
MySQL 高級
阿新 • • 發佈:2017-12-05
執行sql 查看 聯合 優化器 服務 四種 加鎖 這一 dba
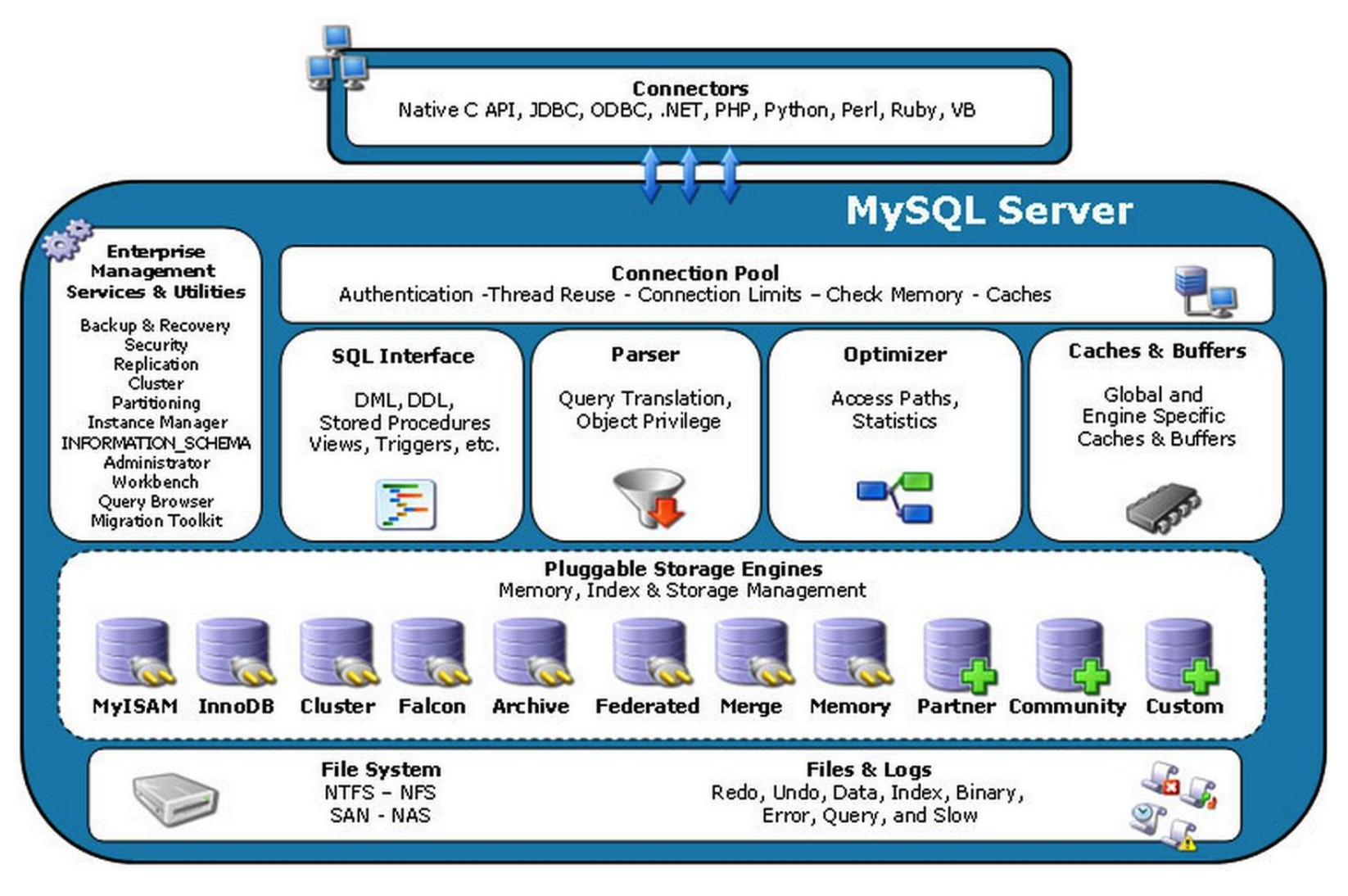
1. MySQL 的架構介紹
1. MySQL 的內部架構
- 連接層
- 服務層
- 引擎層
- 存儲層
2. 查看MySQL存儲引擎
show engines;show variables like ‘%storate_engine%‘;: 查看默認的存儲引擎
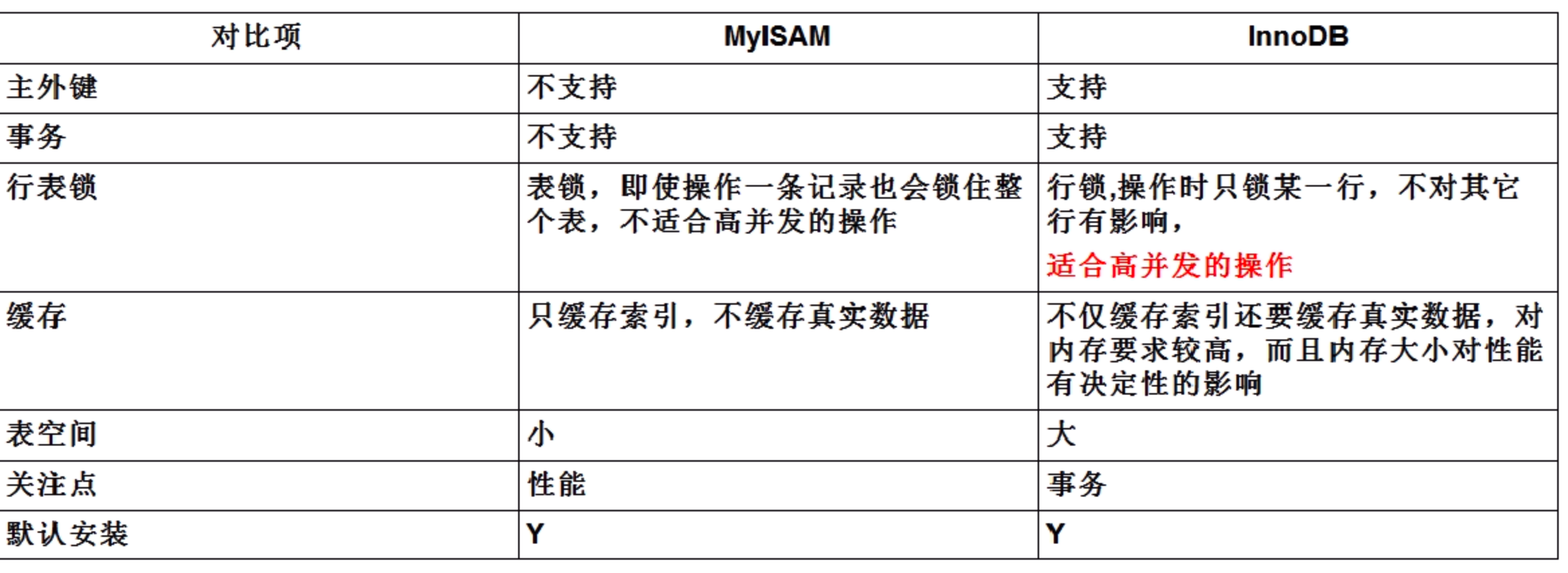
2.1 MyISAM 和 InnoDB 比較
3. SQL優化步驟
- 觀察,至少跑一天,看看生產的慢SQL情況;
- 開啟慢查詢日誌,設置閾值,比如超過5秒鐘的就是慢SQL,並將它抓取出來;
- EXPLAIN+慢SQL分析;
- SHOW profile,查詢SQL在MySQL服務器裏面的執行細節和生命周期情況;
- 運維經理或DBA,進行SQL數據庫服務器的參數調優;
索引優化分析
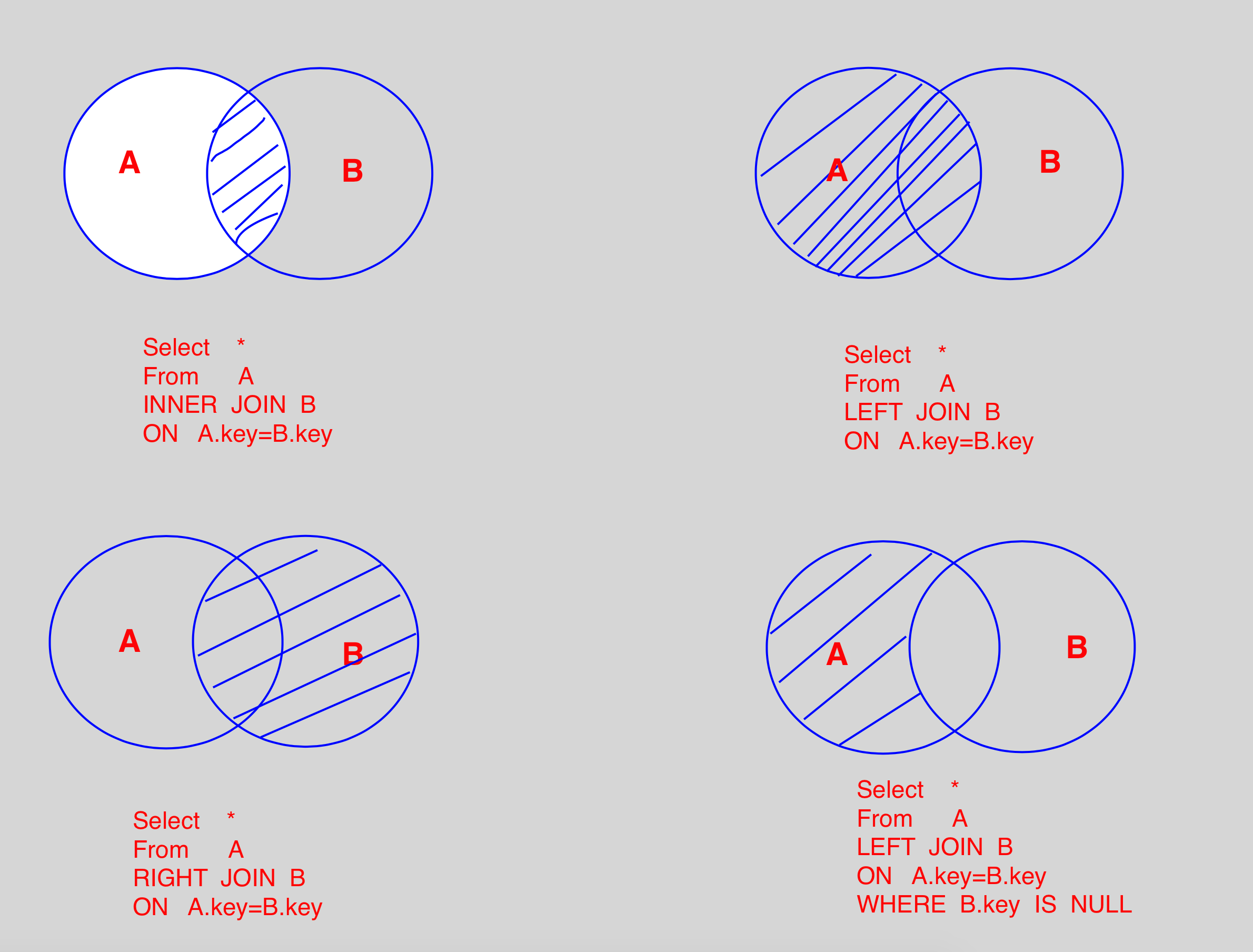
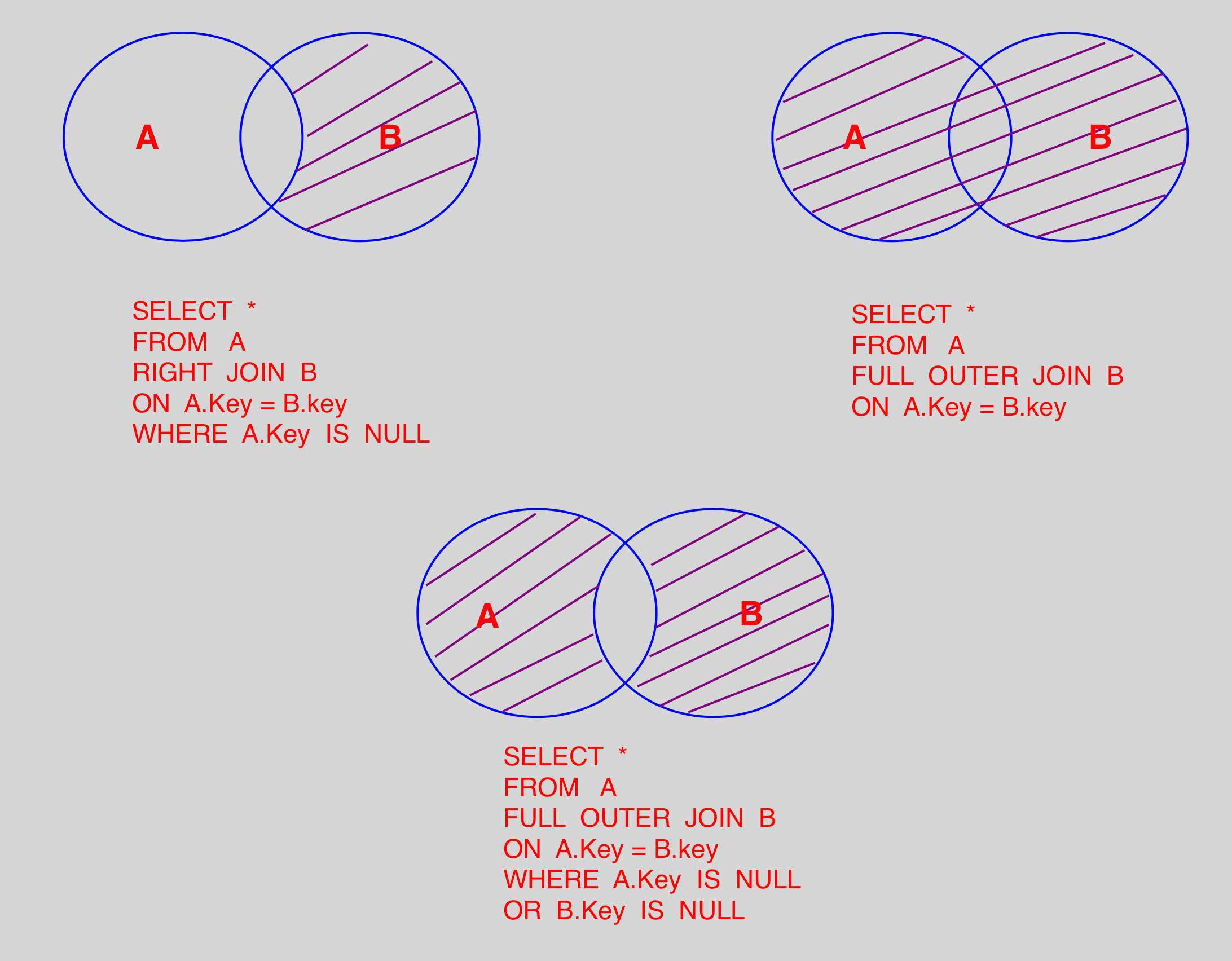
1. 常用Join查詢
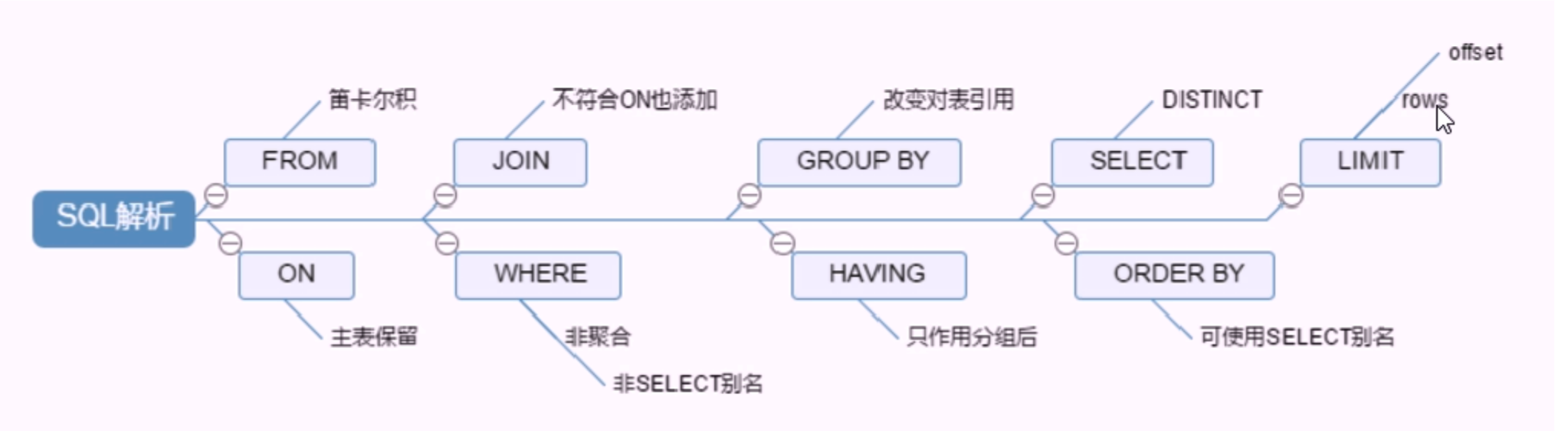
1.1 SQL 執行順序
1.2 Join 圖
2. 索引
- 索引(Index)是幫助MySQL高效獲取數據的數據結構;索引的本質就是排好序的快速查找數據結構;
- 索引的目的在於提高查詢效率,可以類比字典;
- 索引優勢
- 提高數據檢索的效率,降低數據庫的IO成本;
- 通過索引列對數據進行排序,降低數據排序的成本,降低了CPU的消耗;
- 索引劣勢
- 實際上,索引也是一張表,該表保存了主鍵與索引字段,並指向實體表的記錄,所以索引列也是要占用磁盤空間的;
- 雖然索引大大提高了查詢速度,同時卻會降低更新表的速度,例如對表進行INSERT,UPDATE 和 DELETE,因為更新表時,MySQL不僅要保存數據,還要保存一下索引文件,每次更新添加了索引列的字段,都會調整因為
