
mysql索引介紹
阿新 • • 發佈:2017-11-28
lob exp tab 系統 存取 io操作 內存 html 失效 0.索引的概念
索引是一種特殊的文件(InnoDB數據表上的索引是表空間的一個組成部分),它們包含著對數據表裏所有記錄的引用指針。好比是一本書前面的目錄,能加快數據庫的查詢速度。
無論是Myisam和Innodb引擎,如果在建表的時候沒有顯示的定義一行主鍵列的話,他內部都會自動創建一個隱藏的主鍵索引;
1.索引的優點:
a.大大減少服務器需要掃描的數據量
b.幫助服務器避免排序和臨時表
c.將隨機IO變為順序IO
2.“三星 ”系統:
索引將相關的記錄放在一起,獲得一星
索引中的數據順序和查找中的排列順序一直,再獲得一星
索引中的列涵蓋了查詢中需要的全部列,再獲得一星
3.按照實現方式來劃分的索引類型
哈希索引:基於哈希表實現,只有精確匹配索引所有列的查詢才有效,只有Memory引擎實現
空間數據索引(R-Tree ),只有MyISAM引擎實現
全文索引:分詞後查找關鍵詞,適用於match against操作
BTree索引:B-Tree索引的限制:如果不是按照索引的出現順序查找,則無法使用索引;不能跳過索引中的列,否則後面的索引無效;如果查詢中有某個列的範圍查詢,則其右邊所有列都無法使用索引優化查找;
B+Tree索引:適用於全鍵匹配、第一列匹配(組合索引)、列前綴匹配,範圍值匹配、精確匹配第一列並範圍匹配第二列、只訪問索引(也稱索引覆蓋)匹配;
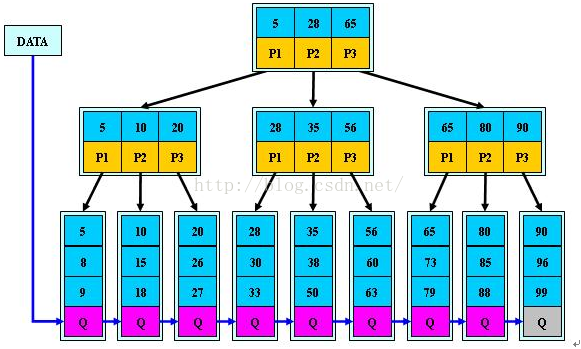
事實上,我們可以通過前面聚集索引和非聚集索引的定義的例子來理解上表。如:返回某範圍內的數據一項。比如您的某個表有一個時間列,恰好您把聚合索引建立在了該列,這時您查詢2004年1月1日至2004年10月1日之間的全部數據時,這個速度就將是很快的,因為您的這本字典正文是按日期進行排序的,聚類索引只需要找到要檢索的所有數據中的開頭和結尾數據即可;而不像非聚集索引,必須先查到目錄中查到每一項數據對應的頁碼,然後再根據頁碼查到具體內容。
b. 索引不會包含有NULL值的列
只要列中包含有NULL值都將不會被包含在索引中,復合索引中只要有一列含有NULL值,那麽這一列對於此復合索引就是無效的。所以我們在數據庫設計時不要讓字段的默認值為NULL。
c. 使用短索引
對字符串列進行索引,如果可能應該指定一個前綴長度。例如,如果有一個CHAR(255)的列,如果在前10個或20個字符內,多數值是惟一的,那麽就不要對整個列進行索引。短索引不僅可以提高查詢速度而且可以節省磁盤空間和I/O操作。mysql不允許索引這些列(BLOB、TEXT、很長的VARCHAR)的完整長度
d. 索引列排序
MySQL查詢只使用一個索引,因此如果where子句中已經使用了索引的話,那麽order by中的列是不會使用索引的。因此數據庫默認排序可以符合要求的情況下不要使用排序操作;盡量不要包含多個列的排序,如果需要最好給這些列創建復合索引。
只有當索引的列順序和order by子句的順序完全一致,並且所有列的排序方向一致時,mysql才能用索引來對結果做排序
e. like語句操作:一般情況下不鼓勵使用like操作,如果非使用不可,如何使用也是一個問題。like “%aaa%” 不會使用索引。而like “aaa%”可以使用索引。
f. 不要在列上進行運算:
例如:select * from users where YEAR(adddate)<2007,將在每個行上進行運算,這將導致索引失效而進行全表掃描,因此我們可以改成:select * from users where adddate<’2007-01-01′
g.多列索引:
如果對多個單獨索引做AND條件查詢時,應該將多個單獨索引合並為一個多列索引。
如果對多個單獨索引做OR條件查詢,會消耗大量CPU、內存在算法的緩存、排序和合並上。應該將多個單獨索引合並為一個多列索引。
使用explain檢查sql 語句,如果發現了索引合並問題,應該修改sql語句
選擇合適的索引列順序,選擇性高的列往前放
h.覆蓋索引:如果一個索引包含所有要查詢的字段值(三星系統中第三星),較少了磁盤IO操作,提高查詢性能
i.索引不能太多:索引越多會導致更新表的速度減慢,因為除了更新數據外,還要更新索引
j:MySQL只對以下操作符才使用索引 <,<=,=,>,>=,between,in,以及某些時候的like(不以通配符%或_開頭的情形)。而理論上每張表裏面最多可創建16個索引,不過除非是數據量真的很多,否則過多的使用索引也不是那麽好玩的
8.非聚簇索引和.聚簇索引
