
分布式架構的演進,分析的很詳細,很到位
鏈接:https://www.zhihu.com/question/22764869/answer/31277656
來源:知乎
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請註明出處。
首先推薦4本書
大型分布式網站架構設計與實踐
http://item.jd.com/11529266.html
大型網站技術架構:核心原理與案例分析
http://item.jd.com/11322972.html
大型網站系統與Java中間件實踐
http://item.jd.com/11449803.html
分布式Java應用:基礎與實踐
http://item.jd.com/10144196.html
貌似都是4位阿裏人寫的,一本一本的看吧,絕對會增強你的內功。下面是本人的一個簡要小結,供參考。

分布式架構的演進
系統架構演化歷程-初始階段架構
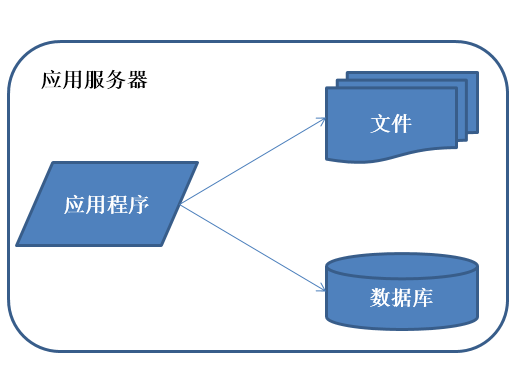
初始階段 的小型系統 應用程序、數據庫、文件等所有的資源都在一臺服務器上通俗稱為LAMP
特征:
應用程序、數據庫、文件等所有的資源都在一臺服務器上。
描述:
通常服務器操作系統使用linux,應用程序使用PHP開發,然後部署在Apache上,數據庫使用Mysql,匯集各種免費開源軟件以及一臺廉價服務器就可以開始系統的發展之路了。
系統架構演化歷程-應用服務和數據服務分離
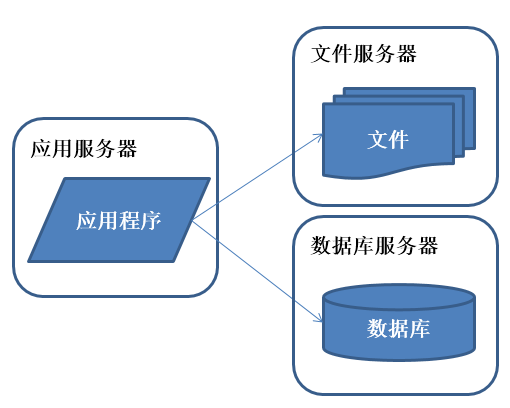
好景不長,發現隨著系統訪問量的再度增加,webserver機器的壓力在高峰期會上升到比較高,這個時候開始考慮增加一臺webserver
特征:
應用程序、數據庫、文件分別部署在獨立的資源上。
描述:
