
ANN in spark MLLib
神經網絡模型
每個node包含兩種操作:線性變換(仿射變換)和激發函數(activation function)。
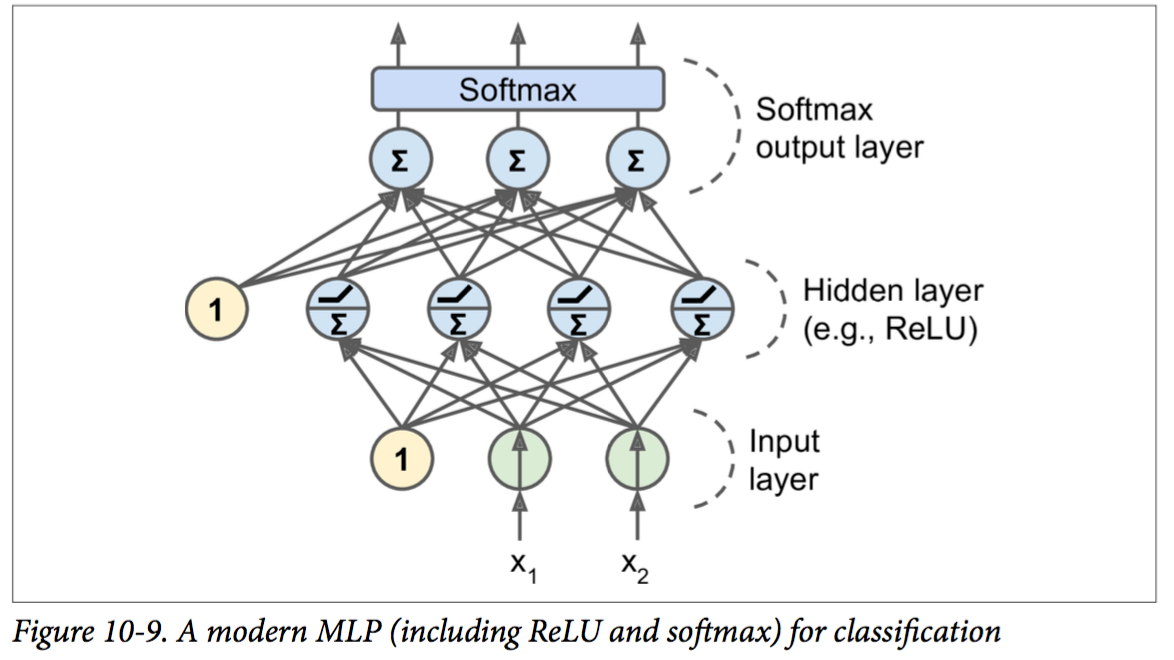
其中仿射變換是通用的,而激發函數可以很多種,如下圖。

MLLib中實現ANN
使用兩層(Layer)來對應模型中的一層:
- AffineLayer 仿射變換: output = W · input + b
- 如果是最後一層,使用
SoftmaxLayerWithCrossEntropyLoss或者SigmoidLayerWithSquaredError;如果是中間層,則使用functionalLayer(new SigmoidFunction()). 目前MLlib只支持sigmoid函數,實際上ReLU激發函數更普遍
BP算法計算Gradient的四個步驟:

對照BP算法的步驟,可以發現分隔成Affine和Activation的好處。BP1和BP2中的計算,不同的activation函數有不同的計算形式,將affine變換和activation函數解耦方便組合,進而方便形成各種類型的神經網絡。
MLLib FeedForward Trainer
訓練器重要模塊如下:
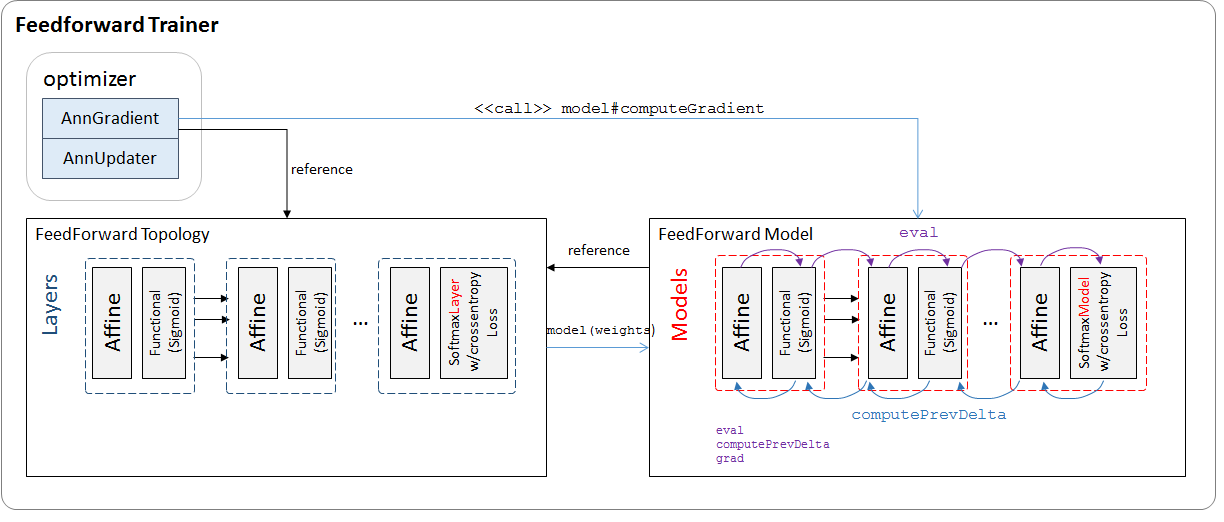
ANN模型中每層對應AffineLayer + FunctionalLayerModel OR SofrmaxLayerModelWIthCrossEntropyLoss
每個LayerModel實現三個函數:eval, computePrevDelta
grad, 作為輸出層的SoftmaxLayerModel有些特殊,額外具有LossFunction特性。可驗證affine+activation LayerModel的計算組合跟BP1-4一致。
AffineLayerModel (仿射變換層)
eval
\(\text{output} = W \cdot \text{input} + b\)computePrevDelta
\(prev\delta = W * \delta\)grad
$\dot{W} = input \cdot \delta^l / \text{data size} $
input is \(a^{l-1}\),前一層的激發函數輸出
\(\dot{b} = \delta^l / \text{data size}\)
FunctionalLayerModel(activate function \(\sigma\))
作為affineModel的activation model,只影響prev\(\delta\) 的計算,grad不計算
eval
\(\text{output} = \sigma (\text{input})\)computePrevDelta
\(\delta :=\delta * \sigma'(\text{input})\)grad
pass
SoftmaxLayerModelWithCrossEntropyLoss
作為最後一層激發函數,這一層很特殊。
eval
計算參見手寫公式。computePrevDelta
不計算grad
不計算loss
計算\(\delta^L\),公式推導參見手寫公式,代碼如下:
ApplyInPlace(output, target, delta, (o: Double, t: Double) => o - t)返回loss
Softmax輸出層的激發函數:
\(a^L_j = \frac{e^{z^L_j}}{\sum_k e^{z^L_k}}\)
計算BP1:\(\delta^L_j = a^L_j -y_j\)
