
cs231n spring 2017 lecture11 聽課筆記
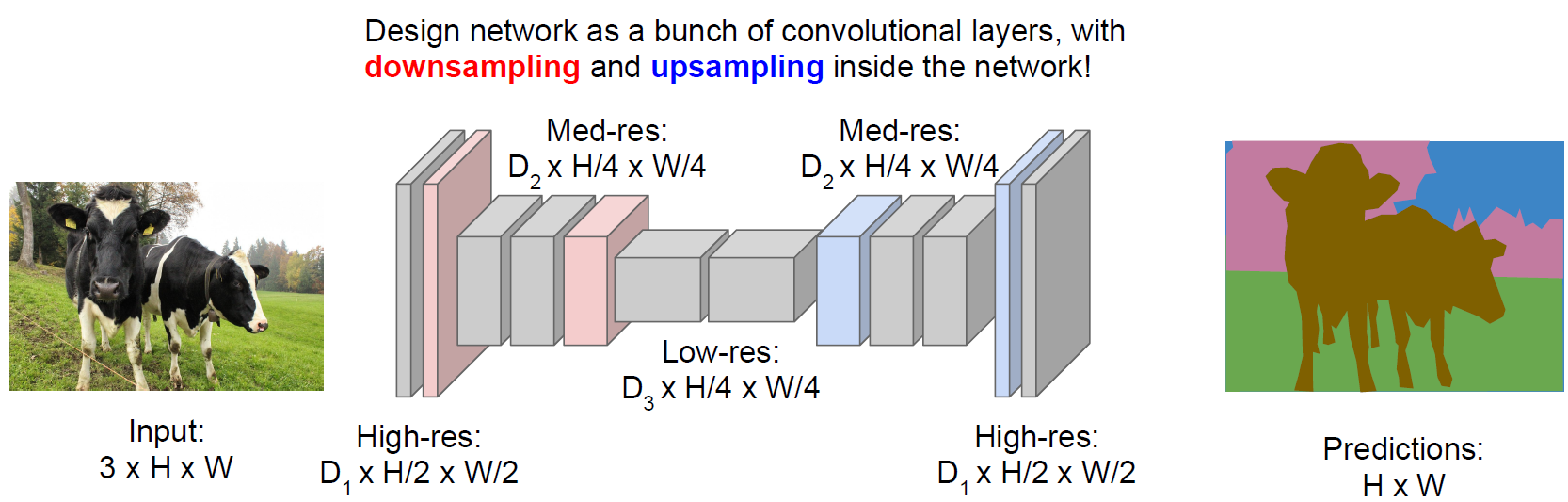
1. Semantic Segmentation
把每個像素分類到某個語義。
為了減少運算量,會先降采樣再升采樣。降采樣一般用池化層,升采樣有各種“Unpooling”、“Transpose Convolution”(文獻中也叫“Upconvolution”之類的其他名字)。
這個問題的訓練數據的獲得非常昂貴,因為需要一個像素一個像素的貼標簽。