數據量增加,單臺服務器性能及存儲空間不足,需要將應用和數據分離,並發處理能力和數據存儲空間得到了很大改善。
系統架構演化歷程-使用緩存改善性能
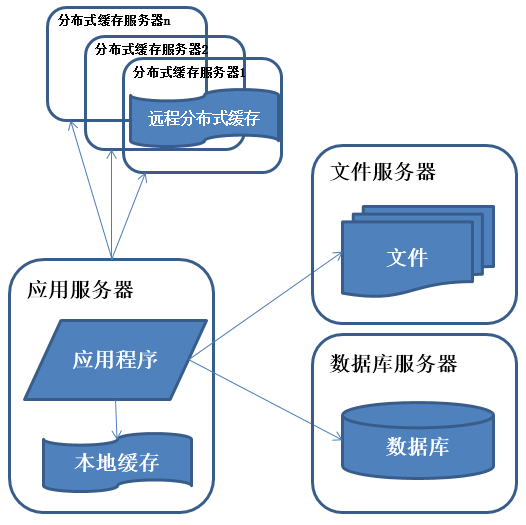
特征:
數據庫中訪問較集中的一小部分數據存儲在緩存服務器中,減少數據庫的訪問次數,降低數據庫的訪問壓力。
描述:
系統訪問特點遵循二八定律,即80%的業務訪問集中在20%的數據上。
緩存分為本地緩存和遠程分布式緩存,本地緩存訪問速度更快但緩存數據量有限,同時存在與應用程序爭用內存的情況。
系統架構演化歷程-使用應用服務器集群
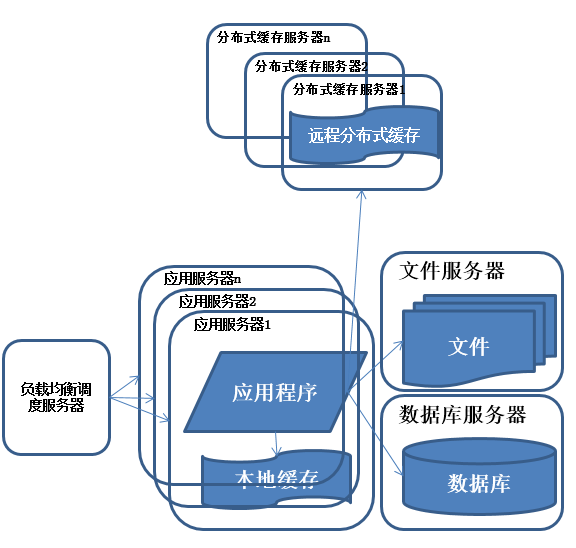
在做完分庫分表這些工作後,數據庫上的壓力已經降到比較低了,又開始過著每天看著訪問量暴增的幸福生活了,突然有一天,發現系統的訪問又開始有變慢的趨勢了,這個時候首先查看數據庫,壓力一切正常,之後查看webserver,發現apache阻塞了很多的請求,而應用服務器對每個請求也是比較快的,看來 是請求數太高導致需要排隊等待,響應速度變慢
特征:
多臺服務器通過負載均衡同時向外部提供服務,解決單臺服務器處理能力和存儲空間上限的問題。
描述:
使用集群是系統解決高並發、海量數據問題的常用手段。通過向集群中追加資源,提升系統的並發處理能力,使得服務器的負載壓力不再成為整個系統的瓶頸。
系統架構演化歷程-數據庫讀寫分離
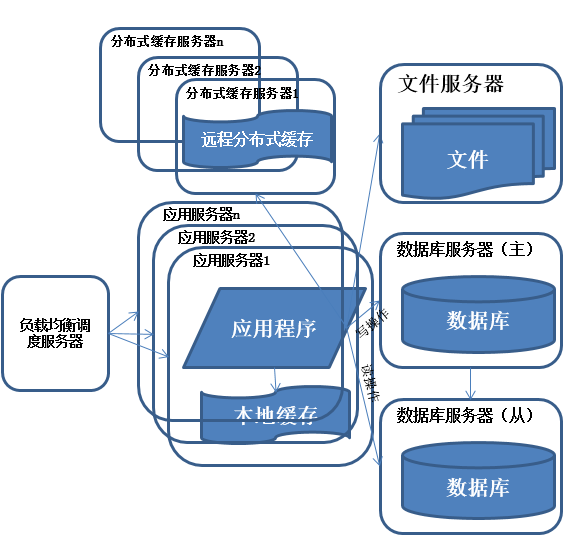
享受了一段時間的系統訪問量高速增長的幸福後,發現系統又開始變慢了,這次又是什麽狀況呢,經過查找,發現數據庫寫入、更新的這些操作的部分數據庫連接的資源競爭非常激烈,導致了系統變慢
特征:
多臺服務器通過負載均衡同時向外部提供服務,解決單臺服務器處理能力和存儲空間上限的問題。
描述:
