
關於從kafka采集數據到flume,然後落盤到hdfs上生成的一堆小文件的總結
采集數據到kafka,然後再通過flume將數據保存到hdfs上面。在這個過程當中出現了一堆的問題。
(1)一直是提醒說必須指定topic,然後發現我kafka用的是0.9.0.1,然而我的flume用的是1.6.然後將flume的版本調為1.7之後問題解決了。
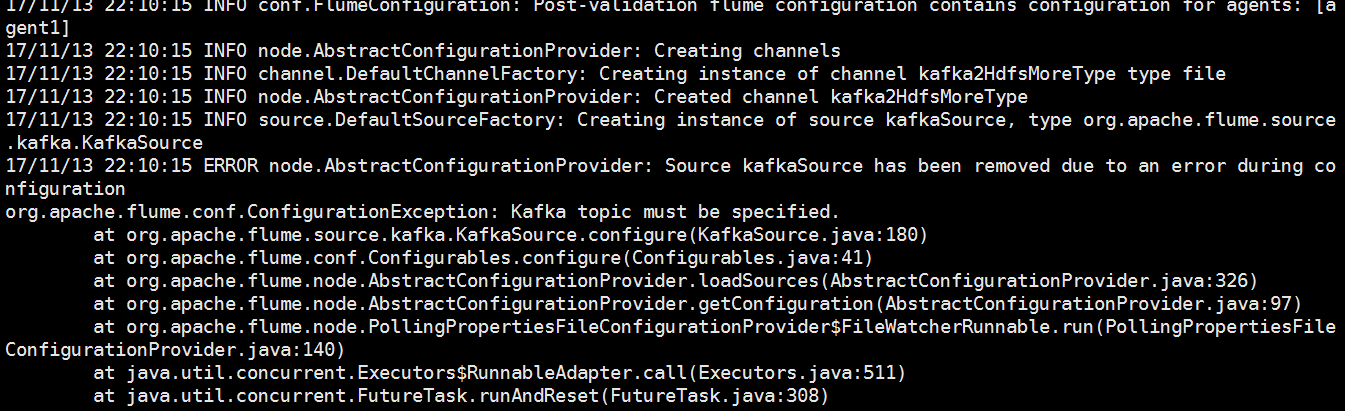
(2)flume能夠正常啟動。然而這個時候采集的文件是一堆小文件。
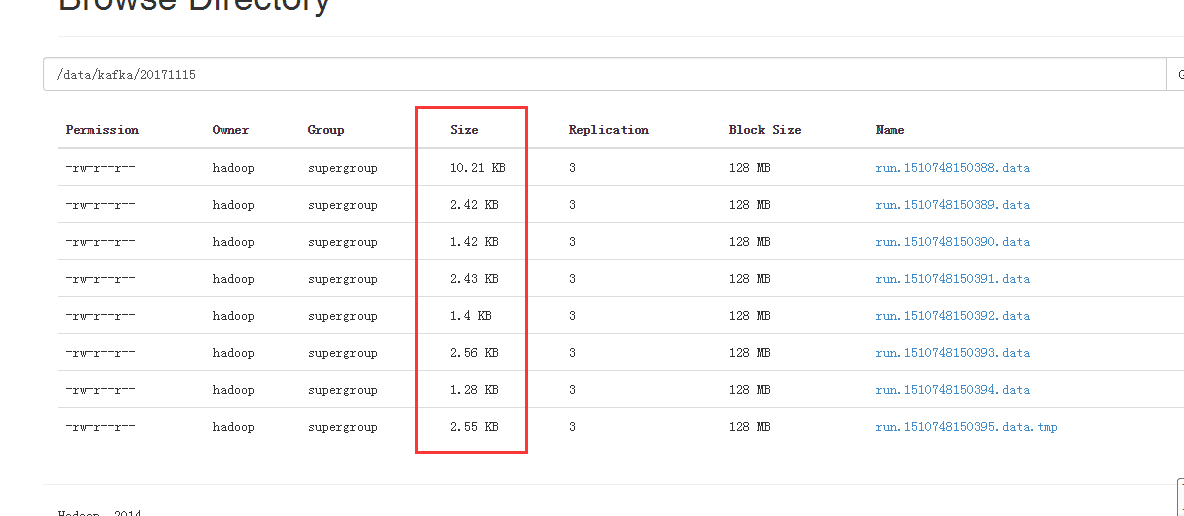
然後查看配置文件,修改配置文件。
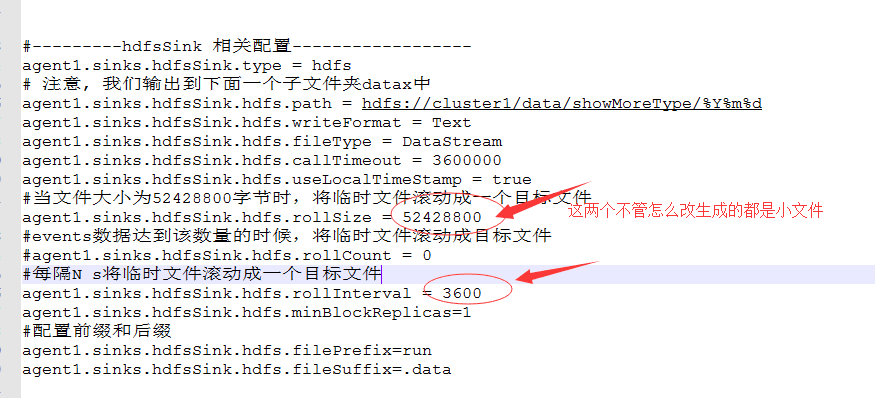
依然是生成了一堆小文件。最終的解決方法是:
將Hadoop配置文件裏面的相關文件加入到flume的conf目錄下。使這個配置文件能夠生效。識別這個當中的相關的配置文件。

關於從kafka采集數據到flume,然後落盤到hdfs上生成的一堆小文件的總結
相關推薦
關於從kafka采集數據到flume,然後落盤到hdfs上生成的一堆小文件的總結
src com 保存 pic width 配置 png hdfs alt 采集數據到kafka,然後再通過flume將數據保存到hdfs上面。在這個過程當中出現了一堆的問題。 (1)一直是提醒說必須指定topic,然後發現我kafka用的是0.9.0.1,然而我的flume
實驗:模擬場景中誤刪除mysql數據庫表,然後使用全備份以及二進制日誌文件恢復操作
skip images 目錄 mysqldump 系統 cde tables ransac 環境 一、實驗環境: 1、準備兩臺虛擬機,一臺用於破壞數據庫,一臺用於還原,兩臺在同一個網絡 2、兩臺最小化安裝centos 7系統,並直接yum安裝maraidb數據庫 3、準備一
編寫一個shall腳本,采用case語句,自動解壓“.tar.gz”或“.tar.bz2”格式文件
名稱 ech .tar.gz 軟件包 all export 解壓 case語句 cas #!/bin/bash#thisexport LC_ALL=C read -p "請輸入軟件包名稱:" PAG case $PAG in *[z] )
flume采集數據報錯問題解決
lin mem puts output sta 必須 dex 采集 數據報 在一次實驗過程中,使用flume 1.7采集本地的數據到hdfs文件系統時,由於配置文件不合理,導致出錯。錯誤如下: [WARN - org.apache.hadoop.hdfs.D