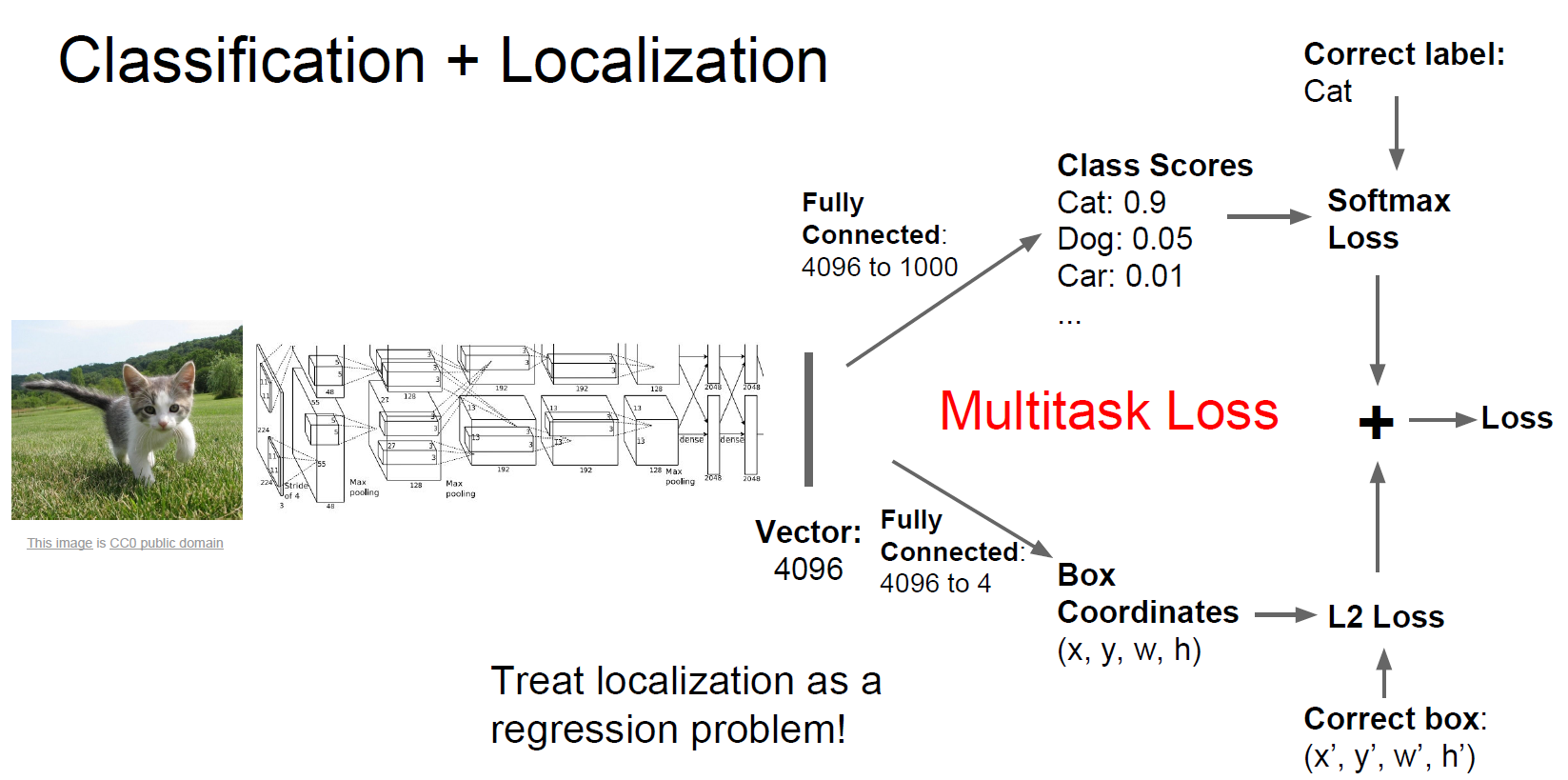
2. Classification + Localizatoin
一般用同一個網絡,一方面得出分類,一方面得出Bounding box的位置和大小。
3. Object Detection
預先設定好要找哪些objects,一旦圖片裏發現,就框出來。Classification + Localizatoin一般是針對單個物體,而這裏是針對多個物體。
Sliding window:計算量太大,舍棄。
