
python爬蟲筆記
1.抓取網頁並保存到txt中.解決控制臺亂碼問題
#_*_coding:utf-8_*_
import urllib2
response = urllib2.urlopen(‘http://hws.m.taobao.com/cache/wdetail/5.0/?id=540698103032‘)
cont = response.read()
file1 = open("./1.txt","w")
file1.write(cont)
file1.close()
print cont.decode("utf-8").encode("gbk")
2.操作json
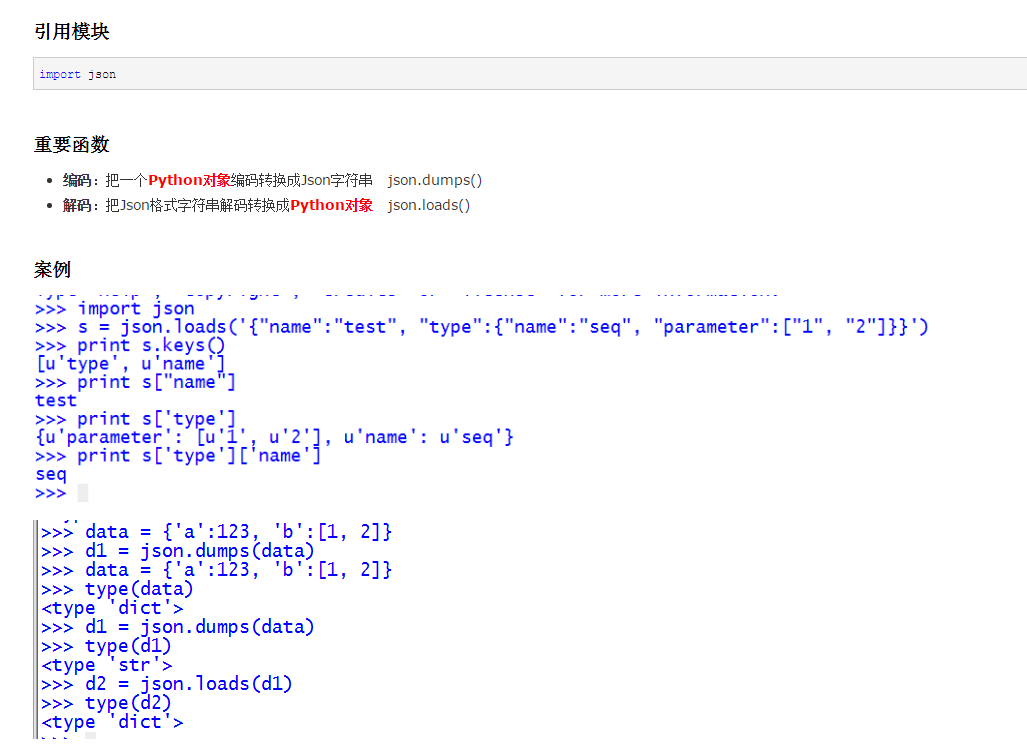
3.循環數組
https://www.cnblogs.com/Owen-ET/p/6932272.html
4.操作mssql
https://www.cnblogs.com/qianlifeng/archive/2012/02/06/2340367.html
https://www.cnblogs.com/lrzy/p/4346781.html
python爬蟲筆記
相關推薦
python爬蟲筆記
控制 解決 數組 arc code 循環數組 close brush 技術分享 1.抓取網頁並保存到txt中.解決控制臺亂碼問題 #_*_coding:utf-8_*_ import urllib2 response = urllib2.urlopen(‘http
python爬蟲筆記----4.Selenium庫(自動化庫)
locate pri 官方文檔 input 顯式 ref 打開網頁 elements timeout 4.Selenium庫 (自動化測試工具,支持多種瀏覽器,爬蟲主要解決js渲染的問題) pip install selenium 基本使用 from seleniu
PYTHON 爬蟲筆記十:利用selenium+PyQuery實現淘寶美食數據搜集並保存至MongeDB(實戰項目三)
pre pager 淘寶 NPU group color 存在 pan rgs 利用selenium+PyQuery實現淘寶美食數據搜集並保存至MongeDB 目標站點分析 流程框架 爬蟲實戰 spider詳情頁 import pymongo im
python | 爬蟲筆記(五)- 數據存儲
height iter use jordan rip 輕量 數據存儲 回滾 nosql 5.1 文件存儲 先用request把源碼獲取,再用解析庫解析,保存到文本 1- txt 文本打開方式: file = open(‘explore.txt‘, ‘a‘, encodin
python | 爬蟲筆記 - (八)Scrapy入門教程
RoCE yield ini 配置 自己 數據存儲 2.3 rom 提取數據 一、簡介 Scrapy是一個基於Twisted 的異步處理框架,是針對爬蟲過程中的網站數據爬取、結構性數據提取而編寫的應用框架。 可以應用在包括數據挖掘,信息處理或存儲歷史數據等一系列的程序中。
python爬蟲筆記-持續更新
爬蟲主要分為兩個部分,第一個是網頁介面的獲取,第二個是網頁介面的解析;爬蟲的原理是利用程式碼模擬瀏覽器訪問網站,與瀏覽器不同的是,爬蟲獲取到的是網頁的原始碼,沒有了瀏覽器的翻譯效果。 這裡我們使用urllib2進行網站頁面的獲取;首先匯入urllib2模組包 import url
python爬蟲筆記-day3
正則使用的注意點re.findall("a(.*?)b","str"),能夠返回括號中的內容,括號前後的內容起到定位和過濾的效果原始字串r,待匹配字串中有反斜槓的時候,使用r能夠忽視反斜槓帶來的轉義的效果點號預設情況匹配不到\n\s能夠匹配空白字元,不僅僅包含空格,還有\t|\r\n xpath學習重點使用
python爬蟲筆記-day1
判斷請求否是成功 assert response.status_code==200 url編碼 https://×××w.baidu.com/s?wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2 字串格式化的另一種方式 "傳{}智播客".format(1) 使用代理
