數據塊和m個校驗塊。
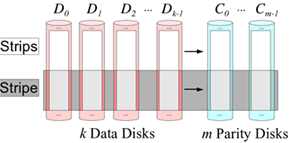
編碼矩陣GM 定義了數據是如何編碼為冗余數據的,因為糾刪碼的編碼過程可以通過一個編碼矩陣GM和分塊數據的乘法(點積)來表示。以下圖為例,C0 ~ C5 是冗余數據,所有的冗余數據可以表示為GM × D{D0、D1、D2、D3} 的乘法,每一個冗余數據塊Ci 是矩陣的對應的一行和數據塊的乘積(黃色標示)。編碼矩陣中GM每一個元素則是對應原始數據塊的乘法系數。編碼矩陣的列數對應著原始數據分塊個數(k),行數對應著編碼後所有數據塊個數(n)。
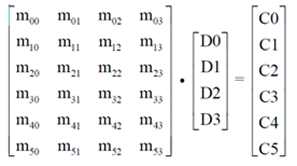
3.2 典型的糾刪碼類型
3.2.1 範德蒙RS糾刪碼
RS編碼實際上就是利用生成矩陣與數據列向量的乘積來計算得到信息列向量的。其重構算法實際上也是利用未出錯信息所對應的殘余生成矩陣的逆矩陣與未出錯的信息列向量相乘來恢復原始數據的。.但是在RS編碼重構原理的推導過程中,有一個條件至關重要,那就是未出錯信息所對應的殘余生成矩陣在GF(2w)域上必須要滿足可逆的條件。更進一步來說,為了滿足RS編碼在任何情況下均是可重構的,對於任意的ms個元素出錯時,均要能夠通過重構算法恢復出數據,這就要求對於任意的n個元素(n的含義是指去掉m個出錯元素以後剩下的n個未出錯的元素),其對應的殘余生成矩陣均要在GF(2w)域上滿足可逆,這就對RS編碼的生成矩陣提出了很高的要求。在生成矩陣中, 要求任意n個行向量均必須在 GF(2w)域上滿足線性無關(行向量線性無關是矩陣可逆的充要條件)。
範德蒙矩陣有著良好的特性,在GF(2w)域上,對範德蒙矩陣進行初等變換,將其前n行變為單位矩陣,即可保證生成矩陣可逆,基於這個生成矩陣的RS糾刪碼為範德蒙RS糾刪碼。其編碼的生成矩陣為:

3.2.2 柯西RS糾刪碼
柯西RS糾刪碼用柯西矩陣代替範德蒙矩陣,得到更為簡單的生成矩陣。研究者通過簡單改造,使解碼過程更為簡單。柯西碼解碼不用求大矩陣的逆,而是把乘法除法運算分別轉化為有限域上的加法和減法運算,可用異或實現。因此,柯西RS糾刪碼運算復雜度低於範德蒙RS糾刪碼。采用柯西矩陣進行 Erasure code 編碼過程描述如下:

4 Ceph容錯機制
4.1 傳統容錯機制
Ceph中采用的是副本冗余與糾刪碼冗余算法的綜合容錯機制。基於副本冗余策略,用戶可以根據需要創建存儲池,並設置存儲池中數據的副本數目,每個數據副本被分到不同的對象存儲設備(OSD)上,當存儲設備中有故障,可以從其他健康的設備上獲取數據。基於糾刪碼冗余策略,Ceph添加了幾個開源的糾刪碼庫,提供不同的糾刪碼算法,用戶可根據需要選擇糾刪碼算法類型,並創建相應的糾刪碼池。
4.2 基於冷熱數據分層的容錯機制
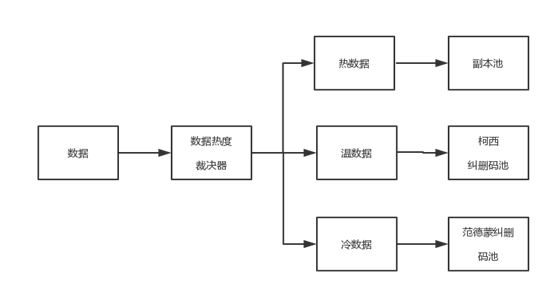
存儲中數據可根據訪問熱度分為三種:熱數據、溫數據和冷數據。熱數據通常需要在高性能、高度可用、高要求的環境下即時存取。溫數據處於近線或在線備份環境中,用戶需要快速訪問這些數據,但訪問的次數較少。冷數據通常訪問次數極少,通常用於歸檔備份。針對雲存儲中數據訪問熱度不同,提出一種基於數據熱度分層的容錯機制。
所有數據先按照副本策略存儲,本機制對存入系統的數據,實時統計該數據的被訪問頻率,設定熱數據、溫數據、冷數據閾值,高於熱數據閾值的判斷為熱數據,低於冷數據閾值則判定為冷數據,在冷熱數據閾值之間的判定為溫數據。每3個月進行一次數據熱度劃分,數據被訪問頻率高於熱數據閾值時,判斷為熱數據,存放在副本池裏,該存儲池采用副本容錯機制。數據訪問頻率低於冷數據閾值時,判定為冷數據,存放在範德蒙RS糾刪碼池裏,該存儲池采用範德蒙RS糾刪碼容錯機制。對於溫數據,存放在柯西糾刪碼池裏,該存儲池采用改進的柯西RS糾刪碼容錯機制。
Ceph糾刪碼編碼機制調研