Region Proposals:先找可能有物體的圖片區域,然後一個個處理,在CPU上大概幾秒的時間。這種方法在深度學習之前就出來了。
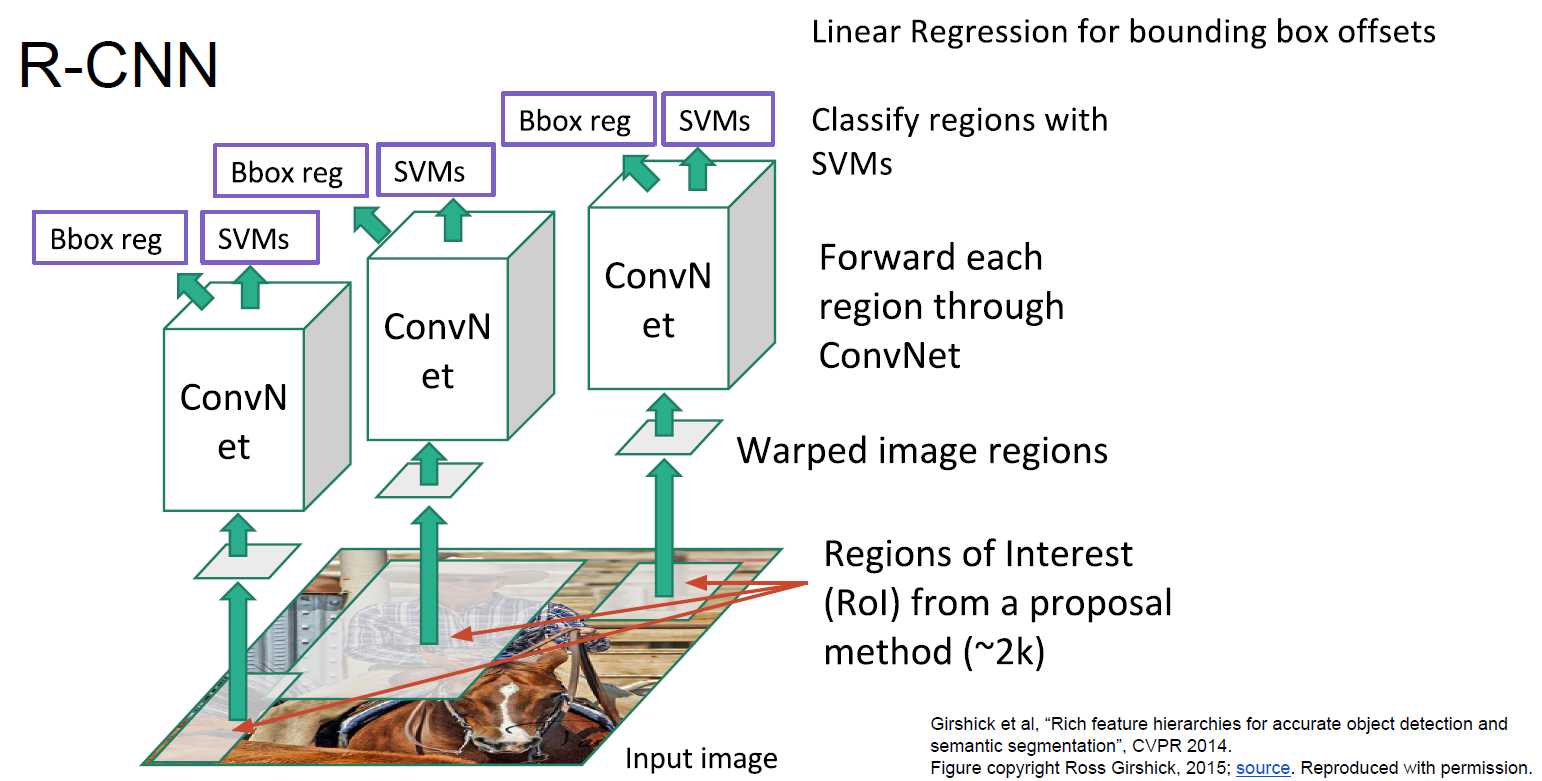
R-CNN:先找出region proposal,然後把region proposal調整成神經網絡需要的大小,然後給神經網絡計算,最後通過SVM分類。
訓練很慢(84h),也非常耗內存。預測也很慢(47秒 VGG16)
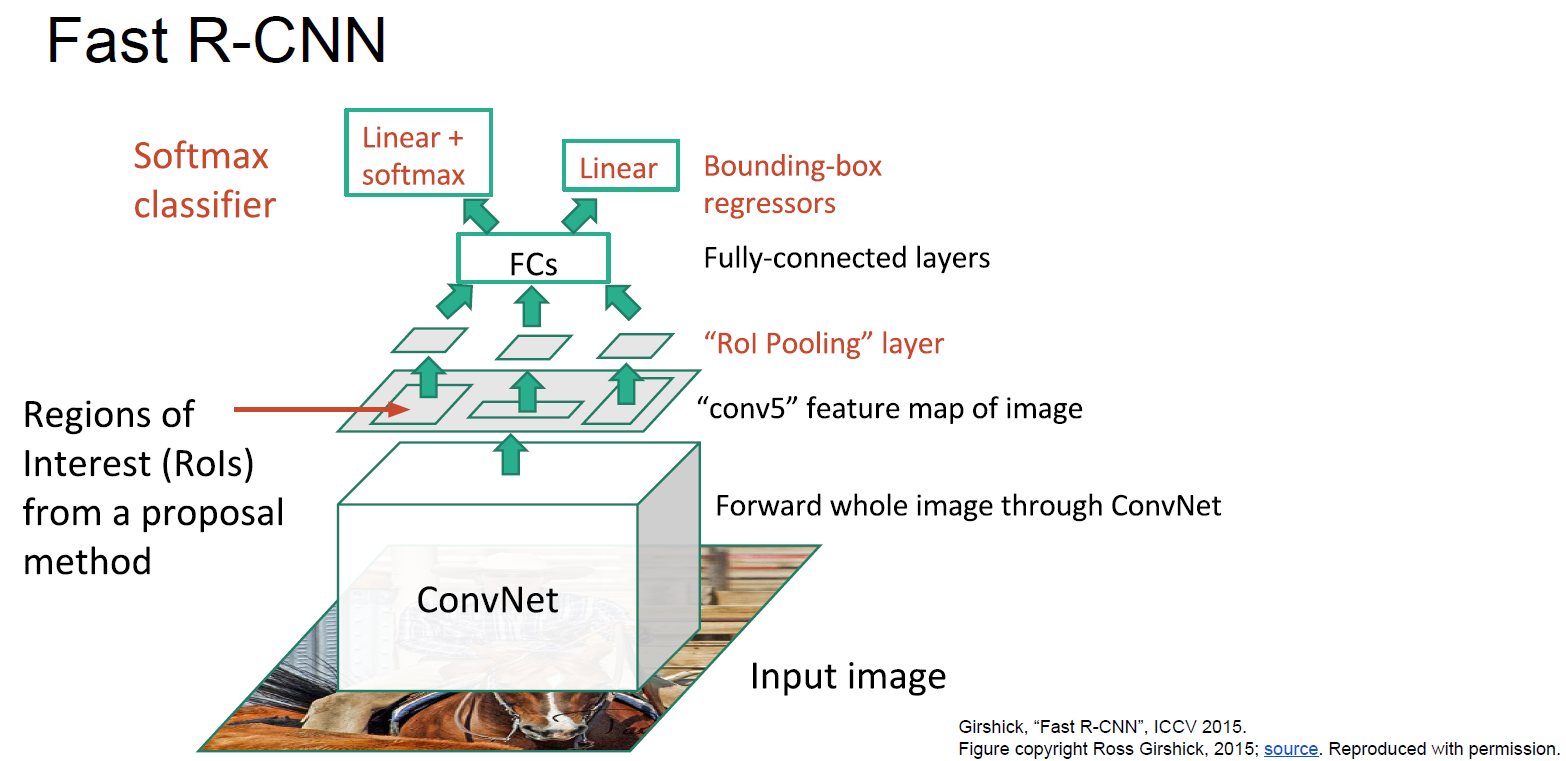