更新所帶來的鍵值變化後的索引信息;
2.1 索引的分類
- 單值索引: 即一個索引只包含單個列,一個表可以有多個單列索引;
- 唯一索引: 索引列的值必須唯一,但允許有空值;
- 復合索引: 即一個索引包含多個列;
- 基本語法:
// 創建 CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length)); ALTER mytable ADD [UNIQUE] INDEX [indexName] ON (columnname(length)); // 刪除 DROP INDEX [indexName] ON mytable; // 查看 SHOW INDEX FROM table_name // 有四種方式來添加數據表的索引: // 1. 該語句添加一個主鍵,這意味著索引值必須是唯一的,且不能為NULL ALTER TABLE tbl_name ADD PRIMARY KEY (column_list); // 2. 這條語句創建索引的值必須是唯一的(除了NULL外,NULL可能會出現多次) ALTER TABLE tbl_name ADD UNIQUE index_name(column_list); // 3. 添加普通索引,索引值可出現多次 ALTER TABLE tbl_name ADD INDEX index_name(column_list); // 4. 該語句指定了索引為 FULLTEXT, 用於全文索引 ALTER TABLE tbl_name ADD FULLTEXT index_name(column_list);
2.2 索引的結構
- BTree 索引
- Hash 索引
- full-text 索引
- R-Tree 索引
2.3 是否創建索引
- 需要創建索引的情況
- 主鍵自動建立唯一索引;
- 頻繁作為查詢條件的字段應該創建索引;
- 查詢中與其他表關聯的字段,外鍵關系建立索引;
- 頻繁更新的字段不適合創建索引;