使用集群是系統解決高並發、海量數據問題的常用手段。通過向集群中追加資源,使得服務器的負載壓力不在成為整個系統的瓶頸。
系統架構演化歷程-反向代理和CDN加速
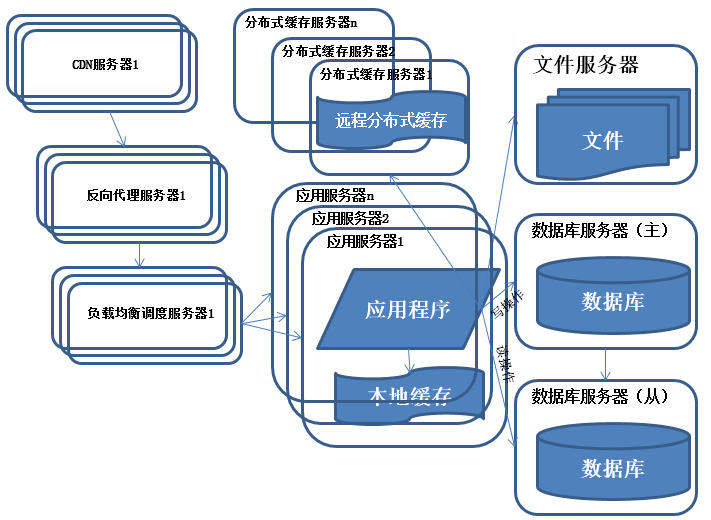
特征:
采用CDN和反向代理加快系統的 訪問速度。
描述:
為了應付復雜的網絡環境和不同地區用戶的訪問,通過CDN和反向代理加快用戶訪問的速度,同時減輕後端服務器的負載壓力。CDN與反向代理的基本原理都是緩存。
系統架構演化歷程-分布式文件系統和分布式數據庫
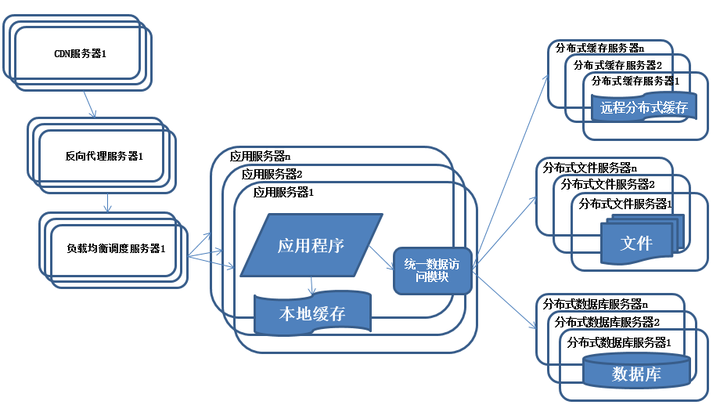
隨著系統的不斷運行,數據量開始大幅度增長,這個時候發現分庫後查詢仍然會有些慢,於是按照分庫的思想開始做分表的工作
特征:
數據庫采用分布式數據庫,文件系統采用分布式文件系統。
描述:
任何強大的單一服務器都滿足不了大型系統持續增長的業務需求,數據庫讀寫分離隨著業務的發展最終也將無法滿足需求,需要使用分布式數據庫及分布式文件系統來支撐。
分布式數據庫是系統數據庫拆分的最後方法,只有在單表數據規模非常龐大的時候才使用,更常用的數據庫拆分手段是業務分庫,將不同的業務數據庫部署在不同的物理服務器上。
系統架構演化歷程-使用NoSQL和搜索引擎
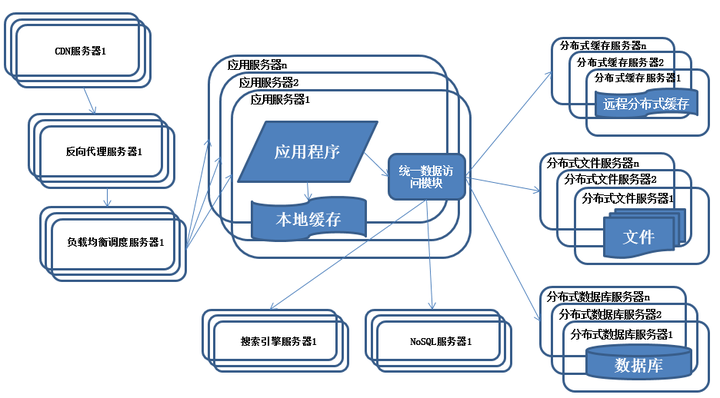
特征:
系統引入NoSQL數據庫及搜索引擎。
描述:
隨著業務越來越復雜,對數據存儲和檢索的需求也越來越復雜,系統需要采用一些非關系型數據庫如NoSQL和分數據庫查詢技術如搜索引擎。應用服務器通過統一數據訪問模塊訪問各種數據,減輕應用程序管理諸多數據源的麻煩。
系統架構演化歷程-業務拆分
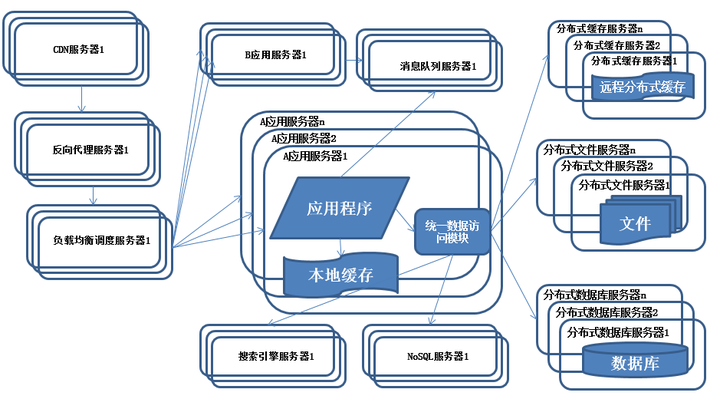
特征:
系統上按照業務進行拆分改造,應用服務器按照業務區分進行分別部署。
