
轉:WOM 編碼與一次寫入型存儲器的重復使用
轉自:WOM 編碼與一次寫入型存儲器的重復使用 (很有趣的算法設計)——來自 Matrix67: The Aha Moments 大神
計算機歷史上,很多存儲器的寫入操作都是一次性的。 Wikipedia 的 write once read many 詞條裏提到了兩個最經典的例子,一個是大家熟悉的 CD-R 和 DVD-R ,另一個則是更早的打孔卡片和打孔紙帶。在介紹後者時,文章裏說:“雖然第一次打孔之後,沒有孔的區域還能繼續打孔,但這麽做幾乎沒有任何實際用處。”因此,打孔卡片和打孔紙帶通常也被看成是只能寫入一次的存儲設備。
事實上真的是這樣嗎? 1982 年, Ronald Rivest 和 Adi Shamir 發表了一篇題為《怎樣重復使用一次寫入型存儲器》(How to Reuse a “Write-Once” Memory)的論文,提出了一個很有意思的想法。大家有覺得 Ronald Rivest 和 Adi Shamir 這兩個人名都很眼熟嗎?沒錯,這兩個人之前曾經和 Leonard Adleman 一道,共同建立了 RSA 公鑰加密系統。其中, Ronald Rivest 就是 RSA 中的那個 R , Adi Shamir 就是 RSA 中的那個 S 。
在這篇論文的開頭, Ronald Rivest 和 Adi Shamir 舉了一個非常簡單的例子。假設初始時存儲器裏的所有 bit 全是 0 。存儲器的寫入操作是單向的,它只能把 0 變成 1 ,卻不能把 1 變成 0 。我們可以把存儲器裏的每 3 個 bit 分為一組,每一組都只表達 2 個 bit 的值,其中 000 和 111 都表示 00 , 100 和 011 都表示 01 , 010 和 101 都表示 10 , 001 和 110 都表示 11 。好了,假設某一天,你想用這 3 個 bit 表示出 01 ,你就可以把這 3 個 bit 從 000 改為 100 ;假設過了幾天,你想再用這 3 個 bit 表示出 10 ,你就可以把這 3 個 bit 從 100 改為 101 。事實上,容易驗證,對於 {00, 01, 10, 11} 中的任意兩個不同的元素 a 、 b ,我們都能找到兩個 3 位 01 串,使得前者表示的是 a ,後者表示的是 b ,並且前者能僅僅通過變 0 為 1 而得到後者。因此,每組裏的 bit 都能使用兩遍,整個存儲器也就具備了“寫完還能再改一次”的功能。
不可思議的是,兩次表達出 {00, 01, 10, 11} 中的元素,其信息量足足有 4 個 bit ,這卻只用 3 個 bit 的空間就解決了。這乍看上去似乎有些矛盾,但仔細一想你就會發現,這並沒有什麽問題。在寫第二遍數據的時候,我們會把第一遍數據抹掉,因此總的信息量不能按照 4 個 bit 來算。利用這種技術,我們便能在 300KB 的一次寫入型存儲器裏寫入 200 KB 的內容,再把這 200KB 的內容改寫成另外 200KB 的內容。這聽上去似乎是神乎其神的“黑科技”,然而原理卻異常簡單。
由於“一次寫入型存儲器”(write-once memory)的首字母縮寫為 WOM ,因此重復多次使用一次寫入型存儲器的編碼方案也就叫做 WOM 編碼了。上面展示的編碼系統就是一個 WOM 編碼,它可以重復 2 次利用 3 個 bit 的空間,每次都能寫入 2 個 bit 的數據。 Ronald Rivest 和 Adi Shamir 把這個 WOM 編碼擴展為了一系列更大的 WOM 編碼,使得我們能重復 2k – 2 + 1 次利用 2k – 1 個 bit 的空間,每次都能寫入 k 個 bit 的數據。不妨讓我們以 k = 5 為例,對此做一個簡單的介紹吧。
所以,我們現在要說明的就是,如何重復 9 次利用 31 個 bit 的空間,每次都能寫入 5 個 bit 的數據。首先,把這 31 個 bit 的位置分別編號為 00001, 00010, 00011, …, 11110, 11111 。然後我們規定,一個 31 位 01 串究竟表示哪 5 個 bit ,就看數字 1 的位置編號全都合在一起,各個位置上究竟有奇數個 1 還是偶數個 1 。假設某個 31 位 01 串的第 1 位、第 3 位和第 31 位是 1 ,其余的地方都是 0 。把這 3 個位置的編號列出來,就得到 00001, 00011, 11111 。在這 3 個編號中,左起第 1 位上的數字 1 共有 1 個,左起第 2 位上的數字 1 共有 1 個,左起第 3 位上 1 個,左起第 4 位上 2 個,左起第 5 位上 3 個。其中,左起第 1 、 2 、 3 、 5 位上都是奇數個 1 ,左起第 4 位上共有偶數個 1 。因此,這個 31 位 01 串最終表達的值就是 11101 。