xpath學習(二),通過xpath 采集數據
編碼方式 img 模塊 界面 工具 技術分享 bubuko 這一 獲取 通過上一篇文章我們已經知道如何通過xpah精準定位到網頁中的某個元素了。今天再來看看昨天在網頁中獲取的數據該怎麽辦? 一、打開模板測試工具 二、雙擊run.bat 在執行這一步時我們必須安裝Jav
前嗅教程:同一個網站中從另一頁面采集數據
dac 鼠標 images 腳本 person c2c 通過 5.1 問題 第一步:新建任務①點擊左上角“加號”新建任務,如圖1:【圖1】②在彈窗裏填寫采集地址,任務名稱,如圖2:【圖2】③點擊下一步,選擇進行數據抽取還是鏈接抽取,本次采集企業最新動態鏈接列表,所以點擊抽取
Flume從Kafka讀取資料,並寫入到Hdfs上
需求:kafka有五個主題 topic topic-app-startuptopic topic-app-errortopic topic-app-eventtopic topic-app-usagetopic topic-app-pageflume讀取Kafka 5個主題
《ServerSuperIO Designer IDE使用教程》- 7.增加機器學習算法,通訊采集數據與算法相結合。發布:4.2.5 版本
智能 play 路線 cnblogs 集成系統 互聯網平臺 active per git v4.2.5更新內容:1.修復服務實例設置ClearSocketSession參數時,可能出現資源無法釋放而造成異常的情況。2.修復關閉宿主程序後進程仍然無法退出的問題。2.增加機
C#網頁采集數據的幾種方式(WebClient、WebBrowser和HttpWebRequest/HttpWebResponse)
var complete sys bre nth ews 寫入 保存 new 獲取網頁數據有很多種方式。在這裏主要講述通過WebClient、WebBrowser和HttpWebRequest/HttpWebResponse三種方式獲取網頁內容。 這裏獲取的是包括網頁
自動數據庫抽取想要的查詢結果,自動生成txt(utf-8)文件,然後自動ftp上傳到外網服務器
txt(utf-8)需求:無人值守的把數據庫中的數據,生成txt文本,自動上傳到ftp服務器,與外部客戶進行數據對接;===============================================步驟:1 寫存儲過程 2 數據庫中建立計劃任務 3 寫轉換txt編碼格式的插件
從本科生到數據科學家,為啥這個職業門檻高?