描述:
為了應對日益復雜的業務場景,通常使用分而治之的手段將整個系統業務分成不同的產品線,應用之間通過超鏈接建立關系,也可以通過消息隊列進行數據分發,當然更多的還是通過訪問同一個數據存儲系統來構成一個關聯的完整系統。
縱向拆分:
將一個大應用拆分為多個小應用,如果新業務較為獨立,那麽就直接將其設計部署為一個獨立的Web應用系統
縱向拆分相對較為簡單,通過梳理業務,將較少相關的業務剝離即可。
橫向拆分:將復用的業務拆分出來,獨立部署為分布式服務,新增業務只需要調用這些分布式服務
橫向拆分需要識別可復用的業務,設計服務接口,規範服務依賴關系。
系統架構演化歷程-分布式服務
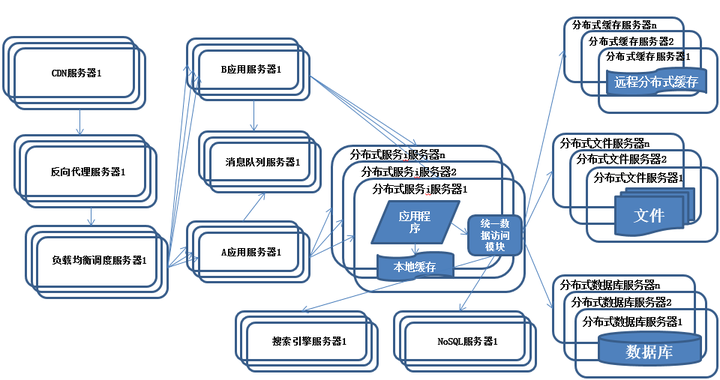
特征:
公共的應用模塊被提取出來,部署在分布式服務器上供應用服務器調用。
描述:
隨著業務越拆越小,應用系統整體復雜程度呈指數級上升,由於所有應用要和所有數據庫系統連接,最終導致數據庫連接資源不足,拒絕服務。
Q:分布式服務應用會面臨哪些問題?
A:
(1) 當服務越來越多時,服務URL配置管理變得非常困難,F5硬件負載均衡器的單點壓力也越來越大。
(2) 當進一步發展,服務間依賴關系變得錯蹤復雜,甚至分不清哪個應用要在哪個應用之前啟動,架構師都不能完整的描述應用的架構關系。
(3) 接著,服務的調用量越來越大,服務的容量問題就暴露出來,這個服務需要多少機器支撐?什麽時候該加機器?
(4) 服務多了,溝通成本也開始上升,調某個服務失敗該找誰?服務的參數都有什麽約定?
(5) 一個服務有多個業務消費者,如何確保服務質量?
(6) 隨著服務的不停升級,總有些意想不到的事發生,比如cache寫錯了導致內存溢出,故障不可避免,每次核心服務一掛,影響一大片,人心慌慌,如何控制故障的影響面?服務是否可以功能降級?或者資源劣化?