python爬蟲筆記-day4
驗證碼的識別url不變,驗證碼不變請求驗證碼的地址,獲得相應,識別 url不變,驗證碼會變思路:對方伺服器返回驗證碼的時候,會和每個使用者的資訊和驗證碼進行一個對應,之後,在使用者傳送post請求的時候,會對比post請求中法的驗證碼和當前使用者真正的儲存在伺服器端的驗證碼是否相同1.例項化session2
Python爬蟲筆記(一)——基礎知識簡單整理
登陸時候的使用者名稱和密碼可以放在http的頭部也可以放在http的body部分。 HTTPS是否可以抓取 由於https運用的加密策略是公開的,所以即使網站使用https加密仍然可以獲得資料,但是類似於微信這樣的app,它自己實現了一套加密演算法,想要抓取資料就變得
python爬蟲筆記(七):實戰(三)股票資料定向爬蟲
目標分析及描述#CrawBaiduStocksA.py import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try:
Python 爬蟲筆記(對維基百科頁面的深度爬取)
*#! /usr/bin/env python #coding=utf-8 import urllib2 from bs4 import BeautifulSoup import re import datetime import random ran
【python爬蟲筆記】網路爬蟲之實戰
Unit7 re庫入門 操作符 說明 例項 . 表示任何單個字元 [ ] 字符集,對單個字元給出取值範圍 [abc]表
【python爬蟲筆記】網路爬蟲之提取
unit 4 BeautifulSoup庫入門 BeautifulSoup庫是解析、遍歷、維護“標籤樹”的功能庫 … 標籤 tag … name(成對出現) attributes(0或多個) beautifulSoup對應一個html/xml文件的全
【python爬蟲筆記】網路爬蟲之規則
WEEK1 Unit 1 Requests庫入門 Requests庫的get()方法 Requests庫的7個主要方法 reqest() 構造一個請求,支撐一下各方法的基礎方法 get() 獲取html網頁的主要方法,對應於http的get head
Python爬蟲筆記(一)
目錄 Python爬蟲筆記 一、爬蟲簡介 1、爬蟲是什麼? 2、爬蟲的技術價值 二、簡單的爬蟲架構 1、簡單爬蟲架構 2、簡單爬蟲的執行流程 三、爬蟲架構分析 1、URL管理器 2、網頁下載器 3、網頁解析器 Python爬蟲筆記 一、爬蟲簡介
python爬蟲筆記(六)——應對反爬策略
以下總結的全是單機爬取的應對反爬策略 1、設定爬取速度,由於爬蟲傳送請求的速度比較快,會對伺服器造成一定的影響,儘可能控制爬取速度,做到文明爬取 2、重啟路由器。並不是指物理上的插拔路由器,而是指模擬路由器重啟時傳送的表單。登陸自己的路由器,一般路由器會提供重啟路由器
python爬蟲學習之路-遇錯筆記-1
sig packages ror caused 技術 bsp img exception mage 當在編寫爬蟲時同時開啟了Fidder解析工具時,訪問目標站點會遇到以下錯誤: File "C:\Users\litao\AppData\Local\Programs\P
python網絡爬蟲筆記(四)
inf 比較 小寫字母 網絡爬蟲 作用 自定義 gpo 外部 而且 一、python中的高階函數算法 1、sorted()函數的排序 sorted()函數是一個高階函數,還可以接受一個key函數來實現自定義的函數排序,key指定的函數作用於每個序列元素上,並根據key函
python網絡爬蟲筆記(九)
out 模塊 ade npe tex visible 代碼 端口號 pac 4.1.1 urllib2 和urllib是兩個不一樣的模塊 urllib2最簡單的就是使用urllie2.urlopen函數使用如下 urllib2.urlopen(url[,