- WHERE 條件裏用不到的字段不要創建索引;
- 高並發情況下,傾向創建組合索引;
- 查詢中排序的字段,排序字段若通過索引去訪問將大大提高索引速度;
- 查詢中統計或者分組字段
- 不需要創建索引的情況
- 表記錄太少;
- 經常增刪改的表;
- 如果某個數據列包含許多重復的內容,為它建立索引就沒有太大的實際效果;
2.4 性能優化
- MySQL 常見瓶頸
- CPU: CPU在飽和的時候,一般發生在數據裝入內存或從磁盤上讀取數據的時候;
- IO: 磁盤I/O瓶頸發生在裝入數據遠大於內存容量的時候;
- 服務器硬件的性能瓶頸: top, free, iostat 和 vmstat 來查看系統的性能;
- Explain
- 使用EXPLAIN關鍵字,可以模擬優化器執行SQL查詢語句,從而知道MySQL是如何處理SQL語句的,從而分析
查詢語句或是表結構的性能瓶頸; - 語法:
Explain + SQL語句 - 從EXPLAIN結果中獲取:
- 表的讀取順序;
- 數據讀取操作的操作類型;
- 哪些索引可以使用;
- 哪些索引被實際使用;
- 表之間的引用;
- 每張表有多少行被優化器查詢;
- 使用EXPLAIN關鍵字,可以模擬優化器執行SQL查詢語句,從而知道MySQL是如何處理SQL語句的,從而分析

2.4.1 Explain 各字段解釋
id: 表示查詢中執行select子句或操作表的順序- id相同,執行順序由上至下;
- id不同,如果是子查詢,id的序號會遞增,id值越大優先級越高,越先被執行;
- id相同不同,都存在;
select_type- 表示查詢的類型,主要用於區別普通查詢,聯合查詢,子查詢等復雜查詢;
- SIMPLE: 簡單的select查詢,查詢中不包含子查詢或者UNION;
- PRIMARY: 查詢中若包含任何復雜的子部分,最外層查詢則被標記為PRIMARY;
- SUBQUERY: 在SELECT或WHERE列表中包含了子查詢;
- DERIVED: 在FROM列表中,包含的子查詢被標記為DERIVED(衍生),MySQL會遞歸執行這些子查詢,