Java分布式應用技術基礎
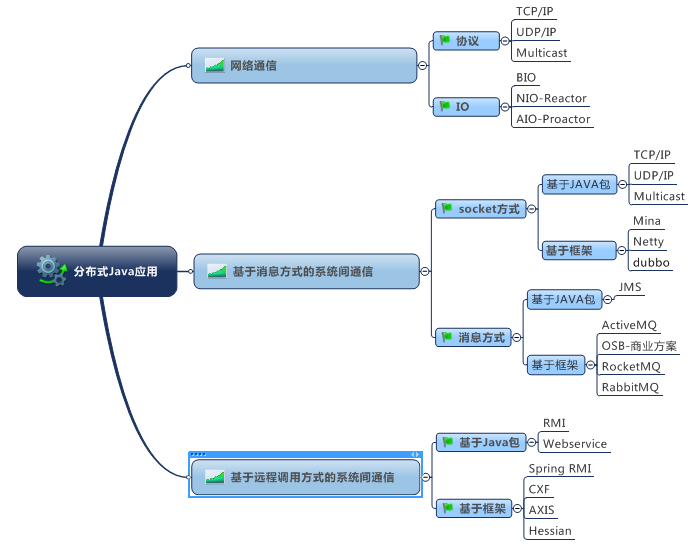
分布式服務下的關鍵技術:消息隊列架構
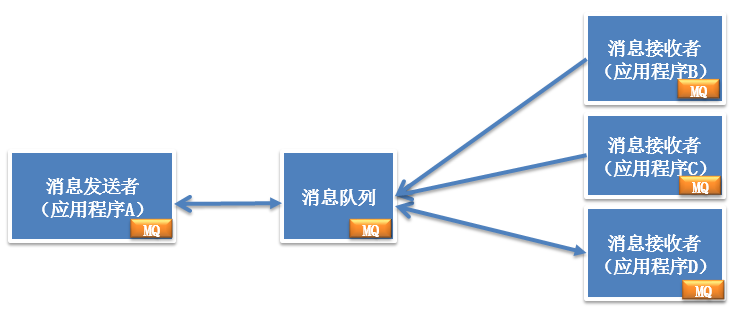
消息對列通過消息對象分解系統耦合性,不同子系統處理同一個消息
分布式服務下的關鍵技術:消息隊列原理
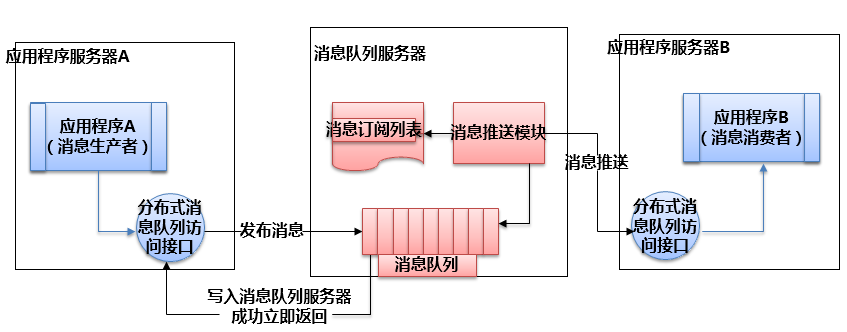
分布式服務下的關鍵技術:服務框架架構
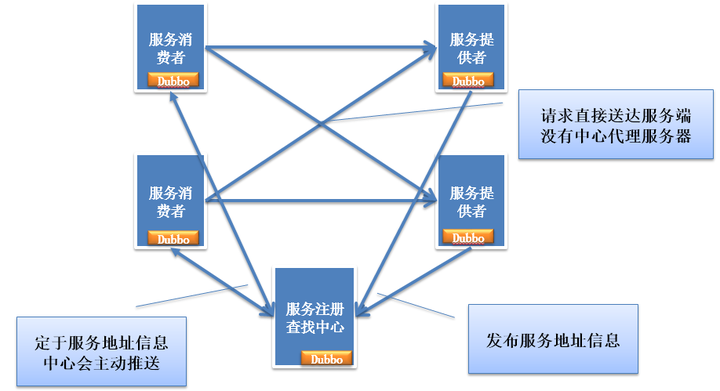
服務框架通過接口分解系統耦合性,不同子系統通過相同的接口描述進行服務啟用
服務框架是一個點對點模型
服務框架面向同構系統
適合:移動應用、互聯網應用、外部系統
分布式服務下的關鍵技術:服務框架原理
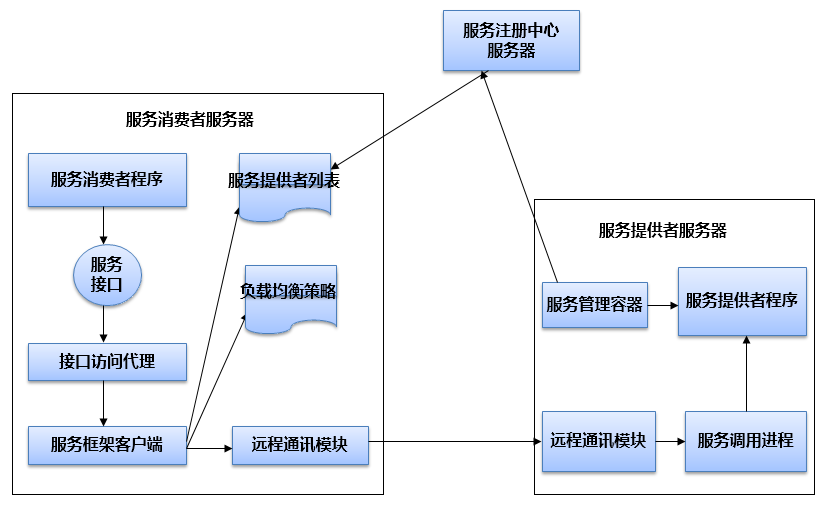
分布式服務下的關鍵技術:服務總線架構
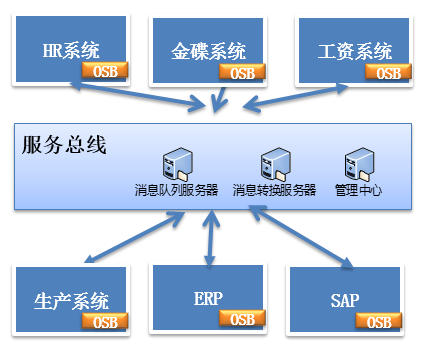