Fast R-CNN:相比R-CNN快很多,訓練(8.75h),預測(計算region proposal花2秒,神經網絡預測花0.32秒)。
訓練的時候把下圖中的Linear + softmax和Linear加起來得到multi-task loss。
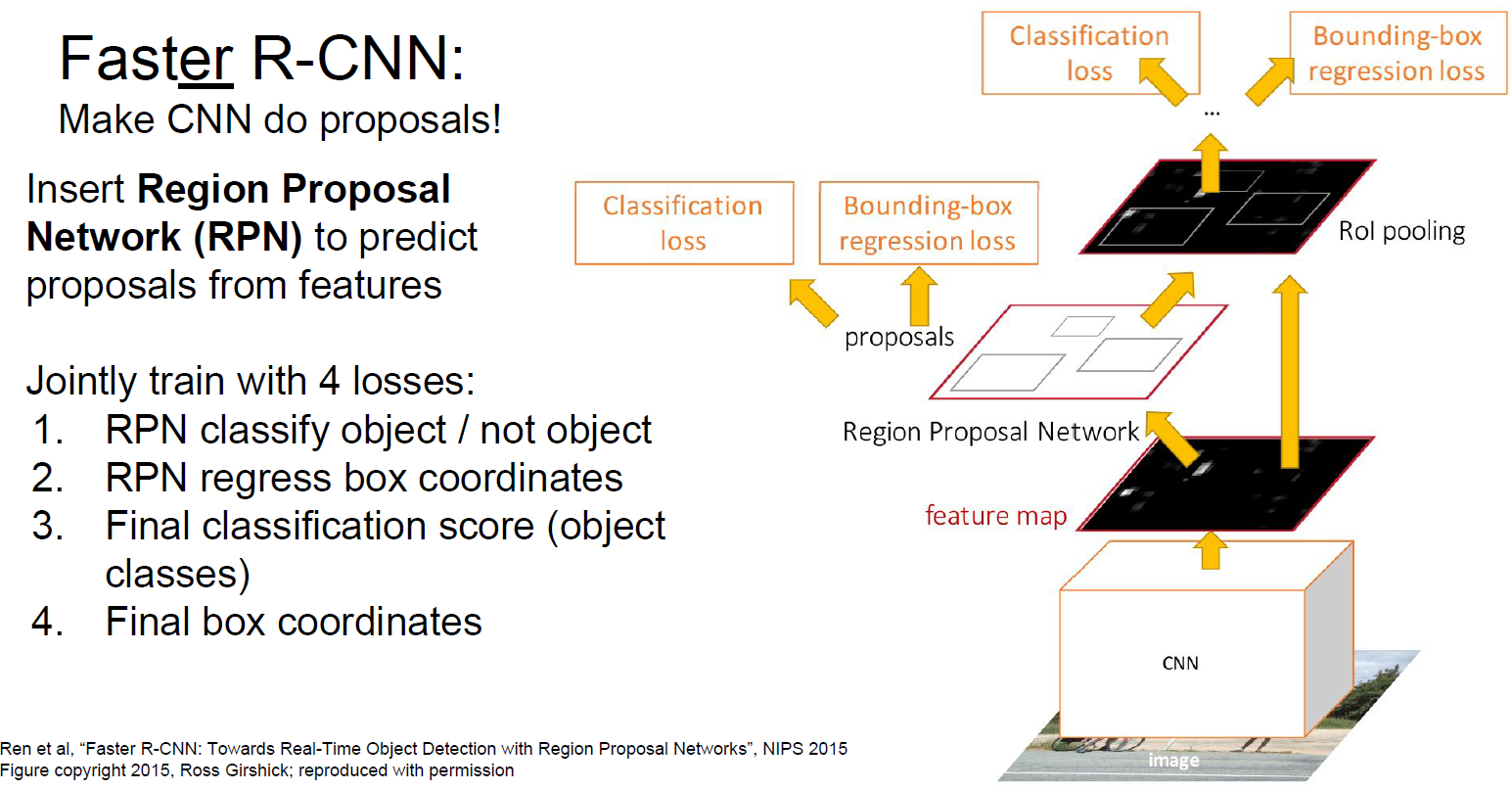
Faster R-CNN:用卷積層去預測region proposal。比Fast R-CNN更快,預測耗時0.2秒。