把結果放在臨時表裏; - UNION: 若第二個SELECT出現在UNION之後,則被標記為UNION;若UNION包含在FROM子句的子查詢中,
外側SELECT將被標記為 DERIVED; - UNION RESULT: 從UNION表獲取結果的SELECT;
table: 顯示這一行的數據是關於哪張表的;type- 顯示查詢使用了何種類型,從最好到最差依次是:
system>const>eq_ref>ref>range>index>ALL; system: 表只有一行記錄(等於系統表),這是const類型的特例,平時不會出現,可以忽略不計;const: 表示通過索引一次就找到了,const用於比較primary key 或者 unique索引;因為只匹配一行數據,
所以查詢很快;如果將主鍵至於where列表中,MySQL就能將該查詢轉換為一個常量;eq_ref: 唯一性索引掃描,對於每個索引鍵,表中只有一條記錄與之匹配;常見於主鍵或唯一索引掃描;ref: 非唯一性索引掃描,返回匹配某個單獨值的所有行;本質上也是一種索引訪問,它返回所有匹配某個單獨值的行,
然而,它可能會找到多個符合條件的行,所以它應該屬於查找和掃描的混合體;range: 只檢索給定範圍的行,使用一個索引來選擇行;key 列顯示使用了哪個索引;一般就是在WHERE語句
中出現between,<,>,in等的查詢;這種範圍掃描索引比全表掃描要好,因為它只需要開始於索引的某一點,
而結束於另一點,不用掃描全部索引;index: Full Index Scan, index與ALL區別為index類型只遍歷索引樹,這通常比ALL快,因為索引文件通常
比數據文件小;(也就是說,雖然all和index都是讀全表,但index是從索引中讀取的,而all是從硬盤中讀的)all: Full Table Scan,將遍歷全表以找到匹配的行;- 一般來說,得保證查詢至少達到range級別,最好能達到ref;
- 顯示查詢使用了何種類型,從最好到最差依次是:
possible_keys:- 顯示可能應用在這張表中的索引,一個或多個;查詢涉及到的字段上若存在索引,則該索引將被列出,但不一定被查詢