服務總線同服務框架一樣,均是通過接口分解系統耦合性,不同子系統通過相同的接口描述進行服務啟用
服務總線是一個總線式的模型
服務總線面向同構、異構系統
適合:內部系統
分布式服務下的關鍵技術:服務總線原理
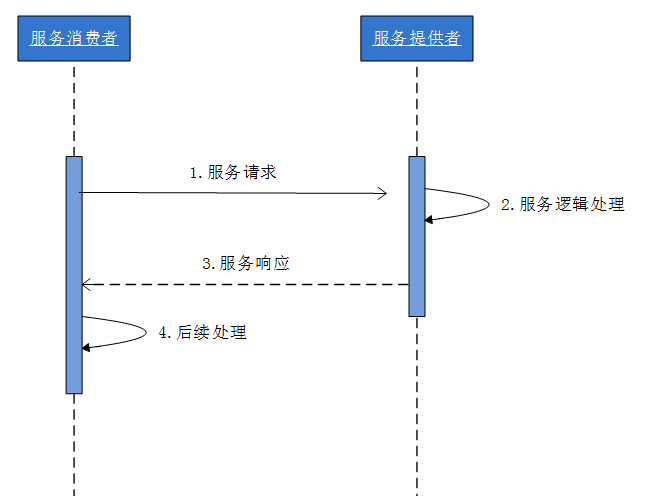
分布式架構下系統間交互的5種通信模式
request/response模式(同步模式):客戶端發起請求一直阻塞到服務端返回請求為止。
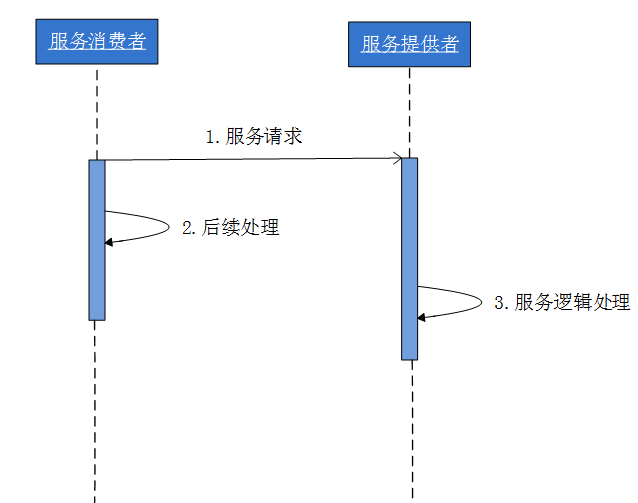
Callback(異步模式):客戶端發送一個RPC請求給服務器,服務端處理後再發送一個消息給消息發送端提供的callback端點,此類情況非常合適以下場景:A組件發送RPC請求給B,B處理完成後,需要通知A組件做後續處理。
Future模式:客戶端發送完請求後,繼續做自己的事情,返回一個包含消息結果的Future對象。客戶端需要使用返回結果時,使用Future對象的.get(),如果此時沒有結果返回的話,會一直阻塞到有結果返回為止。
Oneway模式:客戶端調用完繼續執行,不管接收端是否成功。
