
mysql性能分析-------profiling和explain
1. profiling之性能分析
MySQL5.0.37版本以上支持了Profiling – 官方手冊。此工具可用來查詢 SQL 會執行多少時間,System lock和Table lock 花多少時間等等,對定位一條語句的 I/O消耗和CPU消耗 非常重要。
查看profiling;
select @@profiling; 啟動profiling: set @@profiling=1 關閉profiling : set @@profiling=0;
sql語句; 1.查看profile記錄
show profiles;
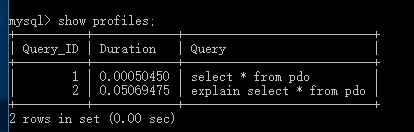
Duration:我需要時間;
query:執行的sql語句;
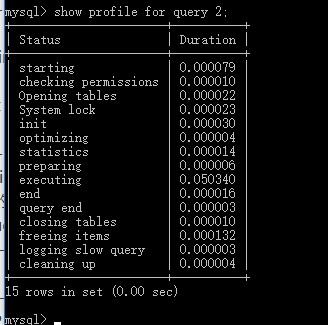
2.查看詳情:
show profile for query 2;
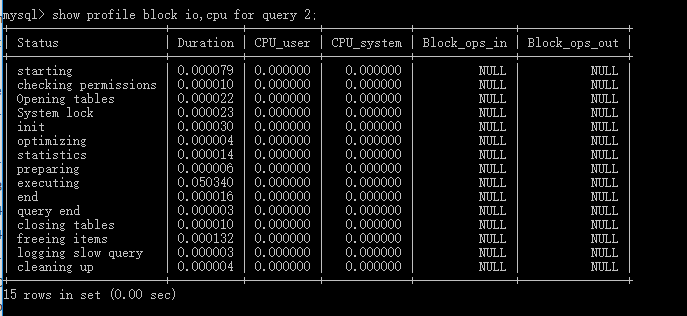
3.查看cup和io情況
show profile cpu,block io for query 2;
2.explain 分析

1.id:一組數字,操作順序,如果id相同,則執行順序由上至下,如果是子查詢,id的序號遞增,值越大優先級越高,越先被執行;
2.select_type:表示每個字句的類型,簡單還是復雜,取值如下;
a>simple :簡單查詢,無子查詢或union等;
b>primary:查詢中若包含復雜的子部分,最外層則被標記為primary;
c>subquery:在select或where中若包含子查詢,則該子查詢被標記為subquery;
d>derived:from中包含子查詢,被標記為derived;
e>union:若select出現在union之後,則被標記為union;
f>union result:從union表中獲取結果的select將被標記為union result;
3.table 查詢的數據庫表名稱
4.type 聯合查詢使用的類型
all :全表掃描
index:全表掃描,只是掃描表的時候按照索引次序 進行而不是行。主要優點就是避免了排序, 但是開銷仍然非常大。
range:索引範圍掃描
ref:非唯一性索引掃描,交返回匹配單獨值的所有行,常見於使用非唯一性索引或唯一性索引的非唯一前綴進行的查找。
eq_ref:唯一性索引掃描
const、system:當mysql對查詢的某部分進行優化,並轉換為一個常量時。如將主鍵置於where列表中,mysql就能將該查詢轉換為一個常量。system是const的特例,當查詢的表只有一行的情況下,即可使用system。
5. possible_keys: 指出mysql能使用哪個索引在表中找到行,查詢涉及的字段上若存在索引,則該索引將被列出。如果為空,說明沒有可用的索引
6.key:使用到了哪個索引,這裏列出的是實際使用到的索引,若沒有使用索引,則顯示為null。
7.key_len:使用的索引的長度。在不損失精確性的情況 下,長度越短越好。
8.ref:顯示索引的哪一列被使用了
9.rows:MYSQL 認為必須檢查的用來返回請求數據的行數.找到所需記錄,需要讀取的行數,越少越好
10.Extra:不適合在其他列顯示,但卻十分重要的信息,常見的有如下值:
a) Using index:使用了索引檢索。
b) where used:使用了where限制,但是用索引還不夠。
c) Using temporary:需要使用臨時表來存儲結果集,常見於排序和分組查詢。性能差。
d) Using filesoft:使用了文件排序,性能差。
參考資料:http://www.cnblogs.com/sybblogs/p/7999353.html
http://blog.csdn.net/asia_kobe/article/details/78683482
mysql性能分析-------profiling和explain