
MongoDB中聚合工具Aggregate等的介紹與使用
Aggregate是MongoDB提供的眾多工具中的比較重要的一個,類似於SQL語句中的GROUP BY。聚合工具可以讓開發人員直接使用MongoDB原生的命令操作數據庫中的數據,並且按照要求進行聚合。
MongoDB提供了三種執行聚合的方法:Aggregation Pipleline,map-reduce功能和 Single Purpose Aggregation Operations
其中用來做聚合操作的幾個函數是
-
aggregate(pipeline,options)指定 group 的 keys, 通過操作符$push/$addToSet/$sum等實現簡單的 reduce, 不支持函數/自定義變量 -
group({ key, reduce, initial [, keyf] [, cond] [, finalize] })支持函數(keyf)mapReduce的閹割版本 -
mapReduce -
count(query) -
distinct(field,query)
1、Aggregation Pipleline
MongoDB’s aggregation framework is modeled on the concept of data processing pipelines. Documents enter a multi-stage pipeline that transforms the documents into an aggregated result.
管道在*nix中將上一個命令輸出的數據作為下一個命令的參數。MongoDB中的管道聚合非常實用,提供高效的數據聚合,並且是MongoDB中數據聚合的首選方法
官方給的圖:
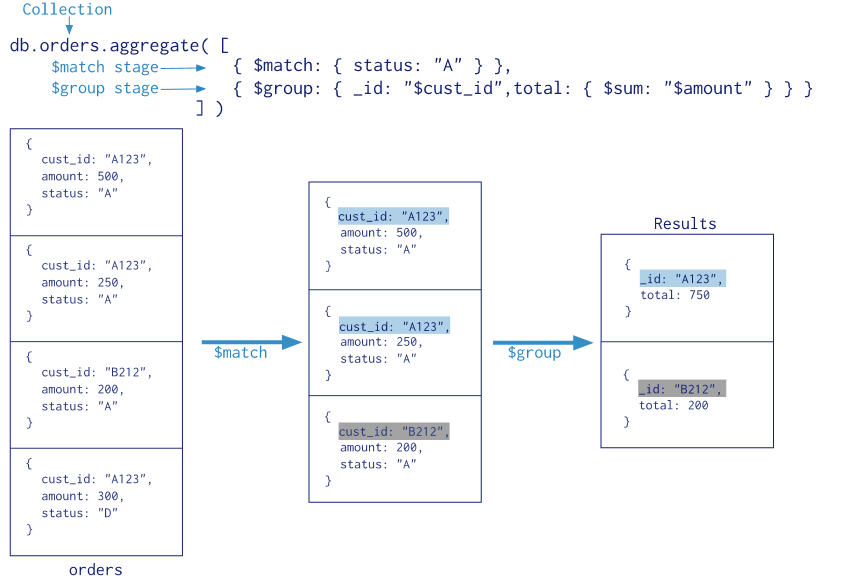
[
{$match: {status: "A"}},
{$group: {_id: "$cust_id", total: {$sum: "$amount"}}}
]
aggreagte是一個數組,其中包含多個對象(命令),通過遍歷Pipleline數組對collection中的數據進行操作。
$match:查詢條件
$group:聚合的配置
-
_id代表你想聚合的數據的主鍵,上述數據中,你想聚合所有cust_id相同的條目的amount的總和,那_id即被設置為cust_id。_id為必須,你可以填寫一個空值。 -
total代表你最後想輸出的數據之一,這裏total是每條結果中amount的總和。 -
$sum是一個聚合的操作符,另外的操作符你可以在官方文檔中找到。上圖中的命令表示對相同主鍵(_id)下的amount進行求和。如果你想要計算主鍵出現的次數,可以把命令寫成如下的形式{$sum: 1}
聚合的過程
看一下圖例,所有的數據先經過$match命令,只留下了status為A的數據,接著,對篩選出的數據進行聚合操作,對相同cust_id的數據進行計算amount總和的操作,最後輸出結果。
二、aggregate具體介紹
接受兩個參數 pipeline/options, pipeline 是 array, 相同的 operator 可以多次使用
pipeline 支持的方法
-
$geoNeargeoNear命令可以在查詢結果中返回每個點距離查詢點的距離 -
$group指定 group 的_id(key/keys) 和基於操作符($push/$sum/$addToSet/...) 的累加運算 -
$limit限制條件 -
$match輸入過濾條件 -
$out將輸出結果保存到collection -
$project修改數據流中的文檔結構 -
$redact是$project/$match功能的合並 -
$skip 跳過 -
$sort對結果排序 -
$unwind拆解數據
$group 允許用的累加操作符 $addToSet/$avg/$first/$last/$max/$min/$push/$sum,不被允許的累加操作符$each... ,默認最多可以用 100MB RAM, 增加allowDiskUse可以讓$group操作更多的數據
下面是aggregate的用法
db.newtest.aggregate([
{$match: {}},
{$skip: 10}, // 跳過 collection 的前 10 行
{$project: {group: 1, datetime: 1, category: 1, count: 1}},
// 如果不選擇 {count: 1} 最後的結果中 count_all/count_avg = 0
{$redact: { // redact 簡單用法 過濾 group != ‘A‘ 的行
$cond: [{$eq: ["$group", "A"]}, "$$DESCEND", "$$PRUNE"]
}},
{$group: {
_id: {year: {$year: "$datetime"}, month: {$month: "$datetime"}, day: {$dayOfMonth: "$datetime"}},
group_unique: {$addToSet: "$group"},
category_first: {$first: "$category"},
category_last: {$last: "$category"},
count_all: {$sum: "$count"},
count_avg: {$avg: "$count"},
rows: {$sum: 1}
}},
// 拆分 group_unique 如果開啟這個選項, 會導致 _id 重復而無法寫入 out 指定的 collection, 除非再 $group 一次