我們將會說明,只要這個 31 位 01 串裏還有至少 16 個數字 0 ,我們都能把最多兩個 0 改成 1 ,使得整個 31 位 01 串轉而表達任意一個我們想要的新的值。不妨假設這個 31 位 01 串當前表達的是 11101 ,而我們現在想讓它表達 10110 。顯然,如果在這個 31 位 01 串中,編號 01011 對應位置上的是數字 0 ,我們把它改成數字 1 就行了。如果在這個 31 位 01 串中,編號 01011 對應位置上的是數字 1 ,這又該怎麽辦呢?我們可以按照“同-異-同-異-異”的原則,把除了 01011 以外的 30 個編號分成 15 組:
| (00001, 01010) | (00010, 01001) | (00011, 01000) | (00100, 01111) | (00101, 01110) |
| (00110, 01101) | (00111, 01100) | (10000, 11011) | (10001, 11010) | (10010, 11001) |
| (10011, 11000) | (10100, 11111) | (10101, 11110) | (10110, 11101) | (10111, 11100) |
於是,每一組裏的兩個編號都滿足,左起第 1 位一共有 0 個或 2 個數字 1 ,左起第 2 位一共有恰好 1 個數字 1 ,左起第 3 位一共有 0 個或 2 個數字 1 ,左起第 4 位一共有恰好 1 個數字 1 ,左起第 5 位一共有恰好 1 個數字 1 。其實, 01011 本來應該和 00000 配對,但 00000 並不在我們的編號範圍裏。所以, 01011 也就沒在上面的列表裏出現。
但別忘了,這個 31 位 01 串裏至少有 16 個數字 0 。由於編號 01011 所對應的是數字 1 ,因此所有的數字 0 都落在了上面 30 個編號上,其中必然會有兩個數字 0 落到了同一組裏。把這兩個 0 都改成 1 ,整個 31 位 01 串所表達的值就能從 11101 變為 10110 了。
初始時,這個 31 位 01 串為 000…00 。只要裏面還有至少 16 個數字 0 ,我們就可以對數據進行改寫。第一次改寫顯然只需要把一個 0 變成 1 即可,今後的每次改寫也最多只會把兩個 0 變成 1 。因此,這個 31 位 01 串可以被我們重復使用 9 次。根據同樣的道理,一個 2k – 1 位 01 串就能被我們重復使用 2k – 2 + 1 次,每次寫入的都是 k 個 bit 的數據。這正是由 Ronald Rivest 和 Adi Shamir 擴展出來的 WOM 編碼,它對於一切大於等於 2 的整數 k 都適用。之前那個把 300KB 當兩個 200KB 用的“黑科技”,其實不過是 k = 2 時的一個特例罷了。
隨著 k 值的增加,這個科技是“越來越黑”呢,還是“越來越不黑”呢?在這類 WOM 編碼中,我們可以把每 2k – 1 個 bit 當作 k · (2k – 2 + 1) 個 bit 來用,其比值為 k · (2k – 2 + 1) / (2k – 1) 。這個比值越高,就代表每個 bit 的利用率越高。當 k = 2 時,這個比值只有 1.333… ;當 k = 5 時,這個比值為 1.4516… ;當 k = 10 時,這個比值增加到了 2.51222… 。可見,這個科技是“越來越黑”的。事實上,我們有 (2k – 2 + 1) / (2k – 1) > 2k – 2 / 2k = 1 / 4 ,因此不管 k 是多少,整個比值都大於 k / 4 了。這立即證明了,在 WOM 編碼中,單個 bit 的利用率可以達到任意大。
不過, k / 4 雖然成為了一個下界,但同時也成為了一個“檻”。當 k = 20 時,單個 bit 的利用率為 5.00002384… ;當 k = 50 時,單個 bit 的利用率為 12.5000000000000555… 。隨著 k 的增加,單個 bit 的利用率最終穩定在了 k / 4 的水平。單個 bit 的利用率能超越 k / 4 的水平嗎?能!
