
MySQL 索引設計概要
在關系型數據庫中設計索引其實並不是復雜的事情,很多開發者都覺得設計索引能夠提升數據庫的性能,相關的知識一定非常復雜。

然而這種想法是不正確的,索引其實並不是一個多麽高深莫測的東西,只要我們掌握一定的方法,理解索引的實現就能在不需要 DBA 的情況下設計出高效的索引。
本文會介紹 數據庫索引設計與優化 中設計索引的一些方法,讓各位讀者能夠快速的在現有的工程中設計出合適的索引。
磁盤 IO
一個數據庫必須保證其中存儲的所有數據都是可以隨時讀寫的,同時因為 MySQL 中所有的數據其實都是以文件的形式存儲在磁盤上的,而從磁盤上隨機訪問對應的數據非常耗時,所以數據庫程序和操作系統提供了緩沖池和內存以提高數據的訪問速度。
除此之外,我們還需要知道數據庫對數據的讀取並不是以行為單位進行的,無論是讀取一行還是多行,都會將該行或者多行所在的頁全部加載進來,然後再讀取對應的數據記錄;也就是說,讀取所耗費的時間與行數無關,只與頁數有關。
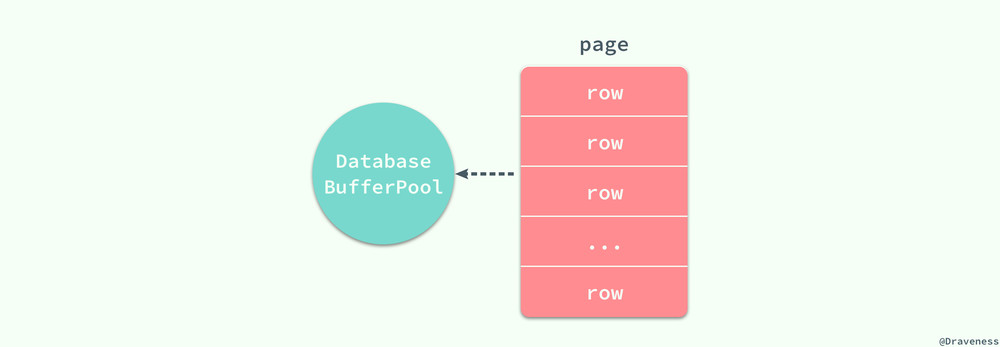
在 MySQL 中,頁的大小一般為 16KB,不過也可能是 8KB、32KB 或者其他值,這跟 MySQL 的存儲引擎對數據的存儲方式有很大的關系,文中不會展開介紹,不過索引或行記錄是否在緩存池中極大的影響了訪問索引或者數據的成本。
隨機讀取
數據庫等待一個頁從磁盤讀取到緩存池的所需要的成本巨大的,無論我們是想要讀取一個頁面上的多條數據還是一條數據,都需要消耗約 10ms 左右的時間:
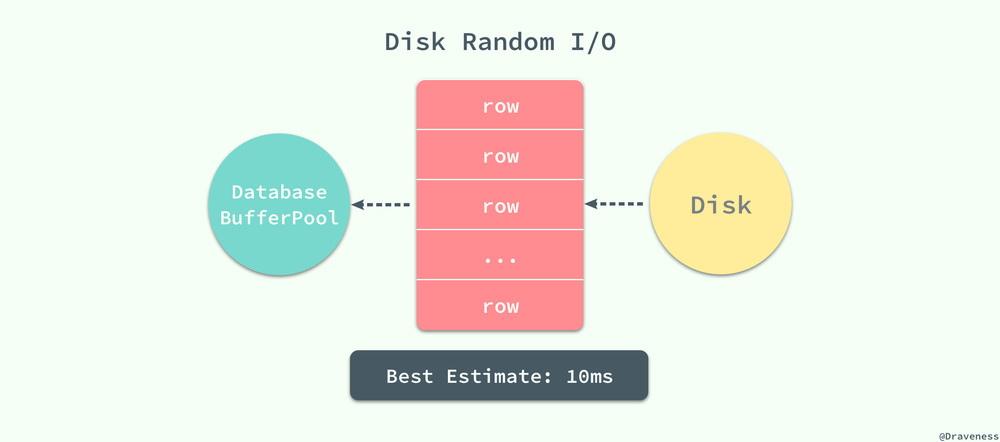
10ms 的時間在計算領域其實是一個非常巨大的成本,假設我們使用腳本向裝了 SSD 的磁盤上順序寫入字節,那麽在 10ms 內可以寫入大概 3MB 左右的內容,但是數據庫程序在 10ms 之內只能將一頁的數據加載到數據庫緩沖池中,從這裏可以看出隨機讀取的代價是巨大的。
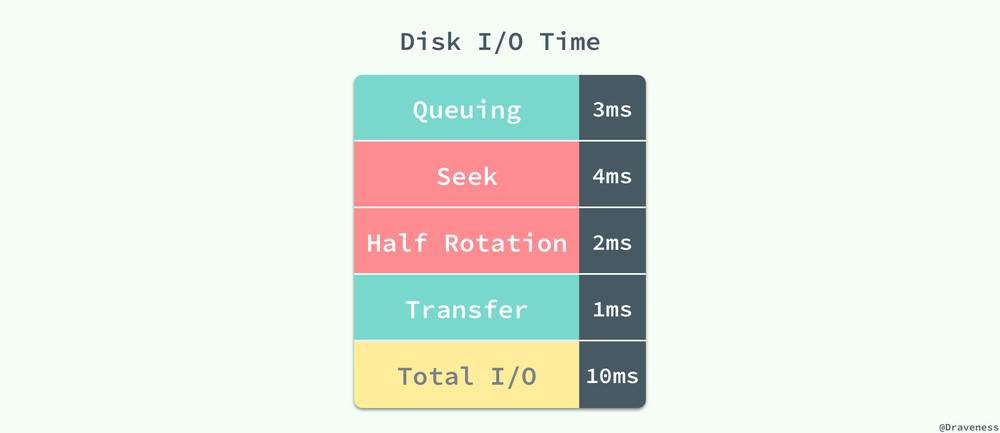
