
學習筆記(九)——數據庫存儲結構:頁、聚集索引、非聚集索引
1、頁
SQL Server用8KB 的頁來存儲數據,並且在SQL Server裏磁盤 I/O 操作在頁級執行。也就是說,SQL Server 讀取或寫入所有數據頁。頁有不同的類型,像數據頁,GAM,SGAM等。先理解下數據頁結構。
SQL Server把數據記錄存在數據頁(Data Page)裏。數據記錄是堆表裏、聚集索引裏葉子節點的行。
數據頁由3個部分組成。頁頭(標頭),數據區(數據行和可用空間)及行偏移數組。
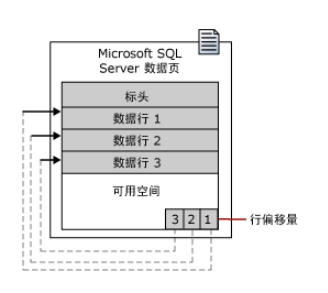
我們來執行下列的命令:
DBCC IND(‘InternalStorageFormat‘,‘Customers‘,-1)
結果如下

可以看到有
2、聚集索引與費聚集索引的對比
非聚集索引與聚集索引具有相同的樹結構,它們之間的顯著差別在於以下兩點:
基礎表的數據行不按非聚集鍵的順序排序和存儲。
非聚集索引的葉層是由索引頁而不是由數據頁組成。
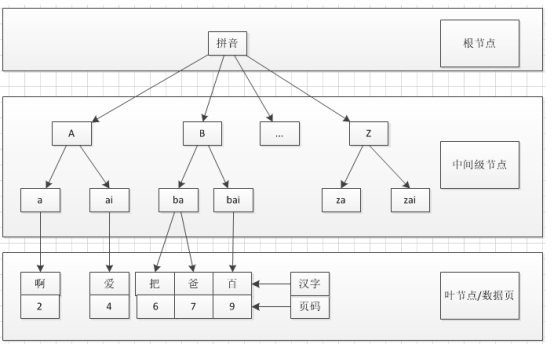
3、聚集索引:表中各行的物理順序與鍵值的邏輯(索引)順序相同,每個表只能有一個。
在聚集索引中,表中各行的物理順序與鍵值的邏輯(索引)順序相同。表只能包含一個聚集索引。例如:漢語字(詞)典默認按拼音排序編排字典中的每頁頁碼。拼音字母
4、非聚集索引:非聚集索引指定表的邏輯順序,數據存儲的一個位置,索引存儲在另一個位置,索引中包含指向數據的指針,可以有多個。如果不是聚集索引,表中各行的物理順序與鍵值的邏輯順序不匹配。聚集索引比非聚集索引(nonclustered index)有更快的數據訪問速度。例如,按筆畫排序的索引就是非聚集索引,“1”畫的字(詞)對應的頁碼可能比“3”畫的字(詞)對應的頁碼大(靠後)。
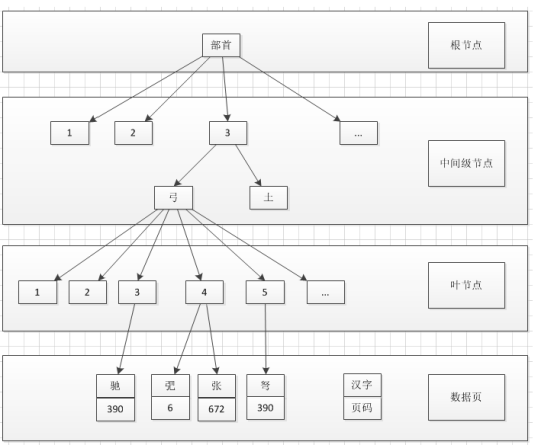
提示:SQL Server中,一個表只能創建1個聚集索引,多個非聚集索引。設置某列為主鍵,該列就默認為聚集索引。
5、創建聚集索引查詢
查詢表如下:
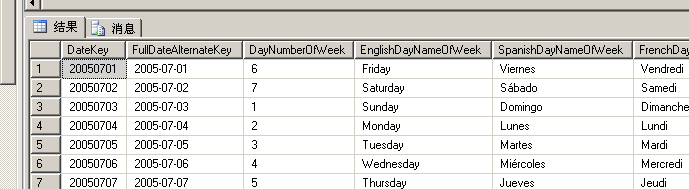
然後在DateKey列建立聚集索引:
CREATE CLUSTERED
INDEX Index_Key ON DimDate(DateKey)
執行結果如下

DROP INDEX Dimdate.Index_Key --刪除索引
CREATE CLUSTERED
INDEX Index_Key ON DimDate(DateKey) --再在重建列聚集索引
再執行查詢語句:
select top 3 * from Person

留意到同樣的語句,返回已經改變。可以聚集索引是表的順序,會影響到top語句。
6、創建非聚集索引
USE [pratice] GO CREATE TABLE Department8( DepartmentID int IDENTITY(1,1) NOT NULL , Name NVARCHAR(200) NOT NULL, GroupName NVARCHAR(200) NOT NULL, Company NVARCHAR(300), ModifiedDate datetime NOT NULL DEFAULT (getdate()) ) CREATE NONCLUSTERED INDEX NCL_Name_GroupName ON [dbo].[Department8](Name,[GroupName]) DECLARE @i INT SET @i=1 WHILE @i < 100 BEGIN INSERT INTO Department8 ( name, [Company], groupname ) VALUES ( ‘銷售部‘+CAST(@i AS VARCHAR(200)), ‘中國你好有限公司XX分公司‘, ‘銷售組‘+CAST(@i AS VARCHAR(200)) ) SET @i = @i + 1 END SELECT * FROM [dbo].[Department8] --TRUNCATE TABLE [dbo].[DBCCResult] INSERT INTO DBCCResult EXEC (‘DBCC IND(pratice,Department8,-1) ‘) SELECT * FROM [dbo].[DBCCResult] ORDER BY [PageType] DESC
學習筆記(九)——數據庫存儲結構:頁、聚集索引、非聚集索引