
05 爬取華為官網VMALL的手機評論
項目地址:copywang/spiders_collection
實現功能
- 爬取手機界面的所有手機評論列表
- 存儲到MONGODB
步驟
- 獲取首頁的手機列表,並獲取各個手機標題和詳情頁的URL
- 把第1步獲取的詳情頁URL分別打開,並獲取產品ID
- 根據產品ID結合URL,組合出評論頁的JSON請求並獲取JSON數據
- 首頁的JSON數據中包含最大的評論頁數
- 使用最大評論頁數作為循環,獲取得到所有頁的評論
遇到的問題
- 返回的JSON數據包含一些亂七八糟的開頭,不能使用json.loads()方法生成字典
- 有時候請求評論頁JSON會出現亂碼
- 暫時想不到多線程在哪裏使用合適
改進
- 使用json.loads()方法
- 使用多線

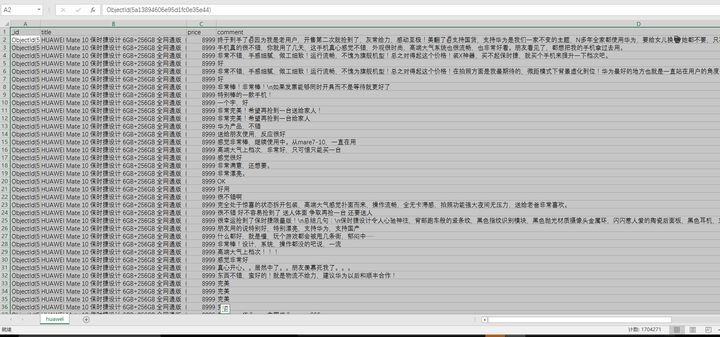
爬取後的數據:
05 爬取華為官網VMALL的手機評論
相關推薦
05 爬取華為官網VMALL的手機評論
wid gin lec image json數據包 線程 size 使用 ges 項目地址:copywang/spiders_collection 實現功能 爬取手機界面的所有手機評論列表 存儲到MONGODB 步驟 獲取首頁的手機列表,並獲取各個手機標題和詳情頁的U
Scrapy爬取京東商城華為全系列手機評論
本文轉自:https://mp.weixin.qq.com/s?__biz=MzA4MTk3ODI2OA==&mid=2650342004&idx=1&sn=4d270ab7ca54f6f2f7ec7aca113993f4&chksm=87811487b0f
網路爬蟲之scrapy爬取某招聘網手機APP釋出資訊
1 引言 2 APP抓包分析 3 編寫爬蟲昂 4 總結 1 引言 過段時間要開始找新工作了,爬取一些崗位資訊來分析一下吧。目前主流的招聘網站包括前程無憂、智聯、BOSS直聘、拉勾等等。有
Node.js爬蟲-爬取慕課網課程信息
reac 分享 function apt txt sta eject 賦值 find 第一次學習Node.js爬蟲,所以這時一個簡單的爬蟲,Node.js的好處就是可以並發的執行 這個爬蟲主要就是獲取慕課網的課程信息,並把獲得的信息存儲到一個文件中,其中要用到cheerio
Scrapy爬取慕課網(imooc)所有課程數據並存入MySQL數據庫
start table ise utf-8 action jpg yield star root 爬取目標:使用scrapy爬取所有課程數據,分別為 1.課程名 2.課程簡介 3.課程等級 4.學習人數 並存入MySQL數據庫 (目標網址 http://www.imoo
Python爬蟲之爬取煎蛋網妹子圖
創建目錄 req add 註意 not 相同 esp mpi python3 這篇文章通過簡單的Python爬蟲(未使用框架,僅供娛樂)獲取並下載煎蛋網妹子圖指定頁面或全部圖片,並將圖片下載到磁盤。 首先導入模塊:urllib.request、re、os import
Httpclient爬取優酷網
num 內容 htm clas ets author download auth isod 參考:http://www.cnblogs.com/lchzls/p/6277210.html /httpClient/src/main/java/com/louis/youku
我的第一個Scrapy 程序 - 爬取當當網信息
ref http ide ces passwd lds url ext != 前面已經安裝了Scrapy,下面來實現第一個測試程序。 概述 Scrapy是一個爬蟲框架,他的基本流程如下所示(下面截圖來自互聯網) 簡單的說,我們需要寫一個item文件,定義返回的數據結構;寫
4-15 爬取新浪網
xlsx size text num mos das rip bs4 page import requests 3 from bs4 import BeautifulSoup 4 from datetime import datetime 5 import re 6