// {$unwind: "$group_unique"},
// 只保留這兩個字段
{$project: {group_unique: 1, rows: 1}},
// 結果按照 _id 排序
{$sort: {"_id": 1}},
// 只保留 50 條結果
// {$limit: 50},
// 結果另存
{$out: "data_agg_out"},
], {
explain: true,
allowDiskUse: true,
cursor: {batchSize: 0}
})
db.data_agg_out.find()
db.data_agg_out.aggregate([
{$group: {
_id: null,
rows: {$sum: ‘$rows‘}
}}
])
db.data_agg_out.drop()
-
$match聚合前數據篩選 -
$skip跳過聚合前數據集的 n 行, 如果{$skip: 10}, 最後rows = 5000000 - 10 -
$project之選擇需要的字段, 除了_id之外其他的字段的值只能為 1 -
$redact看了文檔不明其實際使用場景, 這裏只是簡單篩選聚合前的數據 -
$group指定各字段的累加方法 -
$unwind拆分 array 字段的值, 這樣會導致_id重復 -
$project可重復使用多次 最後用來過濾想要存儲的字段 -
$out如果$group/$project/$redact的_id沒有重復就不會報錯 -
以上方法中
$project/$redact/$group/$unwind可以使用多次
二、group
group 比 aggregate 好的一個地方是 map/reduce 都支持用 function 定義, 下面是支持的選項
ns如果用db.runCommand({group: {}})方式調用, 需要ns指定 collectioncond聚合前篩選key聚合的 keyinitial初始化 累加 結果$reduce接受(curr, result)參數, 將curr累加到resultkeyf代替key用函數生成聚合用的主鍵finalize結果處理
需要保證輸出結果小於 16MB 因為 group 沒有提供轉存選項
db.data.group({
cond: {‘group‘: ‘A‘},
// key: {‘group‘: 1, ‘category‘: 1},
keyf: function(doc) {
var dt = new Date(doc.created);
// or
// var dt = doc.datetime;
return {
year: doc.datetime.getFullYear(),
month: doc.datetime.getMonth() + 1,
day: doc.datetime.getDate()
}
},
initial: {count: 0, category: []},
$reduce: function(curr, result) {
result.count += curr.count;
if (result.category.indexOf(curr.category) == -1) {
result.category.push(curr.category);
}
},
finalize: function(result) {
result.category = result.category.join();
}
})
如果要求聚合大量數據, 就需要用到 mapReduce
三、mapReduce
query聚合前篩選sort對聚合前的數據排序 用來優化 reducelimit限制進入 map 的數據map(function) emit(key, value) 在函數中指定聚合的 K/Vreduce(function) 參數(key, values)key在 map 中定義了,values是在這個 K 下的所有 V 數組finalize處理最後結果out結果轉存 可以選擇另外一個 dbscope設置全局變量jdMode(false) 是否(默認是)把 map/reduce 中間結果轉為 BSON 格式, BSON 格式可以利用磁盤空間, 這樣就可以處理大規模的數據集verbose(true) 詳細信息
如果設 jsMode 為 true 不進行 BSON 轉換, 可以優化 reduce 的執行速度, 但是由於內存限制最大在 emit 數量小於 500,000 時使用
寫 mapReduce 時需要註意
- emit 返回的 value 必須和 reduce 返回的 value 結構一致
reduce函數必須冪等- 詳見 Troubleshoot the Reduce Function
db.data.mapReduce(function() {
var d = this.datetime;
var key = {
year: d.getFullYear(),
month: d.getMonth() + 1,
day: d.getDate(),
};
var value = {
count: this.count,
rows: 1,
groups: [this.group],
}
emit(key, value);
}, function(key, vals) {
var reducedVal = {
count: 0,
groups: [],
rows: 0,
};
for(var i = 0; i < vals.length; i++) {
var v = vals[i];
reducedVal.count += v.count;
reducedVal.rows += v.rows;
for(var j = 0; j < v.groups.length; j ++) {