實際使用;
- 顯示可能應用在這張表中的索引,一個或多個;查詢涉及到的字段上若存在索引,則該索引將被列出,但不一定被查詢
key:- 表示實際使用的索引,如果為NULL,則沒有使用索引;
- 查詢中若使用了覆蓋索引,則該索引僅出現在key列表中;
key_len:- 表示索引中使用的字節數,可通過該列計算查詢中使用的索引的長度;在不損失精確性的情況下,長度越短越好;
key_len顯示的值為索引字段的最大可能長度,而非實際使用長度,即 key_len 是根據表定義計算而得,不是
通過表內檢索出的;
- 表示索引中使用的字節數,可通過該列計算查詢中使用的索引的長度;在不損失精確性的情況下,長度越短越好;
ref:- 顯示索引的哪一列被使用了,如果可能的話,是一個常數;說明哪些列或常量被用於查找索引列上的值;
rows:- 根據表統計信息及索引選用情況,大致估算出找到所需的記錄所需要讀取的行數;
Extra:- 包含不適合在其他列中顯示,但十分重要的額外信息;
Using filesort: 說明MySQL會對數據使用一個外部的索引排序,而不是按照表內的索引順序進行讀取,
MySQL中無法利用索引完成的排序操作稱為"文件排序";Using temporary: 使用了臨時表保存中間結果,MySQL在對查詢結果排序時,使用臨時表;常見於排序
order by和分組查詢group by;Using index: 表示相應的select操作中使用了覆蓋索引(Covering Index),避免訪問了表的數據行,效率
不錯!如果同時出現using where,表明索引被用來執行索引鍵值的查找;如果沒有同時出現using where,表明
索引用來讀取數據而非執行查找操作- 覆蓋索引:就是select的數據列只用從索引中就能夠取得,不必讀取數據行,MySQL可以利用索引返回select列表
中的字段,而不必根據索引再次讀取數據文件,換句話說,查詢列要被所建的索引覆蓋; Using where: 表明使用了where過濾;Using join buffer: 使用了連接緩存;impossible where: where 子句的值總是false,不能用來獲取任何元組;