爬取起點中文網小說介紹信息
OS tex 2.0 user agent lee idp url pri 字數的信息(word)沒有得到缺失 import xlwt import requests from lxml import etree import time all_info_list=[]
【Python3 爬蟲】14_爬取淘寶上的手機圖片
head 並且 淘寶網 pan coff urllib images 圖片列表 pic 現在我們想要使用爬蟲爬取淘寶上的手機圖片,那麽該如何爬取呢?該做些什麽準備工作呢? 首先,我們需要分析網頁,先看看網頁有哪些規律 打開淘寶網站http://www.taobao.com/
scrapy案例:爬取翼蜂網絡新聞列表和詳情頁面
model rap name lB htm nod meta http AR # -*- coding: utf-8 -*- import scrapy from Demo.items import DemoItem class AbcSpider(scrapy.Sp
用Python多線程實現生產者消費者模式爬取鬥圖網的表情圖片
Python什麽是生產者消費者模式 某些模塊負責生產數據,這些數據由其他模塊來負責處理(此處的模塊可能是:函數、線程、進程等)。產生數據的模塊稱為生產者,而處理數據的模塊稱為消費者。在生產者與消費者之間的緩沖區稱之為倉庫。生產者負責往倉庫運輸商品,而消費者負責從倉庫裏取出商品,這就構成了生產者消費者模式。 生
Scrapy爬蟲(5)爬取當當網圖書暢銷榜
The log sdn detail iss 就是 pan 微信公眾號 打開 ??本次將會使用Scrapy來爬取當當網的圖書暢銷榜,其網頁截圖如下: ??我們的爬蟲將會把每本書的排名,書名,作者,出版社,價格以及評論數爬取出來,並保存為csv格式的文件。項目的具體創建就不
ruby 爬蟲爬取拉鉤網職位信息,產生詞雲報告
content 數據持久化 lag works wid spa 代碼 職位 要求 思路:1.獲取拉勾網搜索到職位的頁數 2.調用接口獲取職位id 3.根據職位id訪問頁面,匹配出關鍵字 url訪問采用unirest,由於拉鉤反爬蟲,短時間內頻繁訪問會被
selelinum+PhantomJS 爬取拉鉤網職位
one while 對象 bili exe 5.0 設置 expect money 使用selenium+PhantomJS爬取拉鉤網職位信息,保存在csv文件至本地磁盤 拉鉤網的職位頁面,點擊下一頁,職位信息加載,但是瀏覽器的url的不變,說明數據不是發送get請求得到的
python3爬蟲爬取煎蛋網妹紙圖片
port 商業 技術分享 爬取 其中 lar c函數 base 技術 其實之前實現過這個功能,是使用selenium模擬瀏覽器頁面點擊來完成的,但是效率實際上相對來說較低。本次以解密參數來完成爬取的過程。 首先打開煎蛋網http://jandan.net/ooxx,查看網頁
Python網絡爬蟲Scrapy+MongoDB +Redis實戰爬取騰訊視頻動態評論教學視頻
並發數 www. 深入 圖例 編程 ppt 研發 read 網絡爬蟲 課程簡介 學習Python爬蟲開發數據采集程序啦!網絡編程,數據采集、提取、存儲,陷阱處理……一站式全精通!!!目標人群掌握Python編程語言基礎,有誌從事網絡爬蟲開發及數據采集程序開發的人群。學習目
第三篇 - 爬取豆瓣電影網
zip def str 一個 eva 電影 pycha 系統 瀏覽器 環境:python 3.6 pycharm 模塊:requests,json 1 import requests 2 import json 3 4 #請求頭 5 headers = {
爬蟲----爬取校花網視頻
done orm ref div submit false lex clas gbk import requests import re import time import hashlib def get_page(url): print(‘GE