
Python自然語言處理1
首先,進入cmd 輸入pip install的路徑 隨後開始下載nltk的包
一、準備工作
1、下載nltk
我的之前因為是已經下載好了 ,我現在用的參考書是Python自然語言處理這本書,最重要的包就是nltk,因此需要先下載這個包。
當然,你也可以按照書上的方法下載。

2、Jupyter notebook
這個了解Python的童鞋應該都很熟悉了,我用的也不是特別好,這裏就不再贅述了,總之如果你希望保存你的代碼,還是用這個更加好。當然如果你有更好的方法。
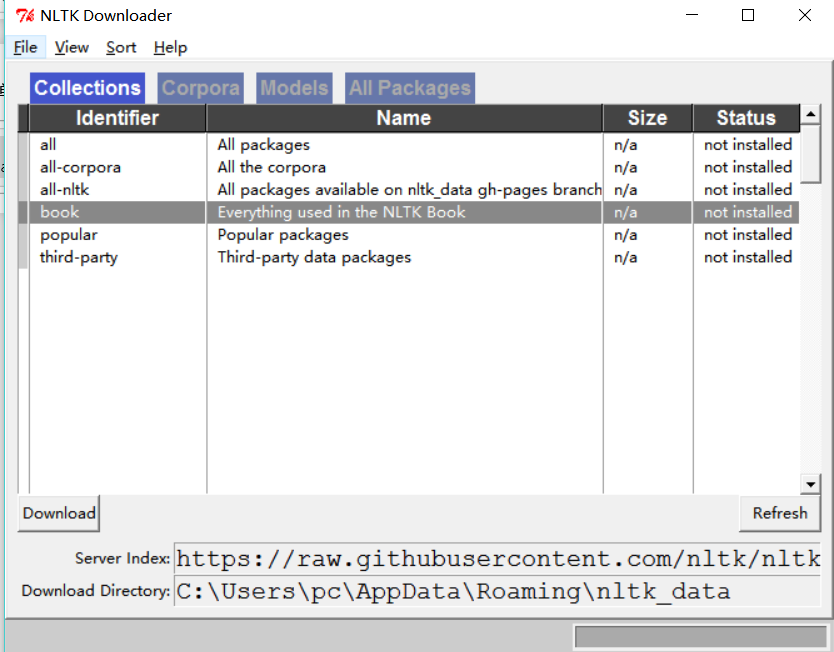
選擇 book 然後download 之後就可以下載所有的在書中所使用的數據集了
然後使用函數調用我們包中的數就可以了
Python自然語言處理1
相關推薦
Python自然語言處理1
cmd 輸入 函數調用 down load src 選擇 分享 cnblogs 首先,進入cmd 輸入pip install的路徑 隨後開始下載nltk的包 一、準備工作 1、下載nltk 我的之前因為是已經下載好了 ,我現在用的參考書是Python自然語言處理這本書,最
python自然語言處理——1.4 回到python:決策和控制
ott thead top linear 控制 san max-width eight 技術分享 微信公眾號:數據運營人本系列為博主的讀書學習筆記,如需轉載請註明出處。 第一章 語言處理與python 1.4 回到python:決策和控制條件對每個元素進行操作嵌套
python自然語言處理——1.2 近觀python:將文本當作詞鏈表
bsp family round orm 學習 splay letter mic lock 微信公眾號:數據運營人本系列為博主的讀書學習筆記,如需轉載請註明出處。 第一章 語言處理與python 1.2 近觀python:將文本當作詞鏈表鏈表索引列表變量字符串 1
python自然語言處理——1.5 自動理解自然語言
微信公眾號:資料運營人本系列為博主的讀書學習筆記,如需轉載請註明出處。 第一章 語言處理與python 1.5 自動理解自然語言詞意消歧指代消解自動生成語言機器翻譯人機對話系統文字的含義 1.5 自動理解自然語言 詞意消歧 大家都應該知道,無論是漢語,英語甚至其他語言,
Python自然語言處理 Chapter 1
col ont otl python import 搜索 text2 div load() from __future__ import division import nltk nltk.download() from nltk.book import * #搜索文本
python自然語言處理 -讀書筆記1
# -*- coding:utf-8 -*- # __author__ = 'lipzhang' import nltk from nltk.book import * # print(text1.concordance("monstrous"))#顯示一個指 定單詞的每一次出現,連同一些上下文
python 自然語言處理 統計語言建模(1/2)
一、計算單詞頻率 例子:生成1-gram,2-gram,4-gram的Alpino語料庫的分詞樣本 import nltk # 1 - gram from nltk.util import ngrams from nltk.corpus import alp
python自然語言處理——2.1 獲取文字語料庫
微信公眾號:資料運營人本系列為博主的讀書學習筆記,如需轉載請註明出處。 第二章 獲取文字預料和詞彙資源 2.1 獲取文字語料庫古騰堡語料庫網路和聊天文字布朗語料庫路透社語料庫就職演說語料庫標註文字語料庫其他文字語料庫文字語料庫結構 2.1 獲取文字語料庫 一個文字語料庫是一
【讀書筆記】《Python自然語言處理》第1章 語言處理與Python
1.1 語言計算:文字和詞彙 入門 nltk下載地址 使用pip安裝 >>>import nltk 檢驗是否成功。 >>>nltk.download() 選擇語料下載 使用python直譯器載入book模組中的條目 >&g
