
mysql實現高可用架構之MHA
一、簡介
MHA(Master HA)是一款開源的 MySQL 的高可用程序,它為 MySQL 主從復制架構提供了 automating master failover 功能。MHA 在監控到 master 節點故障時,會提升其中擁有最新數據的 slave 節點成為新的master 節點,在此期間,MHA 會通過於其它從節點獲取額外信息來避免一致性方面的問題。MHA 還提供了 master 節點的在線切換功能,即按需切換 master/slave 節點。
MHA 是由日本人 yoshinorim(原就職於DeNA現就職於FaceBook)開發的比較成熟的 MySQL 高可用方案。MHA 能夠在30秒內實現故障切換,並能在故障切換中,最大可能的保證數據一致性。目前淘寶也正在開發相似產品 TMHA, 目前已支持一主一從。
二、MHA 服務
2.1 服務角色
MHA 服務有兩種角色, MHA Manager(管理節點)和 MHA Node(數據節點):
MHA Manager:
通常單獨部署在一臺獨立機器上管理多個 master/slave 集群(組),每個 master/slave 集群稱作一個 application,用來管理統籌整個集群。
MHA node:
運行在每臺 MySQL 服務器上(master/slave/manager),它通過監控具備解析和清理 logs 功能的腳本來加快故障轉移。
主要是接收管理節點所發出指令的代理,代理需要運行在每一個 mysql 節點上。簡單講 node 就是用來收集從節點服務器上所生成的 bin-log 。對比打算提升為新的主節點之上的從節點的是否擁有並完成操作,如果沒有發給新主節點在本地應用後提升為主節點。
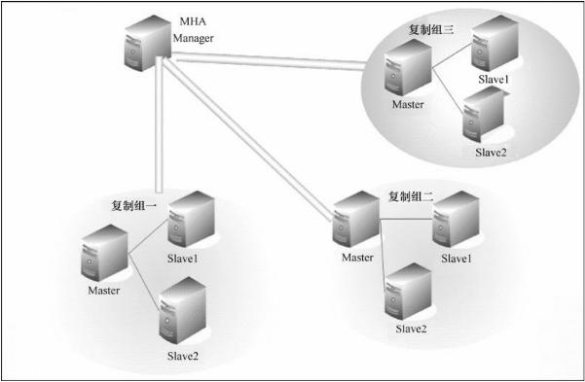
由上圖我們可以看出,每個復制組內部和 Manager 之間都需要ssh實現無密碼互連,只有這樣,在 Master 出故障時, Manager 才能順利的連接進去,實現主從切換功能。
2.2提供的工具
MHA會提供諸多工具程序, 其常見的如下所示:
Manager節點:
masterha_check_ssh:MHA 依賴的 ssh 環境監測工具;
masterha_check_repl:MYSQL 復制環境檢測工具;
masterga_manager:MHA 服務主程序;
masterha_check_status:MHA 運行狀態探測工具;
masterha_master_monitor
masterha_master_swith:master:節點切換工具;masterha_conf_host:添加或刪除配置的節點;masterha_stop:關閉 MHA 服務的工具。Node節點:(這些工具通常由MHA Manager的腳本觸發,無需人為操作)
save_binary_logs:保存和復制 master 的二進制日誌;apply_diff_relay_logs:識別差異的中繼日誌事件並應用於其他 slave;purge_relay_logs:清除中繼日誌(不會阻塞 SQL 線程);自定義擴展:
secondary_check_script:通過多條網絡路由檢測master的可用性;master_ip_failover_script:更新application使用的masterip;report_script:發送報告;init_conf_load_script:加載初始配置參數;master_ip_online_change_script;更新master節點ip地址。
2.3工作原理
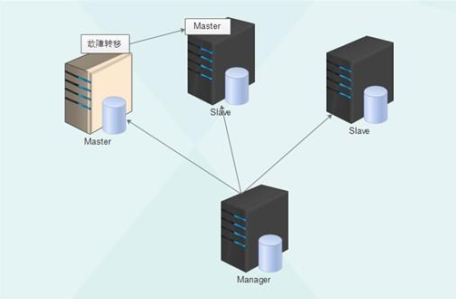
MHA工作原理總結為以下幾條:
(1) 從宕機崩潰的 master 保存二進制日誌事件(binlog events);
(2) 識別含有最新更新的 slave ;
(3) 應用差異的中繼日誌(relay log) 到其他 slave ;
(4) 應用從 master 保存的二進制日誌事件(binlog events);
(5) 提升一個 slave 為新 master ;
(6) 使用其他的 slave 連接新的 master 進行復制。
三、實現過程
3.1 準備實驗 Mysql 的 Replication 環境
3.1.1 相關配置
