
Java中utf-8格式字符串的存儲方法。
阿新 • • 發佈:2017-11-25
字節 turn byte[] spa 負數 oid 只有一個 ret 字符串截取
知識點:
可通過 byte[] bytes=“xxxx”.getBytes("utf-8")得到字符串通過utf-8解析到字節數組。utf-8編碼格式下,計算機采用1個字節存儲ASCII範圍內的字符,采用3個字節儲存中文字符。
UTF-8是一種變長字節編碼方式。對於某一個字符的UTF-8編碼,如果只有一個字節則其最高二進制位為0;如果是多字節,其第一個字節從最高位開始,連續的二進制位值為1的個數決定了其編碼的位數,其余各字節均以10開頭。UTF-8最多可用到6個字節。
如表:
1字節 0xxxxxxx
2字節 110xxxxx 10xxxxxx
3字節 1110xxxx 10xxxxxx 10xxxxxx
4字節 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字節 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字節 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
註意:計算中中utf-8編碼存儲多字節字符時,並未將8個二進制位的首位作為符號位,如直接輸出,得到的將是負數。
byte[] bss = "這是一個神奇的世界".getBytes("utf-8");
System.out.println("bss長度:"+bss.length);//輸出:27,一個中文用三個字節存儲。
//輸出:-24 -65 -103 -26 -104 -81 -28 -72 -128 -28 -72 -86 -25 -91 -98 -27 -91 -121 -25 -102 -124 -28 -72 -106 -25 -107 -116
for (byte b:bss) {
System.out.print(b+" ");
}
如要正確獲得每一個字節表示的實際編碼值。可通過如下方式。(需了解位移運算,原碼、反碼、補碼相關知識)
1.十進制
byte[] bss = "這是一個神奇的世界".getBytes("utf-8"); System.out.println("bss長度:"+bss.length);//輸出:27,一個中文用三個字節存儲。 //輸出:232 191 153 230 152 175 228 184 128 228 184 170 231 165 158 229 165 135 231 154 132 228 184 150 231 149 140 for (byte b:bss) { System.out.print(Integer.valueOf(b&0xff)+" "); }
2.十六進制
byte[] bss = "這是一個神奇的世界".getBytes("utf-8"); System.out.println("bss長度:"+bss.length);//輸出:27,一個中文用三個字節存儲。 //輸出:e8 bf 99 e6 98 af e4 b8 80 e4 b8 aa e7 a5 9e e5 a5 87 e7 9a 84 e4 b8 96 e7 95 8c for (byte b:bss) { System.out.print(Integer.toHexString(b&0xff)+" "); }
3.二進制
byte[] bss = "這是一個神奇的世界".getBytes("utf-8"); System.out.println("bss長度:"+bss.length);//輸出:27,一個中文用三個字節存儲。 //輸出:11101000 10111111 10011001 11100110 10011000 10101111 11100100 // 10111000 10000000 11100100 10111000 10101010 11100111 10100101 10011110 // 11100101 10100101 10000111 11100111 10011010 10000100 11100100 // 10111000 10010110 11100111 10010101 10001100 for (byte b:bss) { System.out.print(Integer.toBinaryString(b&0xff)+" "); }
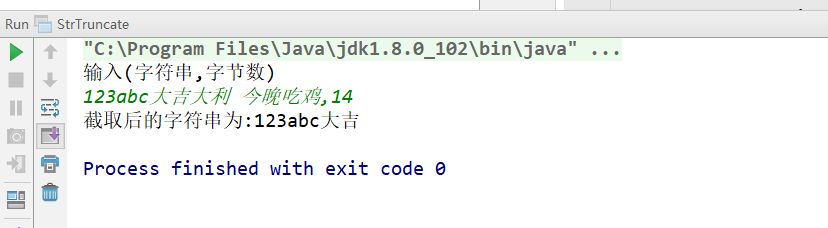
練習:中英文混合字符串截取
* 通過傳入字符串和字節素,根據字節數截取字串,utf-8下非英文字符占據多個字節,
* 如截取位置處於非英文字符的中間位置,應舍棄最後一個被截斷的字符。
public class StrTruncate { public static void main(String[] args) throws UnsupportedEncodingException { Scanner scanner = new Scanner(System.in); System.out.println("輸入(字符串,字節數)"); String inputStr = scanner.nextLine(); String sub = new StrTruncate().getSubStr(inputStr.split(",")[0] , Integer.valueOf(inputStr.split(",")[1])); System.out.println("截取後的字符串為:" + sub); } public String getSubStr(String resource, int charLen) throws UnsupportedEncodingException { if (charLen <= 0) { return null; } byte[] bytes = resource.getBytes("utf-8"); if (bytes[charLen] < 0) { while (!Integer.toBinaryString(bytes[charLen] & 0xff).startsWith("11")) { charLen--; } } String subStr = new String(bytes, 0, charLen, "utf-8"); return subStr; } }
執行結果如下:
Java中utf-8格式字符串的存儲方法。