這 10ms 的一次隨機讀取是按照每秒 50 次的讀取計算得到的,其中等待時間為 3ms、磁盤的實際繁忙時間約為 6ms,最終數據頁從磁盤傳輸到緩沖池的時間為 1ms 左右,在對查詢進行估算時並不需要準確的知道隨機讀取的時間,只需要知道估算出的 10ms 就可以了。
內存讀取
如果在數據庫的緩存池中沒有找到對應的數據頁,那麽會去內存中尋找對應的頁面:
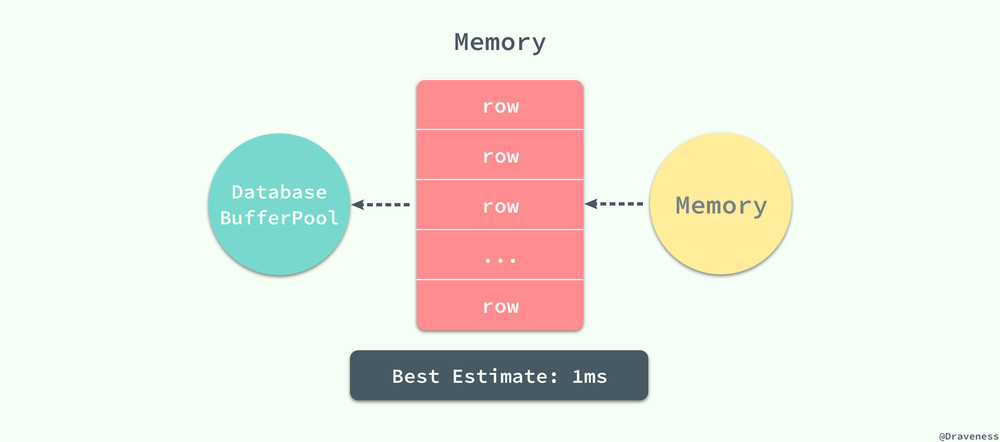
當對應的頁面存在於內存時,數據庫程序就會使用內存中的頁,這能夠將數據的讀取時間降低一個數量級,將 10ms 降低到 1ms;MySQL 在執行讀操作時,會先從數據庫的緩沖區中讀取,如果不存在與緩沖區中就會嘗試從內存中加載頁面,如果前面的兩個步驟都失敗了,最後就只能執行隨機 IO 從磁盤中獲取對應的數據頁。
順序讀取
從磁盤讀取數據並不是都要付出很大的代價,當數據庫管理程序一次性從磁盤中順序讀取大量的數據時,讀取的速度會異常的快,大概在 40MB/s 左右。

如果一個頁面的大小為 4KB,那麽 1s 的時間就可以讀取 10000 個頁,讀取一個頁面所花費的平均時間就是 0.1ms,相比隨機讀取的 10ms 已經降低了兩個數量級,甚至比內存中讀取數據還要快。
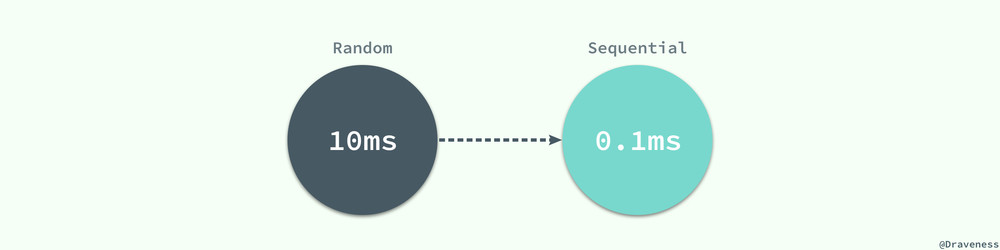
數據頁面的順序讀取有兩個非常重要的優勢:
- 同時讀取多個界面意味著總時間的消耗會大幅度減少,磁盤的吞吐量可以達到 40MB/s;
- 數據庫管理程序會對一些即將使用的界面進行預讀,以減少查詢請求的等待和響應時間;
小結
數據庫查詢操作的時間大都消耗在從磁盤或者內存中讀取數據的過程,由於隨機 IO 的代價巨大,如何在一次數據庫查詢中減少隨機 IO 的次數往往能夠大幅度的降低查詢所耗費的時間提高磁盤的吞吐量。
查詢過程
在上一節中,文章從數據頁加載的角度介紹了磁盤 IO 對 MySQL 查詢的影響,而在這一節中將介紹 MySQL 查詢的執行過程中以及數據庫中的數據的特征對最終查詢性能的影響。
索引片(Index Slices)
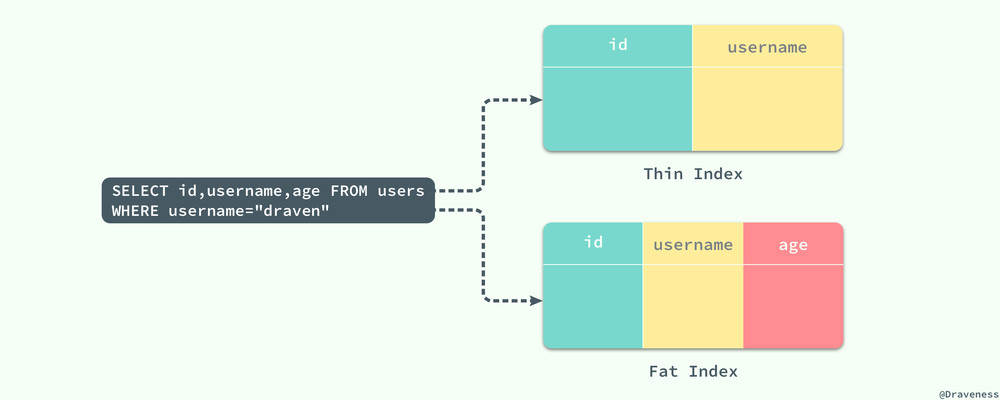
索引片其實就是 SQL 查詢在執行過程中掃描的一個索引片段,在這個範圍中的索引將被順序掃描,根據索引片包含的列數不同,數據庫索引設計與優化 書中對將索引分為寬索引和窄索引:
主鍵列
id在所有的 MySQL 索引中都是一定會存在的。
對於查詢 SELECT id, username, age FROM users WHERE username="draven" 來說,(id, username) 就是一個窄索引,因為該索引沒有包含存在於 SQL 查詢中的 age 列,而 (id, username, age) 就是該查詢的一個寬索引了,它包含這個查詢中所需要的全部數據列。
寬索引能夠避免二次的隨機 IO,而窄索引就需要在對索引進行順序讀取之後再根據主鍵 id 從主鍵索引中查找對應的數據:
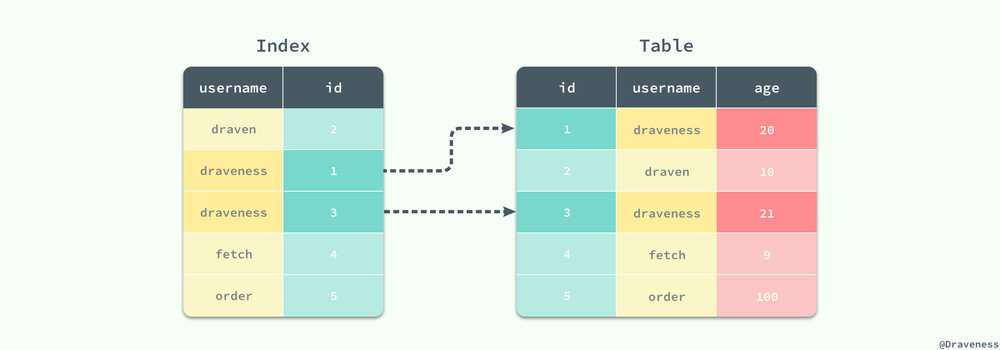
對於窄索引,每一個在索引中匹配到的記錄行最終都需要執行另外的隨機讀取從聚集索引中獲得剩余的數據,如果結果集非常大,那麽就會導致隨機讀取的次數過多進而影響性能。
過濾因子
從上一小節對索引片的介紹,我們可以看到影響 SQL 查詢的除了查詢本身還與數據庫表中的數據特征有關,如果使用的是窄索引那麽對表的隨機訪問就不可避免,在這時如何讓索引片變『薄』就是我們需要做的了。
一個 SQL 查詢掃描的索引片大小其實是由過濾因子決定的,也就是滿足查詢條件的記錄行數所占的比例:

對於 users 表來說,sex=”male” 就不是一個好的過濾因子,它會選擇整張表中一半的數據,所以在一般情況下我們最好不要使用 sex 列作為整個索引的第一列;而 name=”draven” 的使用就可以得到一個比較好的過濾因子了,它的使用能過濾整個數據表中 99.9% 的數據;當然我們也可以將這三個過濾進行組合,創建一個新的索引 (name, age, sex) 並同時使用這三列作為過濾條件:

當三個過濾條件都是等值謂詞時,幾個索引列的順序其實是無所謂的,索引列的順序不會影響同一個 SQL 語句對索引的選擇,也就是索引 (name, age, sex) 和 (age, sex, name) 對於上圖中的條件來說是完全一樣的,這兩個索引在執行查詢時都有著完全相同的效果。