我們可以讓每個編號下都有多個 bit 。例如,我們幹脆用 3100 個 bit 的存儲空間來表示 5 個 bit 的值,其中前 100 位的編號都是 00001 ,下 100 位的編號都是 00010 ,等等。為了確定出這個 3100 位 01 串究竟表達了哪 5 個 bit 的值,我們就要先找出哪些編號所對應的 100 位 01 串裏含有奇數個數字 1 ,再把這些編號全都合在一起,看看各個位置上究竟有奇數個 1 還是偶數個 1 。編碼過程也就變得更簡單了。剛開始,這個 3100 位 01 串全是 0 ,代表的值也就是 00000 。如果你想寫入數據 00010 ,即對左起第 4 位取反,你就把編號為 00010 的那 100 個 bit 中的其中一個 0 改成 1 ;如果你想把它改寫成 01101 ,即對左起第 2 位、第 3 位、第 4 位、第 5 位都取反,你就把編號為 01111 的那 100 個 bit 中的其中一個 0 改成 1 ;如果你想再把它改寫成 01111 ,即再次對左起第 4 位取反,你就從編號為 00010 的那 100 個 bit 中再選一個 0 ,並把它改成 1 ……但是,這種新的 WOM 編碼方案沒什麽實質性的意義,重復寫入次數成倍增加了的同時,所用的存儲空間也成倍增加了,單個 bit 的利用率仍然沒有提高。這裏面有個原因:頻繁用到某個編號,對應的數字 0 將會很快用光。為了解決這個問題,我們再出奇招:允許用戶根據需要給某個編號裏再“充”一些的 0 。把這些想法結合起來,我們就得到了一類更加“黑”的“表格式 WOM 編碼”。
我們列一個大表格,表格裏一共有 100 行,每一行都是 105 個 bit ,其中前 5 個 bit 表示編號,後 100 個 bit 則用於標記這個編號是否被選中,有奇數個數字 1 代表該編號要選,有偶數個數字 1 代表該編號不選。所有選中的編號裏,各個位置上究竟有奇數個 1 還是偶數個 1 ,就決定了這 10500 個 bit 的存儲空間究竟表達了哪 5 個 bit 的值。每次改寫本質上都是選中某個沒選中的編號,或者取消掉某個選中了的編號。如果這個編號所在的行裏還有空余的 0 ,我們只需要把其中一個 0 改成 1 即可;如果這個編號所在的行都滿了,或者整個表格裏根本還沒出現這個編號(比如初始時),我們就把新的一行的前 5 個 bit 設為這個編號,再把它後面的某個 0 改成 1 。註意到,所有可能的編號也就只有 00001, 00010, …, 11111 共 31 種,並且每種編號都是用滿一行才會再開一行。這說明,我們每次都能順利完成改寫操作,直到表格中沒填滿的行不足 31 行為止。在此之前,我們已經成功改寫了 (100 – 31) × 100 = 6900 次。總共 10500 個 bit 的存儲空間,竟能 6900 次寫入 5 個 bit 的數據,可見單個 bit 的利用率為 5 × 6900 / 10500 = 3.2857… 。
進一步增加行數和列數,可以進一步增加單個 bit 的利用率。如果整個表格一共有 r 行,每一行裏都有 5 + s 個 bit ,我們就能重復使用至少 (r – 31) · s 次,每次都能寫入 5 個 bit 的數據。因此,單個 bit 的利用率就是 5 · (r – 31) · s / (r · (5 + s)) 。當 r 和 s 足夠大時, (r – 31) / r 會非常接近 1 , s / (5 + s) 也會非常接近 1 ,因而整個分數就會非常接近 5 。類似地,如果把 5 換成更大的 k ,單個 bit 的利用率也就能跟著上升為 k ,這優於之前的那個 k / 4 。