2.5 索引優化
- Join語句的優化
- 盡可能減少Join語句中的NestedLoop的循環總次數,"永遠用小結果集驅動大的結果集";
- 優先優化NestedLoop的內層循環;
- 保證Join語句中被驅動表上Join條件字段已經被索引;
- 當無法保證被驅動表的Join條件字段被索引且內存資源充足的前提下,不要太吝嗇JoinBuffer的設置;
- 索引失效
- 全值匹配;
- 最佳左前綴法則,指的是查詢從索引的最左前列開始並且不跳過索引中的列;
- 不在索引列上做任何操作(計算,函數,(自動or手動)類型轉換),會導致索引失效而轉向全表掃描;
- 存儲引擎不能使用索引中範圍條件右邊的列;
- 盡量使用覆蓋索引(只訪問索引的查詢(索引列或查詢列一致)),減少
select *; - MySQL在使用不等於(
!= 或者 <>)的時候,無法使用索引會導致全表掃描; is null, is not null也無法使用索引;- like 以通配符開頭(
%abc...),MySQL索引失效,會變成全表掃描的操作;
因此,可以使用like abc%,或者使用覆蓋索引解決like ‘%字符串%‘索引失效的問題; - 字符串不加單引號,索引失效;
- 少用or,用它來連接時,會導致索引失效;
- 總結:
- 對於單鍵索引,盡量選擇針對當前Query過濾性更好的索引;
- 在選擇組合索引的時候,當前Query中過濾型最好的字段在索引字段順序中,位置越靠前越好;
- 在選擇組合索引的時候,盡量選擇可以能夠包含當前Query中的WHERE子句中更多字段的索引;
- 盡可能通過分析統計信息和調整Query的寫法來達到選擇合適索引的目的;
- 優化總結口訣
- 全值匹配我最愛,最左前綴要遵守;
- 帶頭大哥不能死,中間兄弟不能斷;
- 索引列上少計算,範圍之後全失效;
- LIKE百分寫最右,覆蓋索引不寫星;
- 不等空值還有or,索引失效要少用;
- VAR引號不可丟,SQL高級也不難!
