
python爬蟲基本原理及入門
阿新 • • 發佈:2017-11-22
http safari pre col 分享圖片 ade 如果 渲染 登陸百度
爬蟲:請求目標網站並獲得數據的程序
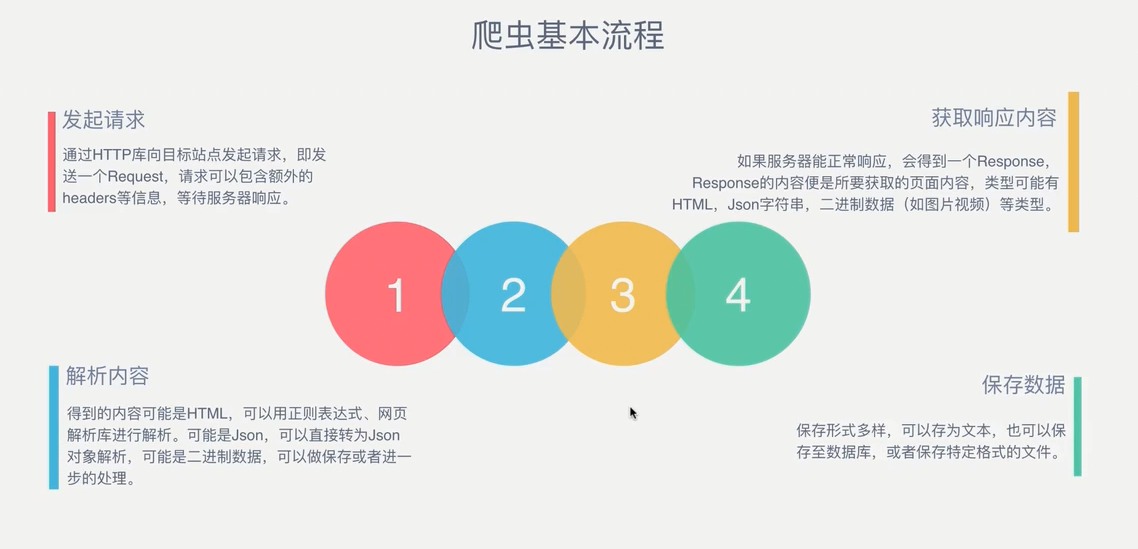
爬蟲的基本步驟:
使用python自帶的urllib庫請求百度:
import urllib.request
response = urllib.request.urlopen(‘http://www.baidu.com‘)
print(type(response))
#打印結果
<class ‘http.client.HTTPResponse‘>
可以從類型上看出來,response是一個HTTP響應
請求:

請求的方式以GET和POST最為常用,一般的GET方法將請求參數放在URL中。如在百度中搜索一個關鍵詞,這就形成了以GET在URL中更改參數的方法。
而POST將參數放在表單內進行請求。如請求登陸百度,需要向百度服務器發送你的賬號密碼這些東西。
請求頭是一個很重要的請求內容,在一般的瀏覽器請求中,網站會返回一個你的瀏覽器信息,如果在代碼不偽裝程瀏覽器的情況下,你的IP地址會迅速的被網站封掉,每個爬蟲庫的偽裝方式都是不同的,如urllib庫
import urllib.request heads = {} heads[‘User-Agent‘] = ‘Mozilla/5.0 ‘ ‘(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50‘ ‘(KHTML, like Gecko) Version/5.1 Safari/534.50‘ req = urllib.request.Request(url=url, data=data, method=‘POST‘, headers=heads) response = urllib.request.urlopen(req)
print(response.getheaders()) #getheaders()方法將會返回給你一些請求信息,如時間,服務器信息等,包含user-agent
響應:

響應就是請求之後瀏覽器所呈現的東西,最重要的就是響應體,包含了網頁的源文件
在代碼的情況下查看響應狀態:
import urllib.request
response = urllib.requset.urlopen(‘http://www.baidu.com‘)
print(response.getcode())
#返回200表示成功
解析方式:
當想要獲得網頁中某些元素應該怎樣去解析?

解析的方式多種多樣,目前還只是使用正則來做解析,聽說xpath是最簡單解析方式,不過我覺得每個庫還是要使用一下試試的,看看哪個更適合你。
為什麽有的網頁請求源碼和在瀏覽器中查看到的不一樣?
這是因為動態網站使用了JS渲染,元素都是經過js動態加載出來的,所以想要獲得源碼還要去模擬瀏覽器的行為,像selenium驅動browser,PhantomJS等工具。
python爬蟲基本原理及入門