if (reducedVal.groups.indexOf(v.groups[j]) == -1) {
reducedVal.groups.push(v.groups[j]);
}
}
}
return reducedVal;
}, {
query: {},
sort: {datetime: 1}, // 需要索引 否則結果返回空
limit: 50000,
finalize: function(key, reducedVal) {
reducedVal.avg = reducedVal.count / reducedVal.rows;
return reducedVal;
},
out: {
inline: 1,
// replace: "",
// merge: "",
// reduce: "",
},
scope: {},
jsMode: true
})
測試數據:
> db.newtest.find()
{ "_id" : ObjectId("5a2544352ba57ccba824d7bf"), "group" : "E", "created" : 1402764223, "count" : 63, "datetime" : 1512391126, "title" : "aa", "category" : "C8" }
{ "_id" : ObjectId("5a2544512ba57ccba824d7c0"), "group" : "I", "created" : 1413086660, "count" : 93, "datetime" : 1512391261, "title" : "bb", "category" : "C10" }
{ "_id" : ObjectId("5a2544562ba57ccba824d7c1"), "group" : "H", "created" : 1440750343, "count" : 41, "datetime" : 1512391111, "title" : "cc", "category" : "C1" }
{ "_id" : ObjectId("5a2544562ba57ccba824d7c2"), "group" : "S", "created" : 1437710373, "count" : 14, "datetime" : 1512392136, "title" : "dd", "category" : "C10" }
{ "_id" : ObjectId("5a2544562ba57ccba824d7c3"), "group" : "Z", "created" : 1428307315, "count" : 78, "datetime" : 1512391166, "title" : "ee", "category" : "C5" }
{ "_id" : ObjectId("5a2544562ba57ccba824d7c4"), "group" : "R", "created" : 1402809274, "count" : 74, "datetime" : 1512391162, "title" : "ff", "category" : "C9" }
{ "_id" : ObjectId("5a2544562ba57ccba824d7c5"), "group" : "Y", "created" : 1400571321, "count" : 66, "datetime" : 1512139164, "title" : "gg", "category" : "C2" }
{ "_id" : ObjectId("5a2544562ba57ccba824d7c6"), "group" : "L", "created" : 1416562128, "count" : 5, "datetime" : 1512393165, "title" : "hh", "category" : "C1" }
{ "_id" : ObjectId("5a2544562ba57ccba824d7c7"), "group" : "E", "created" : 1414057884, "count" : 12, "datetime" : 1512391165, "title" : "ii", "category" : "C3" }
{ "_id" : ObjectId("5a2544572ba57ccba824d7c8"), "group" : "L", "created" : 1418879346, "count" : 67, "datetime" : 1512391167, "title" : "gg", "category" : "C3" }
四、總結
| method | allowDiskUse | out | function |
|---|---|---|---|
| aggregate | true | pipeline/collection | false |
| group | false | pipeline | true |
| mapReduce | jsMode | pipeline/collection | true |
aggregate基於累加操作的的聚合 可以重復利用$project/$group一層一層聚合數據, 可以用於大量數據(單輸出結果小於 16MB) 不可用於分片數據mapReduce可以處理超大數據集 需要嚴格遵守 mapReduce 中的結構一致/冪等 寫法, 可增量輸出/合並, 見outoptionsgroupRDB 中的group by簡單需求可用(只有 inline 輸出) 會產生read lock
MongoDB中聚合工具Aggregate等的介紹與使用