MHA 對 MYSQL 復制環境有特殊要求,例如各節點都要開啟二進制日誌及中繼日誌,各從節點必須顯示啟用其read-only屬性,並關閉relay_log_purge功能等,這裏對配置做事先說明。
本實驗環境共有四個節點, 其角色分配如下(實驗機器均為centos 7.3):

為了方便我們後期的操作,我們在各節點的/etc/hosts文件配置內容中添加如下內容:
192.168.37.111 node1.keer.com node1
192.168.37.122 node2.keer.com node2
192.168.37.133 node3.keer.com node3
192.168.37.144 node4.keer.com node4
這樣的話,我們就可以通過 host 解析節點來打通私鑰訪問,會方便很多。
本步驟完成。
3.1.2 初始主節點 master 的配置
我們需要修改 master 的數據庫配置文件來對其進行初始化配置:
[root@master ~]# vim /etc/my.cnf
[mysqld]
server-id = 1 //復制集群中的各節點的id均必須唯一
log-bin = master-log //開啟二進制日誌
relay-log = relay-log //開啟中繼日誌
skip_name_resolve //關閉名稱解析(非必須)
[root@master ~]# systemctl restart mariadb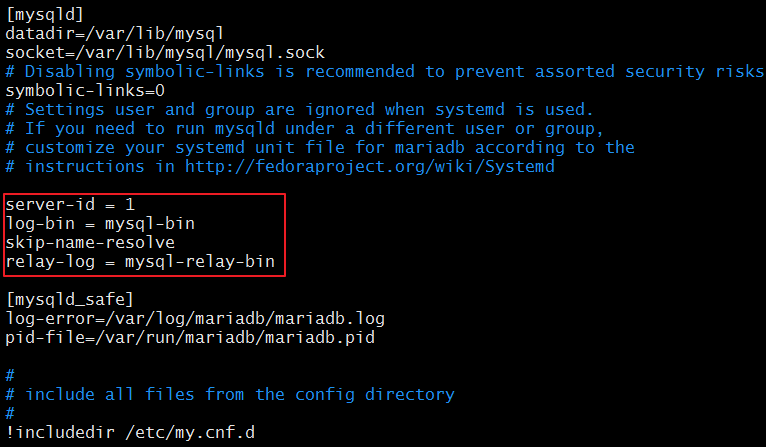
本步驟完成。
3.1.3 所有 slave 節點依賴的配置
我們修改兩個 slave 的數據庫配置文件,兩臺機器都做如下操作:
[root@slave1 ~]# vim /etc/my.cnf
[mysqld]
server-id = 2 //復制集群中的各節點的id均必須唯一;
relay-log = relay-log //開啟中繼日誌
log-bin = master-log //開啟二進制日誌
read_only = ON //啟用只讀屬性
relay_log_purge = 0 //是否自動清空不再需要中繼日誌
skip_name_resolve //關閉名稱解析(非必須)
log_slave_updates = 1 //使得更新的數據寫進二進制日誌中
[root@slave1 ~]# systemctl restart mariadb[root@slave2 ~]# vim /etc/my.cnf
[mysqld]
server-id = 3 //復制集群中的各節點的id均必須唯一;
relay-log = relay-log //開啟中繼日誌
log-bin = master-log //開啟二進制日誌
read_only = ON //啟用只讀屬性
relay_log_purge = 0 //是否自動清空不再需要中繼日誌
skip_name_resolve //關閉名稱解析(非必須)
log_slave_updates = 1 //使得更新的數據寫進二進制日誌中
[root@slave2 ~]# systemctl restart mariadb 本步驟完成。
3.1.4 配置一主多從復制架構
下面只會給出命令,具體的知識及過程詳解見我的上一篇博客——實戰項目——mysql主從架構的實現。
master 節點上:
MariaDB [(none)]>grant replication slave,replication client on *.* to 'slave'@'192.168.%.%' identified by 'keer';
MariaDB [(none)]> show master status;slave 節點上:
MariaDB [(none)]> change master to master_host='192.168.37.122',
-> master_user='slave',
-> master_password='keer',
-> master_log_file='mysql-bin.000001',
-> master_log_pos=415;
MariaDB [(none)]> start slave;
MariaDB [(none)]> show slave status\G; 本步驟完成。
3.2 安裝配置MHA
3.2.1 在 master 上進行授權
在所有 Mysql 節點授權擁有管理權限的用戶可在本地網絡中有其他節點上遠程訪問。 當然, 此時僅需要且只能在 master 節點運行類似如下 SQL 語句即可。