組合條件的過濾因子就可以達到十萬分之 6 了,如果整張表中有 10w 行數據,也只需要在掃描薄索引片後進行 6 次隨機讀取,這種直接使用乘積來計算組合條件的過濾因子其實有一個比較重要的問題:列與列之間不應該有太強的相關性,如果不同的列之間有相關性,那麽得到的結果就會比直接乘積得出的結果大一些,比如:所在的城市和郵政編碼就有非常強的相關性,兩者的過濾因子直接相乘其實與實際的過濾因子會有很大的偏差,不過這在多數情況下都不是太大的問題。
對於一張表中的同一個列,不同的值也會有不同的過濾因子,這也就造成了同一列的不同值最終的查詢性能也會有很大差別:

當我們評估一個索引是否合適時,需要考慮極端情況下查詢語句的性能,比如 0% 或者 50% 等;最差的輸入往往意味著最差的性能,在平均情況下表現良好的 SQL 語句在極端的輸入下可能就完全無法正常工作,這也是在設計索引時需要註意的問題。
總而言之,需要掃描的索引片的大小對查詢性能的影響至關重要,而掃描的索引記錄的數量,就是總行數與組合條件的過濾因子的乘積,索引片的大小最終也決定了從表中讀取數據所需要的時間。
匹配列與過濾列
假設在 users 表中有 name、age 和 (name, sex, age) 三個輔助索引;當 WHERE 條件中存在類似 age = 21 或者 name = “draven” 這種等值謂詞時,它們都會成為匹配列(Matching Column)用於選擇索引樹中的數據行,但是當我們使用以下查詢時:
SELECT * FROM users
WHERE name = "draven" AND sex = "male" AND age > 20;
雖然我們有 (name, sex, age) 索引包含了上述查詢條件中的全部列,但是在這裏只有 name 和 sex 兩列才是匹配列,MySQL 在執行上述查詢時,會選擇 name 和 sex 作為匹配列,掃描所有滿足條件的數據行,然後將 age 當做過濾列(Filtering Column):
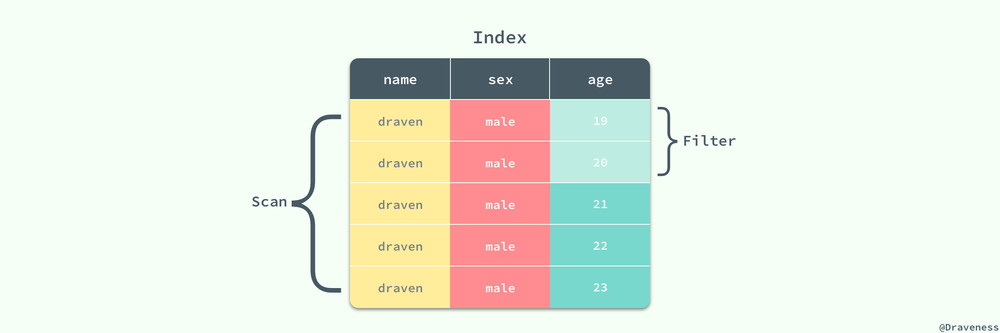
過濾列雖然不能夠減少索引片的大小,但是能夠減少從表中隨機讀取數據的次數,所以在索引中也扮演著非常重要的角色。
索引的設計