3. 查詢截取分析
3.1 查詢優化
- 小表驅動大表,即小的數據集驅動大的數據集;
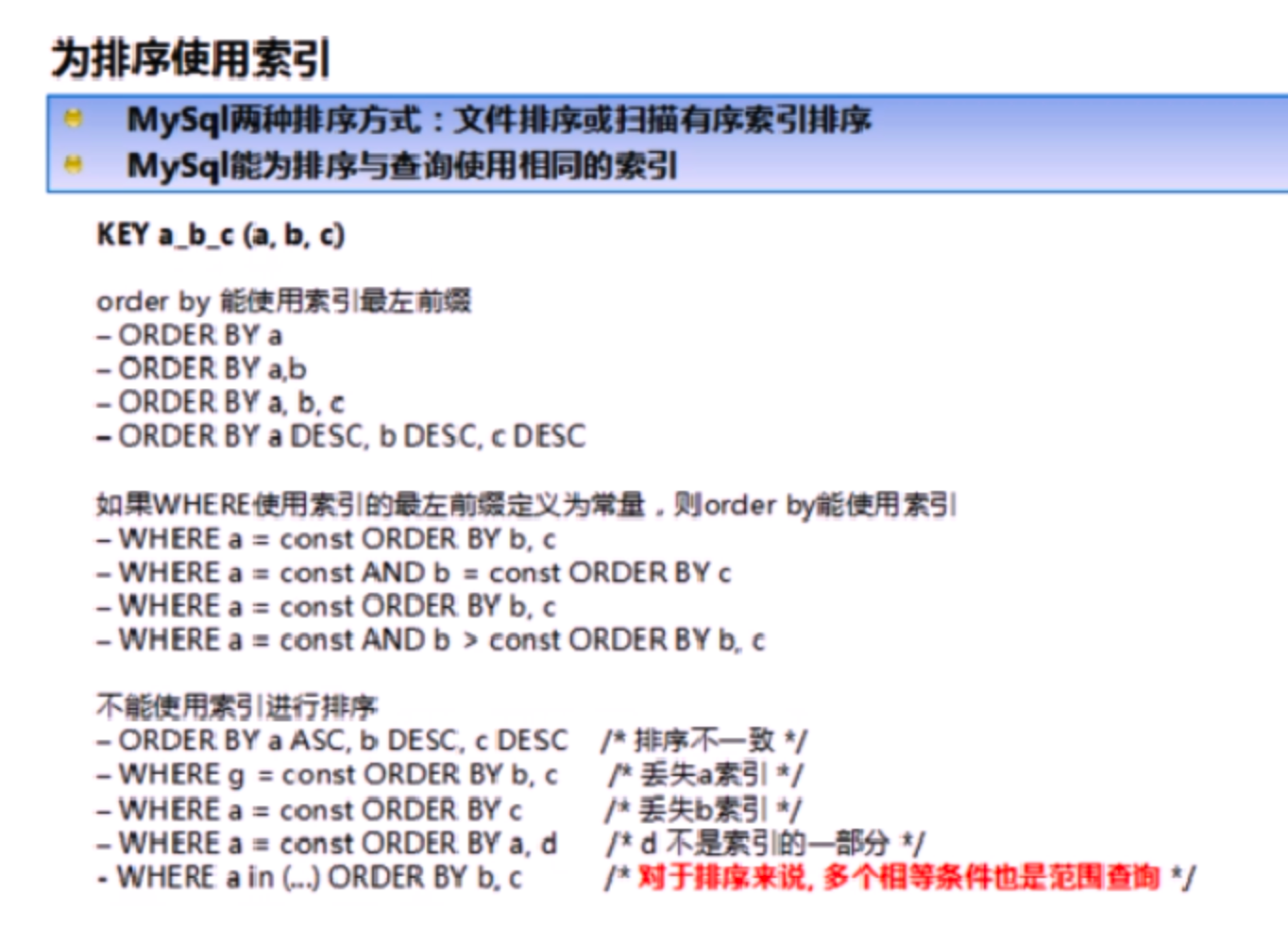
ORDER BY關鍵字優化ORDER BY子句,盡量使用Index方式排序,避免使用FileSort方式排序;- 盡可能在索引列上完成排序操作,遵照索引建的最佳左前綴;
- 如果不再索引列上,FileSort有兩種算法:
- 雙路排序:取一批數據,要到磁盤進行兩次掃描, MySQL4.1之前;
- 單路排序
- 增大"sort_buffer_size"參數的設置;
- 增大"max_length_for_sort_data"參數的設置;
GROUP BY關鍵字優化GROUP BY實質是先排序後進行分組,遵照索引建的最佳左前綴;- 當無法使用索引列時,增大max_length_for_sort_data參數的設置,增大sort_buffer_size參數的設置;
- WHERE性能高於HAVING,能寫在WHERE限定的條件,就不要去HAVING限定了;
3.2 慢查詢日誌
- MySQL的慢查詢日誌是MySQL提供的一種日誌記錄,它用來記錄在MySQL中響應時間超過閾值的語句,具體指運行時間
超過long_query_time值的SQL,則會被記錄到慢查詢日誌中; - long_query_time 的默認值為10,即運行10秒以上的語句;
- MySQL數據庫默認沒有開啟慢查詢日誌,可以使用
SHOW VARIABLES LIKE ‘%slow_query_log%‘;查看; - 開啟慢查詢日誌:
set global slow_query_log=1;,只對當前數據庫生效,如果MySQL重啟後,則會失效; SHOW VARIABLES LIKE ‘long_query_time%‘;查看系統默認慢的閾值時間;set global long_query_time=3;設置慢的閾值時間;- 日誌分析工具
mysqldumpslow;
3.3 Show Profile
- 是MySQL提供的可以用來分析當前會話中語句執行的資源消耗情況,可以用於SQL的調優的測量;