python自然語言處理(NLP)1------中文分詞1,基於規則的中文分詞方法
python中文分詞方法之基於規則的中文分詞 目錄 常見中文分詞方法 推薦中文分詞工具 參考連結 一、四種常見的中文分詞方法: 基於規則的中文分詞 基於統計的中文分詞 深度學習中文分詞 混合分詞方法 基於規則的中
Python自然語言處理實戰(1):NLP基礎
從建模的角度看,為了方便計算機處理,自然語言可以被定義為一組規則或符號的集合,我們組合集合中的符號來傳遞各種資訊。自然語言處理研究表示語言能力、語言應用的模型,通過建立計算機框架來實現這樣的語言模型,並且不斷完善這樣的語言模型,還需要根據語言模型來設計各種實用的系
python自然語言處理——3.1 從網絡和硬盤訪問文本
自然語言處理 num align otto aci soup tro nltk find 微信公眾號:數據運營人本系列為博主的讀書學習筆記,如需轉載請註明出處。 第三章 加工原料文本 3.1 從網絡和硬盤訪問文本電子書處理的HTML處理RSS訂閱讀取本地文件 3.
NLP-python 自然語言處理01
count ems odin 頻率分布 str sep mon location don 1 # -*- coding: utf-8 -*- 2 """ 3 Created on Wed Sep 6 22:21:09 2017 4 5 @author: A
Python自然語言處理筆記【二】文本分類之監督式分類的細節問題
重要 探索 基於 font 產生 com 分類器 保持 聯合 一、選擇正確的特征 1.建立分類器的工作中如何選擇相關特征,並且為其編碼來表示這些特征是首要問題。 2.特征提取,要避免過擬合或者欠擬合 過擬合,是提供的特征太多,使得算法高度依賴訓練數據的特性,而對於一般化的
Python | 自然語言處理 (一)
res sent 處理 簡單的 *** ima examples 表示 rds 小白博主最近想參加一個關於NLP的比賽,於是入坑自然語言處理,想借博客一邊學習,一邊整理 首先安裝庫nltk,直接pip install nltk即可 1 from nltk.book imp
《精通Python自然語言處理》高清中文版PDF+高清英文版PDF+源代碼
http 自然語言 下載 pdf color 語言 源代碼 書籍 https 下載:https://pan.baidu.com/s/1p9MgH2HDTGfUmWx8jHRsxw 《精通Python自然語言處理》高清中文版PDF+高清英文版PDF+源代碼 高清中文版PDF,
Python自然語言處理—統計詞頻
一 資料的預處理 本文所有的例子我都將使用中文文字進行,所以在分析前需要對中文的文字進行一個預處理的過程(暫時只用的分詞,去除停用詞的部分後面介紹) # -*- coding:utf-8 -*- from nltk import FreqDist import jieba import py
python自然語言處理-—安裝NLTK
安裝Anaconda後,進入Prompt介面 依次輸入 easy_install pip pip install pyyaml nltk 結果如下 下載nltk中的資料集 import nltk nltk.download() 選擇book文字集合下載相關資料集
精通Python自然語言處理 pdf 下載
自然語言處理(NLP)是有關計算語言學與人工智慧的研究領域之一。NLP主要關注人機互動,它提供了計算機和人類之間的無縫互動,使得計算機在機器學習的幫助下理解人類語言。 本書詳細介紹如何使用Python執行各種自然語言處理(NLP)任務,並幫助讀者掌握利用Python設計和構建基於NLP的應用的
python自然語言處理-讀書筆記5
#使用UniCode進行文書處理 #Unicode支援超過一百萬種字元。每個字元分配一個編號,稱為編碼點。在 Python中, 編碼點寫作\uXXXX 的形式,其中 XXXX是四位十六進位制形式數。 #從檔案中提取已編碼文字 import codecs path = nltk.data.fin