作者相信文章前面的內容已經為索引的設計提供了充足的理論基礎和知識,從總體來看如何減少隨機讀取的次數是設計索引時需要重視的最重要的問題,在這一節中,我們將介紹 數據庫索引設計與優化 一書中歸納出的設計最佳索引的方法。
三星索引
三星索引是對於一個查詢語句可能的最好索引,如果一個查詢語句的索引是三星索引,那麽它只需要進行一次磁盤的隨機讀及一個窄索引片的順序掃描就可以得到全部的結果集;因此其查詢的響應時間比普通的索引會少幾個數量級;根據書中對三星索引的定義,我們可以理解為主鍵索引對於 WHERE id = 1 就是一個特殊的三星索引,我們只需要對主鍵索引樹進行一次索引訪問並且順序讀取一條數據記錄查詢就結束了。

為了滿足三星索引中的三顆星,我們分別需要做以下幾件事情:
- 第一顆星需要取出所有等值謂詞中的列,作為索引開頭的最開始的列(任意順序);
- 第二顆星需要將 ORDER BY 列加入索引中;
- 第三顆星需要將查詢語句剩余的列全部加入到索引中;
三星索引的概念和星級的給定來源於 數據庫索引設計與優化 書中第四章三星索引一節。
如果對於一個查詢語句我們依照上述的三個條件進行設計,那麽就可以得到該查詢的三星索引,這三顆星中的最後一顆星往往都是最容易獲得的,滿足第三顆星的索引也就是上面提到的寬索引,能夠避免大量的隨機 IO,如果我們遵循這個順序為一個 SQL 查詢設計索引那麽我們就可以得到一個完美的索引了;這三顆星的獲得其實也沒有表面上這麽簡單,每一顆星都有自己的意義:

- 第一顆星不只是將等值謂詞的列加入索引,它的作用是減少索引片的大小以減少需要掃描的數據行;
- 第二顆星用於避免排序,減少磁盤 IO 和內存的使用;
- 第三顆星用於避免每一個索引對應的數據行都需要進行一次隨機 IO 從聚集索引中讀取剩余的數據;
在實際場景中,問題往往沒有這麽簡單,我們雖然可以總能夠通過寬索引避免大量的隨機訪問,但是在一些復雜的查詢中我們無法同時獲得第一顆星和第二顆星。
SELECT id, name, age FROM users
WHERE age BETWEEN 18 AND 21
AND city = "Beijing"
ORDER BY name;