但是,如此高的 bit 利用率,是由極其龐大的存儲空間以及極其龐大的重寫次數來支撐的,這很難有什麽實際用途。在生活中,我們可能更關心的是:為了寫入 t 次數據,每次數據量都是 k 個 bit ,至少需要幾個 bit 的空間?這個問題分析起來就非常困難了。不妨讓我們先從一些最簡單的情形出發,一點一點開始探究。為了重復 2 次寫入 2 個 bit 的數據,我們可以只用 3 個 bit 的空間(即本文最開始講到的 WOM 編碼);那麽,同樣是每次寫入 2 個 bit 的數據,為了把寫入次數從 2 次提升到 3 次,我們需要幾個 bit 的空間呢?我們先給出一個下界: 4 個 bit 的空間是不夠的。事實上,我們將會證明,當 t ≥ 3 時,要想重復 t 次寫入 2 個 bit 的數據,只用 t + 1 個 bit 的空間是辦不到的。
首次寫入的數據有 00 、 01 、 10 、 11 共四種可能,初始時的 01 串 000…00 最多只能表達其中一種可能,其他情況下我們都必須要往存儲器裏寫數字 1 。不妨假設首次寫入數據 a 和數據 b 時,我們必須要往存儲器裏寫數字 1 ,其中 a 和 b 是 {00, 01, 10, 11} 中的兩個不同的元素。在這段文字和下段文字中,我們假設,首次寫入的總是 a 和 b 之一。那麽,下一步改寫時寫入的有可能是什麽呢?首次寫入 a 後,接下來我們可以把它改寫成 b 、 c 、 d ;首次寫入 b 後,接下來我們可以把它改寫成 a 、 c 、 d 。這裏, c 、 d 是 {00, 01, 10, 11} 中的另外兩個不同的元素。這意味著,下一步改寫時寫什麽都有可能。容易看出,今後每次改寫時更是寫什麽的都有了。由於每次改寫都會把至少一個 0 改成 1 ,因此這就說明了,不管第 t – 1 次寫入的是 {00, 01, 10, 11} 中的哪個元素,存儲器裏都有至少 t – 1 個 1 。
為了給最後一次改寫留下足夠的空間,此時存儲器裏還得有至少兩個 0 。如果存儲器一共只有 t + 1 個 bit 的空間的話,你會發現這一切都抵得非常死:不管第 t – 1 次寫入的是什麽,存儲器裏都只能有恰好 t – 1 個 1 ,並且在最後一次改寫時,把其中一個 0 改成 1 ,把另外一個 0 改成 1 ,以及把剩下的兩個 0 都改成 1 ,必須正好對應三種可能的改寫值。這說明,如果第 t – 1 次寫入的是 a ,把剩下的兩個 0 都改成 1 就會得到一個與 a 不同的值;如果第 t – 1 次寫入的是 b ,把剩下的兩個 0 都改成 1 就會得到一個與 b 不同的值;對於 c 和 d 也是同理。因而,當存儲器裏寫滿了 1 時,它所表達的值既不能是 a ,也不能是 b ,也不能是 c 和 d 。這個矛盾就表明,存儲器裏只有 t + 1 個 bit 的空間的話是不夠的。
別忘了我們正在探究的問題:同樣是每次寫入 2 個 bit 的數據,為了把寫入次數從 2 次提升到 3 次,我們需要幾個 bit 的空間?現在我們知道了, 4 個 bit 的空間是不夠的。那麽, 5 個 bit 的空間夠不夠呢?答案是肯定的。我們可以把這 5 個 bit 分成兩部分,前面一部分有 2 個 bit ,後面一部分有 3 個 bit 。註意到,利用 2 個 bit 的空間可以寫入 1 次 2 個 bit 的數據,利用 3 個 bit 的空間可以寫入 2 次 2 個 bit 的數據,按照下面給出的方法把兩者結合起來,我們就能利用 5 個 bit 的空間寫入 1 + 2 = 3 次數據了。下面,我們將會說明,假設每次所寫的數據量都相同,如果重寫 t1 次可以用 r 個 bit 的空間辦到,重寫 t2 次可以用 s 個 bit 的空間辦到,那麽重寫 t1 + t2 次一定可以用 r + s 個 bit 的空間辦到。