MariaDB [(none)]> grant all on *.* to 'mhaadmin'@'192.168.%.%' identified by 'mhapass'; 本步驟完成。
3.2.2 準備 ssh 互通環境
MHA集群中的各節點彼此之間均需要基於ssh互信通信,以實現遠程控制及數據管理功能。簡單起見,可在Manager節點生成密鑰對兒,並設置其可遠程連接本地主機後, 將私鑰文件及authorized_keys文件復制給余下的所有節點即可。
下面操作在所有節點上操作:
[root@manager ~]# ssh-keygen -t rsa
[root@manager ~]# ssh-copy-id -i .ssh/id_rsa.pub root@node1
當四臺機器都進行了上述操作以後,我們可以在 manager 機器上看到如下文件:
[root@manager ~]# cd .ssh/
[root@manager .ssh]# ls
authorized_keys id_rsa id_rsa.pub known_hosts
[root@manager .ssh]# cat authorized_keys 
四臺機器的公鑰都已經在authorized_keys這個文件中了,接著,我們只需要把這個文件發送至另外三臺機器,這四臺機器就可以實現 ssh 無密碼互通了:
[root@manager .ssh]# scp authorized_keys root@node2:~/.ssh/
[root@manager .ssh]# scp authorized_keys root@node3:~/.ssh/
[root@manager .ssh]# scp authorized_keys root@node4:~/.ssh/ 當然,我們也可以在機器上實驗一下,看看 ssh 是否還需要輸入密碼。
本步驟完成。
3.2.3 安裝 MHA 包
在本步驟中, Manager節點需要另外多安裝一個包。具體需要安裝的內容如下:
四個節點都需安裝:
mha4mysql-node-0.56-0.el6.norch.rpm
Manager 節點另需要安裝:mha4mysql-manager-0.56-0.el6.noarch.rpm
需要安裝的包我已經上傳至百度雲盤,密碼:mkcr,大家需要的自行下載使用~
我們使用rz命令分別上傳,然後使用yum安裝即可。
[root@manager ~]# rz
[root@manager ~]# ls
anaconda-ks.cfg initial-setup-ks.cfg Pictures
Desktop mha4mysql-manager-0.56-0.el6.noarch.rpm Public
Documents mha4mysql-node-0.56-0.el6.noarch.rpm Templates
Downloads Music Videos
[root@manager ~]# yum install -y mha4mysql-node-0.56-0.el6.noarch.rpm
[root@manager ~]# yum install -y mha4mysql-manager-0.56-0.el6.noarch.rpm 其余機器也分別進行安裝,就不一一舉例了。
本步驟完成。
3.2.4 初始化 MHA ,進行配置
Manager 節點需要為每個監控的 master/slave 集群提供一個專用的配置文件,而所有的 master/slave 集群也可共享全局配置。全局配置文件默認為/etc/masterha_default.cnf,其為可選配置。如果僅監控一組 master/slave 集群,也可直接通過 application 的配置來提供各服務器的默認配置信息。而每個 application 的配置文件路徑為自定義。具體操作見下一步驟。
3.2.5 定義 MHA 管理配置文件
為MHA專門創建一個管理用戶, 方便以後使用, 在mysql的主節點上, 三個節點自動同步:
mkdir /etc/mha_master
vim /etc/mha_master/mha.cnf配置文件內容如下;
[server default] //適用於server1,2,3個server的配置
user=mhaadmin //mha管理用戶
password=mhapass //mha管理密碼