bit vpd 金融 軟件 window 企業級 成長 優惠碼 福利 參與文末話題討論,每日贈送異步圖書——異步小編William Chen是Quora的一位數據科學家,在那裏他協助Quora發展壯大,為這個世界分享知識。在拿到哈佛大學的統計和應用數學雙學位之後,他直接成
shell定時采集數據到HDFS
grep -v div rontab 路徑 tin linux jre_home day port 上線的網站每天都會產生日誌數據。假如有這樣的需求:要求在淩晨 24 點開始操作前一天產生的日誌文件,準實時上傳至 HDFS 集群上。 該如何實現?實現後能否實現周期性上
22.天眼查cookie模擬登陸采集數據
cat from undefined 地址 answer Language ase 圖片 count 通過賬號登錄獲取cookies,模擬登錄(前提有天眼查賬號),會員賬號可查看5000家,普通只是100家,同時也要設置一定的反爬措施以防賬號被封。拿有權限的賬號去獲取co
Win32從資源中載入PNG圖片,然後建立GDI+的Image物件
void LoadPNGFromStaticRes(HMODULE hModule, UINT nResId, Image** ppImg) { HRSRC hRes = FindResource(hModule, MAKEINTRESOURCE(nResId), TEXT("PNG"))
IP MODEM遠程測控工業自動化PLC采集數據備份
部署 終端 指令 內部存儲 制式 ado image 短信貓 圖片 方案需求 PLC = Programmable Logic Controller,可編程邏輯控制器,一種數字運算操作的電子系統,專為在工業環境應用而設計的。它采用一類可編程的存儲器,用於其內部存儲程序,執行
perl應用:DNA序列翻譯(下):從fasta格式中讀取序列,然後輸出蛋白質序列,以及fasta格式的介紹
use strict; use warnings; my $dna =''; my $protein =''; my @file_data=( ); my @filedata; @filedata = get_fi
GoldData將采集數據融合到兩張關聯關系表
開始 http 提交 pub ont net 得到 ble start 概述 在上一期中,我們抓取了新聞數據,現在我們要通過GoldData融合到兩張數據庫表news_site和news表當中去。如下圖所示: 我們很容易看到這兩張表存在關聯,那是怎樣將數據寫入關聯呢,
西數WD3200BEVT二次開盤數據恢復,筆記本硬盤嚴重進油數據恢復
筆記本 數據恢復 今天給大家帶來的這個案例相當經典,客戶聲稱硬盤盤腔進油了,在天貓上找了家數據恢復旗艦店也沒搞定,拿到手時硬盤已經被開過盤,小心打開如下圖:可以看到盤腔內部進油相當嚴重,0號面主面上面的油甚至都能滴下來,而上面的1號面肯定是進油後硬盤還通過電,上面留下不少的同心圓痕跡。反復清洗盤片正反
Java封裝JDBC數據庫增、刪、改、查操作成JAR文件,以供Web工程調用,適用於多種數據庫
通過 ive trac end 使用方法 數據 div bstr 工程 廢話不多說,直接上源代碼,最後有使用方法,當然,也可以作為普通公用類使用,只是封裝成JAR更方便使用。 [java] view plain copy package db.util;
Windows10環境下安裝Anaconda和tensorflow-gpu,然後在jupyter notebook上使用
一、進行Anaconda的下載和安裝 在官方網站下載Anaconda的Windows版本,下載的網址是https://www.anaconda.com/download/,根據自己電腦的位數下載對應的客戶端,推薦下載Python 3.7 version *版本。