show variables like ‘profiling‘;默認為關閉狀態;set profiling=on;設置為開啟;
4. MySQL 鎖機制
- 表鎖(偏向MyISAM存儲引擎)
- MyISAM 在執行查詢語句(SELECT)前,會自動給涉及的所有表加讀鎖,在執行增刪改操作前,會自動給涉及
的表加寫鎖; - 對MyISAM表的讀操作(加讀鎖),不會阻塞其他進程對同一表的讀請求,但會阻塞對同一表的寫請求;只有當讀鎖
釋放後,才會執行其他進程的寫操作; - 對MyISAM表的寫操作(加寫鎖),會阻塞其他進程對同一表的讀和寫操作,只有當寫鎖釋放後,才會執行其他進程
的讀寫操作; - 簡而言之,讀鎖會阻塞寫,但是不會阻塞讀;而寫鎖則會把讀和寫都阻塞;
show open tables;查看哪些表被加鎖了;
- MyISAM 在執行查詢語句(SELECT)前,會自動給涉及的所有表加讀鎖,在執行增刪改操作前,會自動給涉及
- 行鎖(偏向InnoDB存儲引擎)
show status like ‘innodb_row_lock%‘;: 通過檢查InnoDB_row_lock狀態變量,來分析系統上的行鎖
爭奪情況;
- 優化建議:
- 盡可能讓所有數據檢索都通過索引來完成,避免無索引行鎖升級為表鎖;
- 合理設計索引,盡量縮小鎖的範圍;
- 盡可能減少索引條件,避免間隙鎖;
- 盡量控制事務大小,減少鎖定資源量和時間長度;
- 盡可能低級別事務隔離;
5. 主從復制
- MySQL 復制過程分為三步:
- master將改變記錄到二進制日誌(binary log),這些記錄過程叫做二進制日誌時間,binary log events;
- slave 將 master 的 binary log events 拷貝到它的中繼日誌(relay log);
- slave 重做中繼日誌中的事件,將改變應用到自己的數據庫中,MySQL復制是異步的且串行化的;
- 復制的基本原則
- 每個slave只有一個master;
- 每個slave只能有一個唯一的服務器ID;
- 每個master可以有多個slave;
- 復制的最大問題: 延時;
MySQL 高級