manager_workdir=/etc/mha_master/app1 //mha_master自己的工作路徑
manager_log=/etc/mha_master/manager.log // mha_master自己的日誌文件
remote_workdir=/mydata/mha_master/app1 //每個遠程主機的工作目錄在何處
ssh_user=root // 基於ssh的密鑰認證
repl_user=slave //數據庫用戶名
repl_password=magedu //數據庫密碼
ping_interval=1 //ping間隔時長
[server1] //節點2
hostname=192.168.37.133 //節點2主機地址
ssh_port=22 //節點2的ssh端口
candidate_master=1 //將來可不可以成為master候選節點/主節點
[server2]
hostname=192.168.37.133
ssh_port=22
candidate_master=1
[server3]
hostname=192.168.37.144
ssh_port=22
candidate_master=1本步驟完成。
3.2.6 對四個節點進行檢測
1)檢測各節點間 ssh 互信通信配置是否 ok
我們在 Manager 機器上輸入下述命令來檢測:
[root@manager ~]# masterha_check_ssh -conf=/etc/mha_master/mha.cnf 如果最後一行顯示為[info]All SSH connection tests passed successfully.則表示成功。

2)檢查管理的MySQL復制集群的連接配置參數是否OK
[root@manager ~]# masterha_check_repl -conf=/etc/mha_master/mha.cnf
我們發現檢測失敗,這可能是因為從節點上沒有賬號,因為這個架構,任何一個從節點, 將有可能成為主節點, 所以也需要創建賬號。
因此,我們需要在master節點上再次執行以下操作:
MariaDB [(none)]> grant replication slave,replication client on *.* to 'slave'@'192.168.%.%' identified by 'keer';
MariaDB [(none)]> flush privileges;執行完這段操作之後,我們再次運行檢測命令:
[root@manager ~]# masterha_check_repl -conf=/etc/mha_master/mha.cnf
Thu Nov 23 09:07:08 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Thu Nov 23 09:07:08 2017 - [info] Reading application default configuration from /etc/mha_master/mha.cnf..
Thu Nov 23 09:07:08 2017 - [info] Reading server configuration from /etc/mha_master/mha.cnf..
……
MySQL Replication Health is OK. 可以看出,我們的檢測已經ok了。
此步驟完成。
3.3 啟動 MHA
我們在 manager 節點上執行以下命令來啟動 MHA:
[root@manager ~]# nohup masterha_manager -conf=/etc/mha_master/mha.cnf &> /etc/mha_master/manager.log &
[1] 7598啟動成功以後,我們來查看一下 master 節點的狀態:
[root@manager ~]# masterha_check_status -conf=/etc/mha_master/mha.cnf
mha (pid:7598) is running(0:PING_OK), master:192.168.37.122 上面的信息中“mha (pid:7598) is running(0:PING_OK)”表示MHA服務運行OK,否則, 則會顯示為類似“mha is stopped(1:NOT_RUNNING).”