這看起來似乎非常簡單:把 r 個 bit 和 s 個 bit 並排放置,先在前 r 個 bit 裏使用前一種子編碼系統,把 t1 次重寫用光了之後,再在後 s 個 bit 裏使用後一種子編碼系統,直到把 t2 次重寫用光。解碼時,我們就視情況只看前 r 個 bit 或者只看後 s 個 bit :如果後 s 個 bit 為空,則解碼結果完全以前 r 個 bit 為準;如果後 s 個 bit 裏有東西,則解碼結果完全以後 s 個 bit 為準。太簡單了,不是嗎?只可惜,這個辦法有個問題。如果在後一種子編碼系統中, 000…00 正好對應了某個值(正如本文最開始講到的 WOM 編碼一樣, 000 表示 00 ),那麽首次往後 s 個 bit 裏寫數據時就有可能讓後 s 個 bit 仍然為空,解碼也就出錯了。當然,我們可以額外用一個 bit ,專門用來表示剛才是在哪邊寫的數據。但是,這樣我們就用了 r + s + 1 個 bit 的空間了。
那怎麽辦呢?之前那些奇數個 1 偶數個 1 之類的思路,現在就又派上用場了。我們仍然像剛才那樣,前 t1 次都在前 r 個 bit 裏寫,後 t2 次都在後 s 個 bit 裏寫,但解碼的方法有所變化:假設前 r 個 bit 表示的值為 a ,假設後 s 個 bit 表示的值為 b ,那麽所有 r + s 個 bit 表示什麽值,就看 a 和 b 的各個位置上的數字 1 的總數的奇偶性。舉個例子吧:假如在前一個子編碼系統中, 1101 表示的值是 10 ;假設在後一個子編碼系統中, 001 表示的值是 11 ;由於 10 和 11 的左起第 1 位上一共有偶數個 1 ,左起第 2 位上一共有奇數個 1 ,因此在整個編碼系統中, 1101001 就表示 01 。在編碼時,不管是往哪邊寫東西,我們都只消寫入要表達的值和另一邊當前表達出的值在哪些位置上有差即可。
由於僅寫 1 次 2 個 bit 的數據只需要 2 個 bit 的空間,重復 2 次寫入 2 個 bit 的數據只需要 3 個 bit 的空間,因此重復 3 次寫入 2 個 bit 的數據就只需要 2 + 3 = 5 個 bit 的空間了。
我們還可以把這種“合成式編碼”繼續用於 t 值更大的情況。重復 4 次寫入 2 個 bit 的數據需要多少個 bit 的空間呢?我們可以把這 4 次拆成 1 次加上 3 次,也可以把這 4 次拆成 2 次加上 2 次,從而得到兩種不同的 WOM 編碼。前一種需要 2 + 5 = 7 個 bit 的空間,後一種需要 3 + 3 = 6 個 bit 的空間,因而後者更優。類似地,重復 5 次寫入 2 個 bit 的數據可以用 2 + 6 = 8 個 bit 的空間辦到,也可以用 3 + 5 = 8 個 bit 的空間辦到,兩者的效果相同。
我們來總結一下目前的發現。不妨用 f(t) 來表示,為了重復 t 次寫入 2 個 bit 的數據,目前已知的最優方案用了多少 bit 的空間。當 t = 1, 2, 3, 4, 5 時, f(t) 的值分別為:
| t | 1 | 2 | 3 | 4 | 5 |
| f(t) | 2 | 3 | 5 | 6 | 8 |
僅寫 1 次 2 個 bit 的數據,顯然 1 個 bit 的空間是不夠的,我們至少要用 2 個 bit 的空間。為了重復 2 次寫入 2 個 bit 的數據,顯然 2 個 bit 的空間是不夠的,我們至少要用 3 個 bit 的空間。回想我們之前證明過的結論:當 t ≥ 3 時,要想重復 t 次寫入 2 個 bit 的數據,只用 t + 1 個 bit 的空間是辦不到的,我們至少需要 t + 2 個 bit 的空間。不妨用 g(t) 來表示,為了重復 t 次寫入 2 個 bit 的數據,目前已知的理論最少所需空間是多少 bit 。當 t = 1, 2, 3, 4, 5 時, g(t) 的值分別為:
| t | 1 | 2 | 3 | 4 | 5 |
| g(t) | 2 | 3 | 5 | 6 | 7 |
容易看出,當 t = 1, 2, 3, 4 時,上界與下界是一致的,對應的最優化問題也就有了圓滿的回答。但是, t = 5 時的情形就不盡人意了:我們有了一種只使用 8 個 bit 的方案,但只證明了 7 個 bit 是必需的。那麽,究竟是我們給出的方案還不夠好,還是我們證明的結論還不夠強呢?