非聚集索引,類似於圖書的附錄,那個專業術語出現在哪個章節,這些專業術語是有順序的,但是出現的位置是沒有順序的。每個表只能有一個聚簇索引,因為一個表中的記錄只能以一種物理順序存放。但是,一個表可以有不止一個非聚簇索引。
MyISAM是非聚簇索引,B+Tree的葉子節點上的data,並不是數據本身,而是數據存放的地址。主索引和輔助索引沒啥區別,只是主索引中的key一定得是唯一的。這裏的索引都是非聚簇索引。非聚簇索引的兩棵B+樹看上去沒什麽不同,節點的結構完全一致只是存儲的內容不同而已,主鍵索引B+樹的節點存儲了主鍵,輔助鍵索引B+樹存儲了輔助鍵。表數據存儲在獨立的地方,
這兩顆B+樹的葉子節點都使用一個地址指向真正的表數據,對於表數據來說,這兩個鍵沒有任何差別。由於索引樹是獨立的,通過輔助鍵檢索無需訪問主鍵的索引樹。InnoDB的數據文件本身就是索引文件,B+Tree的葉子節點上的data就是數據本身,key為主鍵,這是聚簇索引。聚簇索引,葉子節點上的data是主鍵(所以聚簇索引的key,不能過長)。
聚簇索引的數據的物理存放順序與索引順序是一致的,即:只要索引是相鄰的,那麽對應的數據一定也是相鄰地存放在磁盤上的。聚簇索引要比非聚簇索引查詢效率高很多。
聚集索引這種主+輔索引的好處是,當發生數據行移動或者頁分裂時,輔助索引樹不需要更新,因為輔助索引樹存儲的是主索引的主鍵關鍵字,而不是數據具體的物理地址。

MyISAM和InnoDB上都是采用B+Tree索引,但是實現方式完全不同。具體可參考
MySQL的MyISAM與InnoDB的索引方式
https://www.cnblogs.com/zlcxbb/p/5757245.html 4.索引分為聚簇索引和非聚簇索引兩種 innodb采用聚簇索引:主鍵索引的葉子節點下面直接存放數據,其他次索引的葉子節點指向主鍵id;聚簇索引能提高多行檢索的速度。 myisam采用非聚簇索引 :主鍵索引的葉子節點只存放數據在物理磁盤上的指針,其他次索引也是一樣的;非聚簇索引對於單行的檢索很快 5.按照使用方式來劃分索引類型a.普通索引INDEX :這是最基本的索引,它沒有任何限制。
b.唯一索引UNIQUE:與普通索引類似,不同的就是:索引列的值必須唯一,但允許有空值。如果是組合索引,則列值的組合必須唯一
c.主鍵索引PRIMARY KEY:它 是一種特殊的唯一索引,不允許有空值。
d.全文索引FULLTEXT :僅可用於 MyISAM 表,針對較大的數據,生成全文索引很耗時耗空間。
e. 單列索引、多列索引:多個單列索引與單個多列索引的查詢效果不同,因為執行查詢時,MySQL只能使用一個索引,會從多個索引中選擇一個限制最為嚴格的索引。
f.組合索引:為了榨取MySQL的效率,就要考慮建立組合索引。例如表中針對title和time建立一個組合索引:ALTER TABLE article ADD INDEX index_titme_time (title(50),time(10))。建立這樣的組合索引,其實是相當於分別建立了下面兩組組合索引,為什麽沒有time這樣的組合索引呢?這是因為MySQL組合索引“最左前綴”的結果。簡單的理解就是只從最左面的開始組合。並不是只要包含這兩列的查詢都會用到該組合索引
| 動作描述 | 使用聚集索引 | 使用非聚集索引 |
| 列經常被分組排序 | 使用 | 使用 |
| 返回某範圍內的數據 | 使用 | 不使用 |
| 一個或極少不同值 | 不使用 | 不使用 |
| 小數目的不同值 | 使用 | 不使用 |
| 大數目的不同值 | 不使用 | 使用 |
| 頻繁更新的列 | 不使用 | 使用 |
| 外鍵列 | 使用 | 使用 |
| 主鍵列 | 使用 | 使用 |
| 頻繁修改索引列 | 不使用 | 使用 |
InnoDB是聚簇索引,將主鍵組織到一棵B+樹中,而行數據就儲存在葉子節點上,若使用"where id = 14"這樣的條件查找主鍵,則按照B+樹的檢索算法即可查找到對應的葉節點,之後獲得行數據。若對Name列進行條件搜索,則需要兩個步驟:第一步在輔助索引B+樹中檢索Name,到達其葉子節點獲取對應的主鍵。第二步使用主鍵在主索引B+樹種再執行一次B+樹檢索操作,最終到達葉子節點即可獲取整行數據。
9.mysql索引和頁的關系
索引往往以索引文件的形式存儲的磁盤上,索引的結構組織要盡量減少查找過程中磁盤I/O的存取次數。為了達到這個目的,磁盤按需讀取,要求每次都會預讀的長度一般為頁的整數倍。而且數據庫系統將一個節點的大小設為等於一個頁,這樣每個節點只需要一次I/O就可以完全載入。每次新建節點時,直接申請一個頁的空間,這樣就保證一個節點物理上也存儲在一個頁裏,加之計算機存儲分配都是按頁對齊的,就實現了一個node只需一次I/O。並把B-tree中的m值設的非常大,就會讓樹的高度降低,有利於一次完全載入。 內存管理內容可參考操作系統內存管理mysql索引介紹