在上述查詢中,我們總可以通過增加索引中的列以獲得第三顆星,但是如果我們想要獲得第一顆星就需要最小化索引片的大小,這時索引的前綴必須為 (city, age),在這時再想獲得第三顆星就不可能了,哪怕在 age 的後面添加索引列 name,也會因為 name 在範圍索引列 age 後面必須進行一次排序操作,最終得到的索引就是 (city, age, name, id):
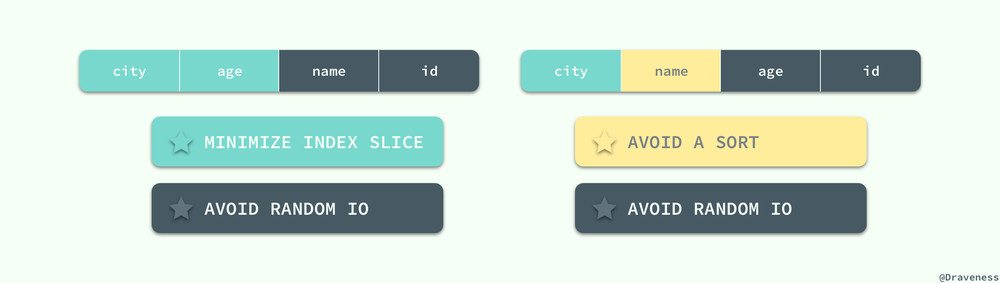
如果我們需要在內存中避免排序的話,就需要交換 age 和 name 的位置了,在這時就可以得到索引 (city, name, age, id),當一個 SQL 查詢中同時擁有範圍謂詞和 ORDER BY 時,無論如何我們都是沒有辦法獲得一個三星索引的,我們能夠做的就是在這兩者之間做出選擇,是犧牲第一顆星還是第二顆星。
總而言之,在設計單表的索引時,首先把查詢中所有的等值謂詞全部取出以任意順序放在索引最前面,在這時,如果索引中同時存在範圍索引和 ORDER BY 就需要權衡利弊了,希望最小化掃描的索引片厚度時,應該將過濾因子最小的範圍索引列加入索引,如果希望避免排序就選擇 ORDER BY 中的全部列,在這之後就只需要將查詢中剩余的全部列加入索引了,通過這種固定的方法和邏輯就可以最快地獲得一個查詢語句的二星或者三星索引了。
總結
在單表上對索引進行設計其實還是非常容易的,只需要遵循固定的套路就能設計出一個理想的三星索引,在這裏強烈推薦 數據庫索引設計與優化 這本書籍,其中包含了大量與索引設計與優化的相關內容;在之後的文章中讀者也會分析介紹書中提供的幾種估算方法,來幫助我們通過預估問題設計出更高效的索引。
如果對文章內容的有疑問,可以在博客下面評論留言。
Reference
- 數據庫索引設計與優化
- File Space Management
- Inside of Hard Drive - YouTube
- Hard Disk Working - How does a hard disk work - Hard Drive - YouTube
原文鏈接:MySQL 索引設計概要 · 面向信仰編程
Follow: Draveness · GitHub
MySQL 索引設計概要