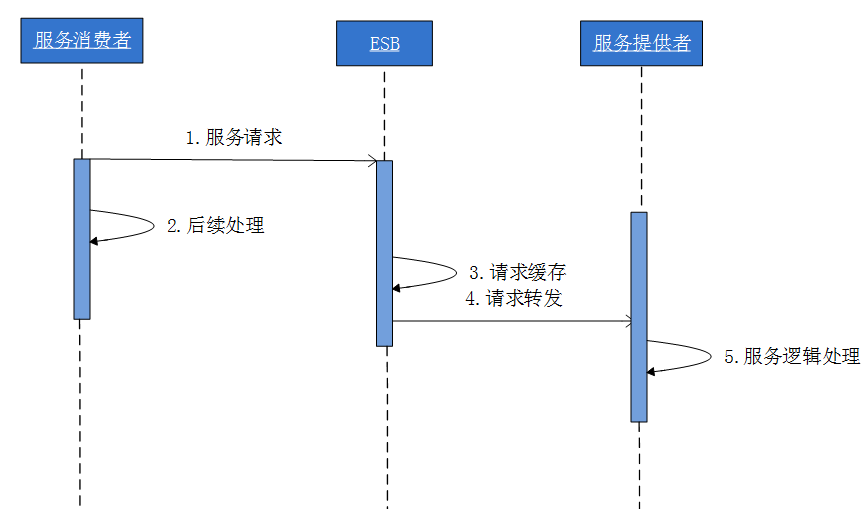
Reliable模式:為保證通信可靠,將借助於消息中心來實現消息的可靠送達,請求將做持久化存儲,在接收方在線時做送達,並由消息中心保證異常重試。
五種通信模式的實現方式-同步點對點服務模式
五種通信模式的實現方式-異步點對點消息模式1
五種通信模式的實現方式-異步點對點消息模式2
五種通信模式的實現方式-異步廣播消息模式
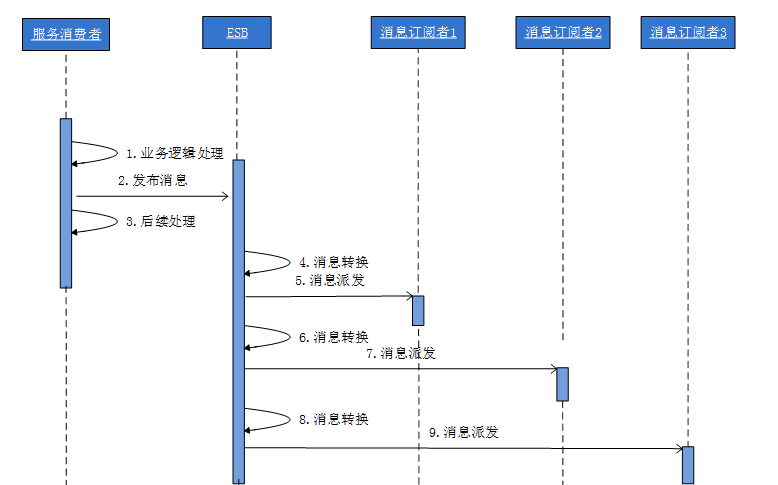
分布式架構下的服務治理
服務治理是服務框架/服務總線的核心功能。所謂服務治理,是指服務的提供方和消費方達成一致的約定,保證服務的高質量。服務治理功能可以解決將某些特定流量引入某一批機器,以及限制某些非法消費者的惡意訪問,並在提供者處理量達到一定程度是,拒絕接受新的訪問。
基於服務框架Dubbo的服務治理-服務管理
道你的系統,對外提供了多少服務,可以對服務進行升級、降級、停用、權重調整等操作
可以知道你提供的服務,誰在使用,因業務需求,可以對該消費者實施屏蔽、停用等操作