如果,我們想要停止 MHA ,則需要使用 stop 命令:
[root@manager ~]# masterha_stop -conf=/etc/mha_master/mha.cnf3.4 測試 MHA 故障轉移
3.4.1 在 master 節點關閉 mariadb 服務,模擬主節點數據崩潰
[root@master ~]# killall -9 mysqld mysqld_safe
[root@master ~]# rm -rf /var/lib/mysql/*3.4.2 在 manger 節點查看日誌
我們來查看日誌:
[root@manager ~]# tail -200 /etc/mha_master/manager.log
……
Thu Nov 23 09:17:19 2017 - [info] Master failover to 192.168.37.133(192.168.37.133:3306) completed successfully. 表示 manager 檢測到192.168.37.122節點故障, 而後自動執行故障轉移, 將192.168.37.133提升為主節點。
註意,故障轉移完成後, manager將會自動停止, 此時使用 masterha_check_status 命令檢測將會遇到錯誤提示, 如下所示:
[root@manager ~]# masterha_check_status -conf=/etc/mha_master/mha.cnf
mha is stopped(2:NOT_RUNNING).3.5 提供新的從節點以修復復制集群
原有 master 節點故障後,需要重新準備好一個新的 MySQL 節點。基於來自於master 節點的備份恢復數據後,將其配置為新的 master 的從節點即可。註意,新加入的節點如果為新增節點,其 IP 地址要配置為原來 master 節點的 IP,否則,還需要修改 mha.cnf 中相應的 ip 地址。隨後再次啟動 manager ,並再次檢測其狀態。
我們就以剛剛關閉的那臺主作為新添加的機器,來進行數據庫的恢復:
原本的 slave1 已經成為了新的主機器,所以,我們對其進行完全備份,而後把備份的數據發送到我們新添加的機器上:
[root@slave1 ~]# mkdir /backup
[root@slave1 ~]# mysqldump --all-database > /backup/mysql-backup-`date +%F-%T`-all.sql
[root@slave1 ~]# scp /backup/mysql-backup-2017-11-23-09\:57\:09-all.sql root@node2:~然後在 node2 節點上進行數據恢復:
[root@master ~]# mysql < mysql-backup-2017-11-23-09\:57\:09-all.sql接下來就是配置主從。照例查看一下現在的主的二進制日誌和位置,然後就進行如下設置:
MariaDB [(none)]> change master to master_host='192.168.37.133', master_user='slave', master_password='keer', master_log_file='mysql-bin.000006', master_log_pos=925;
MariaDB [(none)]> start slave;
MariaDB [(none)]> show slave status\G;
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.37.133
Master_User: slave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000006
Read_Master_Log_Pos: 925
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 529
Relay_Master_Log_File: mysql-bin.000006
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
…… 可以看出,我們的主從已經配置好了。
本步驟完成。
3.6 新節點提供後再次執行檢查操作
我們來再次檢測狀態:
[root@manager ~]# masterha_check_repl -conf=/etc/mha_master/mha.cnf如果報錯,則再次授權(詳見上文)。若沒有問題,則啟動 manager,註意,這次啟動要記錄日誌:
[root@manager ~]# masterha_manager -conf=/etc/mha_master/mha.cnf > /etc/mha_master/manager.log 2>&1 &
[1] 10012啟動成功以後,我們來查看一下 master 節點的狀態:
[root@manager ~]# masterha_check_status -conf=/etc/mha_master/mha.cnf
mha (pid:9561) is running(0:PING_OK), master:192.168.37.133 我們的服務已經成功繼續了。
本步驟結束。
3.7新節點上線, 故障轉換恢復註意事項
1)在生產環境中, 當你的主節點掛了後, 一定要在從節點上做一個備份, 拿著備份文件把主節點手動提升為從節點, 並指明從哪一個日誌文件的位置開始復制
2)每一次自動完成轉換後, 每一次的(replication health )檢測不ok始終都是啟動不了必須手動修復主節點, 除非你改配置文件
3)手動修復主節點提升為從節點後, 再次運行檢測命令
[root@manager ~]# masterha_check_status -conf=/etc/mha_master/mha.cnf
mha (pid:9561) is running(0:PING_OK), master:192.168.37.1334)再次運行起來就恢復成功了
[root@manager ~]# masterha_manager --conf=/etc/mha_master/mha.cnf 以上。我們的實驗已經圓滿完成。
如有疑問或者建議大家可以多多討論吶~(~ ̄▽ ̄)~
mysql實現高可用架構之MHA