
Apriori算法實現
阿新 • • 發佈:2017-12-07
就是 load 興趣 是否 tid 最小 原來 這也 map
本次緱老師布置的作業較為簡單,其原理實現也是非常的清楚。
關於關聯規則,細想一下,其本質,筆者竊以為:仍然是分類的思想,其本質為,可以劃分為一類的item,其內部就有一定的相關性,那麽,挖掘的本質,就是在分類以後,找到同一類不同item中的相關性(為啥可以分到同一類中去)。
筆者剛才蕩了一段代碼,發現其可移植性非常好。現在,下面就貼出代碼、結果和原網址。有興趣的同學可以繼續參考一下。
實現環境:Ubuntu下Python2.7(Ubuntu自帶)
其代碼如下:
# -*- coding: utf-8 -*- """ Apriori exercise. Created on Fri Nov 27 11:09:03 2015 @author: 90Zeng""" def loadDataSet(): ‘‘‘創建一個用於測試的簡單的數據集‘‘‘ return [ [ 1, 3, 4 ], [ 2, 3, 5 ], [ 1, 2, 3, 5 ], [ 2, 5 ] ] def createC1( dataSet ): ‘‘‘ 構建初始候選項集的列表,即所有候選項集只包含一個元素, C1是大小為1的所有候選項集的集合 ‘‘‘ C1 = [] for transaction in dataSet: for item in transaction:if [ item ] not in C1: C1.append( [ item ] ) C1.sort() return map( frozenset, C1 ) def scanD( D, Ck, minSupport ): ‘‘‘ 計算Ck中的項集在數據集合D(記錄或者transactions)中的支持度, 返回滿足最小支持度的項集的集合,和所有項集支持度信息的字典。 ‘‘‘ ssCnt = {} for tid in D: # 對於每一條transaction forcan in Ck: # 對於每一個候選項集can,檢查是否是transaction的一部分 # 即該候選can是否得到transaction的支持 if can.issubset( tid ): ssCnt[ can ] = ssCnt.get( can, 0) + 1 numItems = float( len( D ) ) retList = [] supportData = {} for key in ssCnt: # 每個項集的支持度 support = ssCnt[ key ] / numItems # 將滿足最小支持度的項集,加入retList if support >= minSupport: retList.insert( 0, key ) # 匯總支持度數據 supportData[ key ] = support return retList, supportData ####################################### if __name__ == ‘__main__‘: # 導入數據集 myDat = loadDataSet() # 構建第一個候選項集列表C1 C1 = createC1( myDat ) # 構建集合表示的數據集 D D = map( set, myDat ) # 選擇出支持度不小於0.5 的項集作為頻繁項集 L, suppData = scanD( D, C1, 0.5 ) print u"頻繁項集L:", L print u"所有候選項集的支持度信息:", suppData ################################################ # Aprior算法 def aprioriGen( Lk, k ): ‘‘‘ 由初始候選項集的集合Lk生成新的生成候選項集, k表示生成的新項集中所含有的元素個數 ‘‘‘ retList = [] lenLk = len( Lk ) for i in range( lenLk ): for j in range( i + 1, lenLk ): L1 = list( Lk[ i ] )[ : k - 2 ]; L2 = list( Lk[ j ] )[ : k - 2 ]; L1.sort();L2.sort() if L1 == L2: retList.append( Lk[ i ] | Lk[ j ] ) return retList def apriori( dataSet, minSupport = 0.5 ): # 構建初始候選項集C1 C1 = createC1( dataSet ) # 將dataSet集合化,以滿足scanD的格式要求 D = map( set, dataSet ) # 構建初始的頻繁項集,即所有項集只有一個元素 L1, suppData = scanD( D, C1, minSupport ) L = [ L1 ] # 最初的L1中的每個項集含有一個元素,新生成的 # 項集應該含有2個元素,所以 k=2 k = 2 while ( len( L[ k - 2 ] ) > 0 ): Ck = aprioriGen( L[ k - 2 ], k ) Lk, supK = scanD( D, Ck, minSupport ) # 將新的項集的支持度數據加入原來的總支持度字典中 suppData.update( supK ) # 將符合最小支持度要求的項集加入L L.append( Lk ) # 新生成的項集中的元素個數應不斷增加 k += 1 # 返回所有滿足條件的頻繁項集的列表,和所有候選項集的支持度信息 return L, suppData ################################################### if __name__ == ‘__main__‘: # 導入數據集 myDat = loadDataSet() # 選擇頻繁項集 L, suppData = apriori( myDat, 0.5 ) print u"頻繁項集L:", L print u"所有候選項集的支持度信息:", suppData
其結果為:
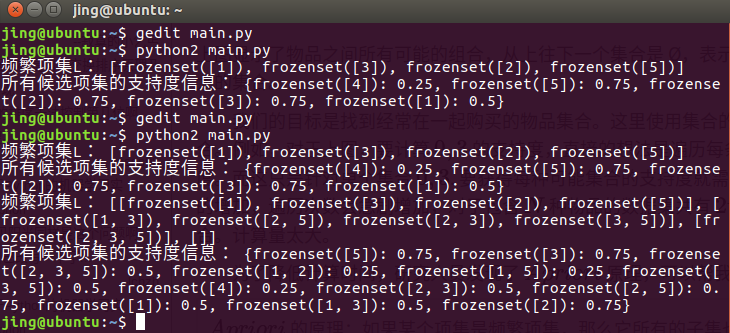
其含義可以從結果直觀的看出。這也是Python的優勢,其開源性保證了代碼庫的量足夠大。
原網址:https://www.cnblogs.com/90zeng/p/apriori.html
歡迎大家探討。
Apriori算法實現