基於服務框架Dubbo的服務治理-服務監控
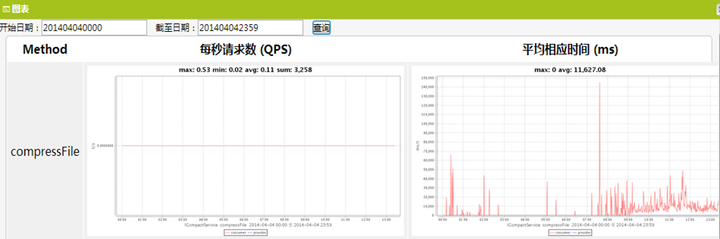
可以統計服務的每秒請求數、平均響應時間、調用量、峰值時間等,作為服務集群規劃、性能調優的參考指標。
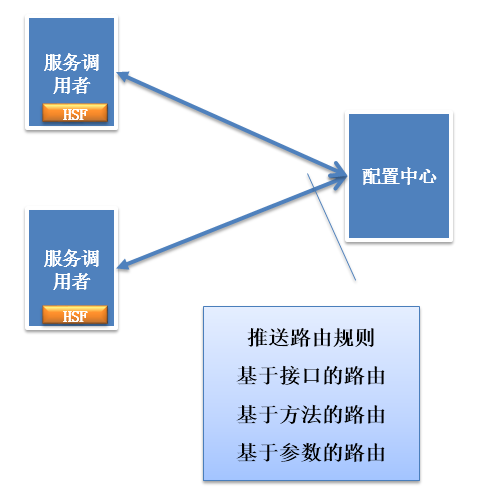
基於服務框架Dubbo的服務治理-服務路由
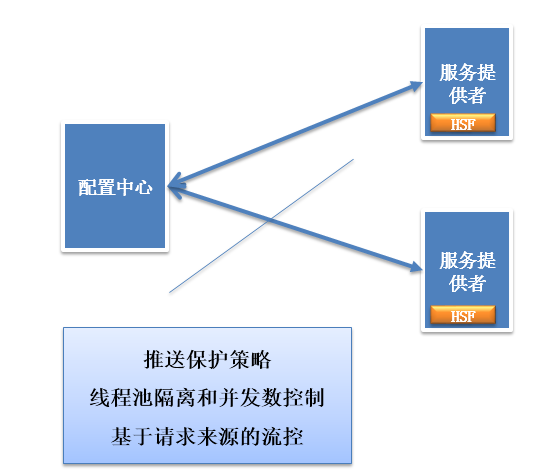
基於服務框架Dubbo的服務治理-服務保護
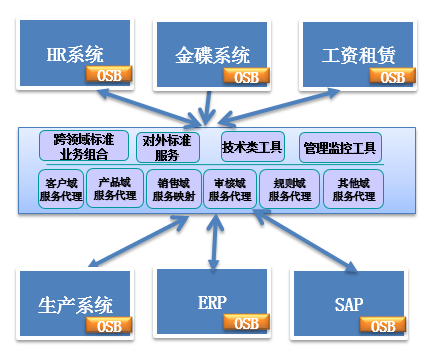
基於服務總線OSB的服務治理-功能介紹
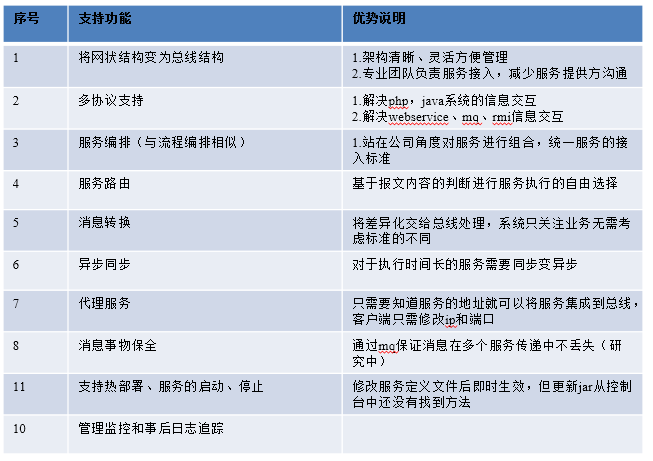
基於服務總線OSB的服務治理
Q:Dubbo到底是神馬?
A:
淘寶開源的高性能和透明化的RPC遠程調用服務框架
SOA服務治理方案
Q:Dubbo原理是?
A:
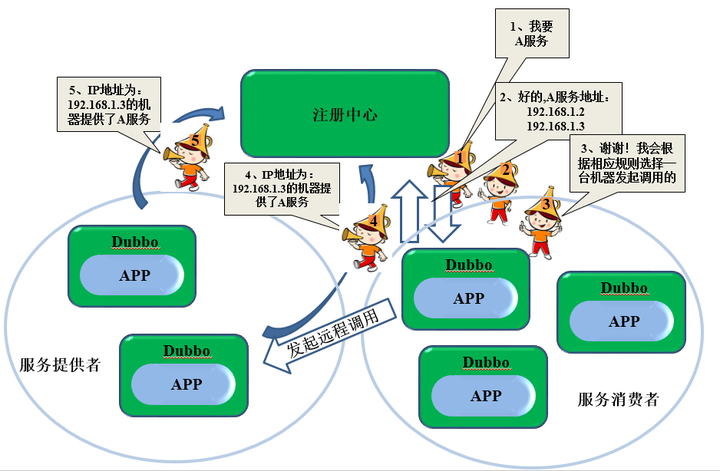
-結束-
分布式架構的演進,分析的很詳細,很到位