YOLO(Redmon et al., CVPR 2016)/SSD(Liu et al, "Single-Shot MultiBox Detecotr", ECCV 2016):這兩種方法沒有用region proposal,更快,但是相對不那麽準。Faster R-CNN更慢,但是更準。
Object Detection + Captioning (DenseCap, CVPR 2016)
4. Instance Segmentation
Semantic Segmentation和Object Detection的結合,找出多個物體,並且判斷每個像素屬於哪個分類。
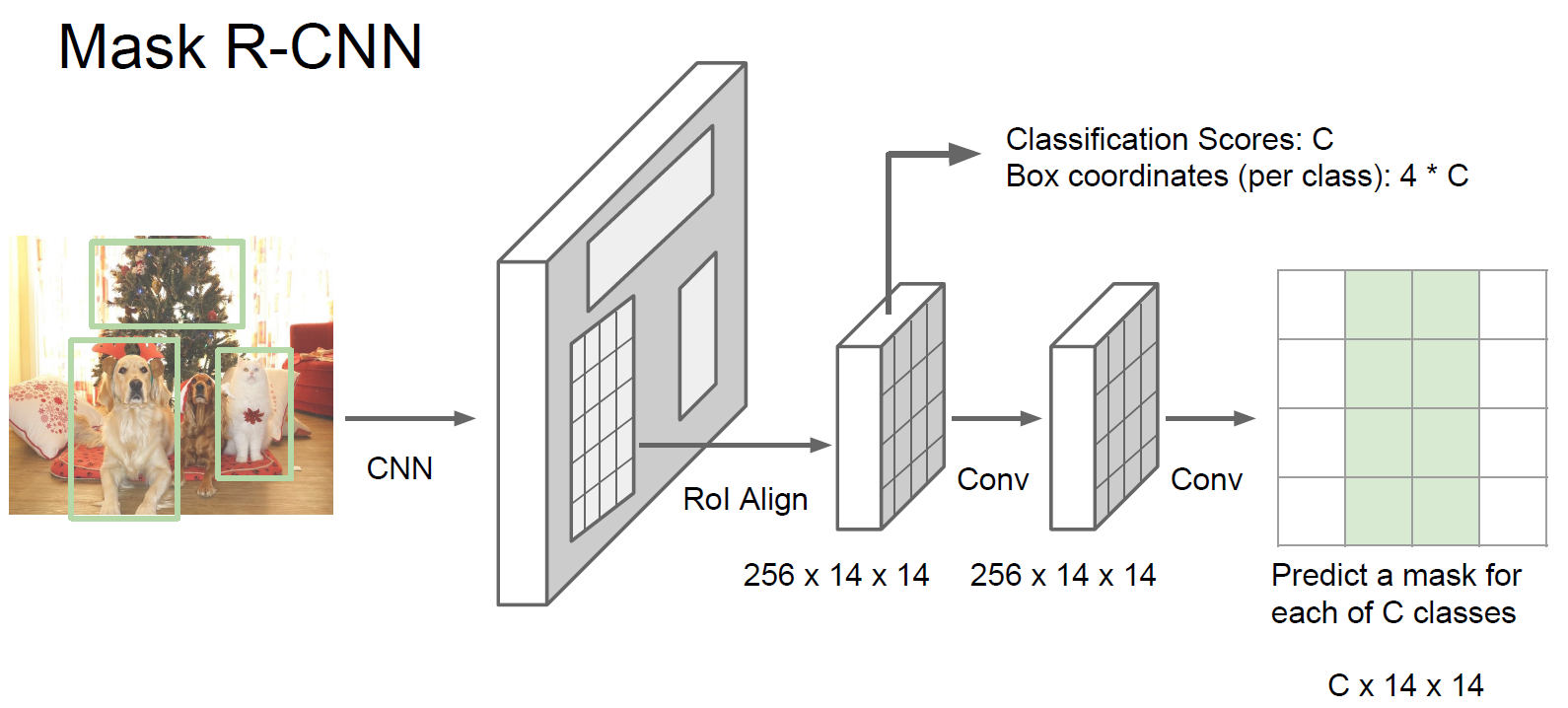
Mask R-CNN (He et al., 2017),網絡有兩個分支,第一個執行Object Detection,第二個執行Semantic Segmentation。這個網絡把之前的都融合起來,是集大成者,表現非常非常好。在Object Detection分支加入對人體關節的識別,還能識別人的pose。基於Faster R-CNN,接近real-time。
cs231n spring 2017 lecture11 聽課筆記