訓練mnist手寫數字識別
import org.apache.spark.ml.classification.MultilayerPerceptronClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object ann extends App {
val spark = SparkSession
.builder
.appName("ANN for MNIST")
.master("local[3]")
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
import spark.implicits._
// Load the data stored in text as a DataFrame.
val dataRdd: DataFrame= spark.sparkContext.textFile("handson-ml/data/train.csv")
.map {
line =>
val linesp = line.split(",")
val linespDouble = linesp.map(f => f.toDouble)
(linespDouble.head, Vectors.dense(linespDouble.takeRight(linespDouble.length - 1)))
}.toDF("label","features")
val data = dataRdd
// Split the data into train and test
val splits: Array[DataFrame] = data.randomSplit(Array(0.6, 0.4), seed = 1234L)
val train: Dataset[Row] = splits(0)
val test: Dataset[Row] = splits(1)
val layers = Array[Int](28*28, 300, 100, 10)
// create the trainer and set its parameters
val trainer = new MultilayerPerceptronClassifier()
.setLayers(layers)
.setBlockSize(128)
.setSeed(1234L)
.setMaxIter(100)
.setLabelCol("label")
.setFeaturesCol("features")
// train the model
val model = trainer.fit(train)
// compute accuracy on the test set
val result = model.transform(test)
val predictionAndLabels = result.select("prediction", "label")
val evaluator = new MulticlassClassificationEvaluator()
.setMetricName("accuracy")
println("Test set accuracy = " + evaluator.evaluate(predictionAndLabels))
}後記
測試集結果精度為96.68%。實際上並不高,同樣的數據集使用TensorFlow訓練,activation function選擇ReLU,同樣使用Softmax作為輸出,結果可以達到98%以上。Sigmoid函數容易帶來vanishing gradients問題,導致學習曲線變平。
ANN in spark MLLib