Ronald Rivest 和 Adi Shamir 給出了 t = 5 時的一種只需要 7 個 bit 的編碼方案,從而把 t = 5 時的情形也完美地解決了。
為了說明這種新的編碼是怎麽工作的,我們不妨先講一下它的解碼過程。我們把這 7 個 bit 看作一個 7 位 01 串,假設它是 abcdefg 。如果這個 01 串中,數字 1 的個數小於等於 4 ,則按照下述過程確定整個 01 串所表達的值。
- 初始值為 00 。
- 如果 ab 為 10 ,則左邊那一位取反。
- 如果 ab 為 11 ,並且 cd 或 ef 之一為 01 ,則左邊那一位取反。
- 如果 cd 為 10 ,則右邊那一位取反。
- 如果 cd 為 11 ,並且 ab 或 ef 之一為 01 ,則右邊那一位取反。
- 如果 ef 為 10 ,則左右兩位都取反。
- 如果 ef 為 11 ,並且 ab 或 cd 之一為 01 ,則左右兩位都取反。
如果數字 1 的個數大於 4 ,則按照下述過程確定整個 01 串所表達的值。
- 如果 a 、 c 、 e 、 g 中有偶數個 1 ,則左邊那一位為 0 。
- 如果 a 、 c 、 e 、 g 中有奇數個 1 ,則左邊那一位為 1 。
- 如果 b 、 d 、 f 、 g 中有偶數個 1 ,則右邊那一位為 0 。
- 如果 b 、 d 、 f 、 g 中有奇數個 1 ,則右邊那一位為 1 。
然後我們再來敘述一下,如何利用這個 7 位 01 串, 5 次得出任何我們想要表達的值。首先註意到,最開始 abcdefg = 0000000 所表達的值就是 00 。表達一個新的值,本質上就是對當前的值進行下述三種操作之一:左邊那一位取反,右邊那一位取反,左右兩位都取反。接下來我們就來說明,我們可以連續五次實現任何一種取反操作。
在數字 1 的個數小於等於 4 的時候, ab 、 cd 、 ef 各對應一種取反操作。剛開始, ab 、 cd 、 ef 都為 00 。如果把其中一個 00 變為 10 ,就相當於執行了對應的取反操作;如果再把這個 10 變成 11 ,則相當於第二次執行該取反操作(即消除第一次取反的效果);如果再把剩下的某個 00 變成 01 ,則相當於第三次執行該取反操作;如果再把這個 01 也變成 11 ,則相當於第四次執行該取反操作(即消除第三次取反的效果)。註意,取反的標記是 10 ,讓別人再次取反的標記是 01 ,我們很容易把兩者區分開來。另外, ab 、 cd 、 ef 當中一定是先出現 11 再出現 01 ,並且不會出現兩個 11 一個 01 的情況(否則數字 1 的個數就超過 4 個了)。這說明, 01 作為一種輔助性的標記,將會恰好只為一個 11 服務,因而使用時不會產生什麽連帶的影響。
所以,如果前面四次取反操作中,每種操作最多出現兩次,我們只需要相應地做某些 00 → 10 或者 00 → 10 → 11 的修改就行了。如果前面四次取反操作全是同一種操作,我們只需要對相應的 00 做 00 → 10 → 11 的修改,再選一個剩下的 00 做 00 → 01 → 11 的修改。如果前面四次取反操作中,有一種操作出現了三次,另一種操作出現了一次,我們就用 00 → 10 實現那次單獨的操作,用 00 → 10 → 11 實現前兩次的重復操作,最後一定還剩有一個 00 ,把它變為 01 便能實現第三次的重復操作了。舉例來說,假如前面四次取反操作分別是左位取反、兩位都取反、左位取反、左位取反,那麽我們就把 abcdefg 按照 0000000 → 1000000 → 1000100 → 1100100 → 1101100 的方式修改即可。
不管是哪種情況,前面四次取反操作都各只改變 abcdefg 中的一位。此時, abcdefg 裏一共將會有 4 個數字 1 , abcdef 中還有兩位是 0 ,而且 g 一定是 0 。在此基礎上,任意改動其中一位,都會讓 abcdefg 中數字 1 的個數增加到 5 個或 5 個以上,解碼方法就變了:解碼結果的左位為 0 ,當且僅當 a 、 c 、 e 、 g 中有偶數個 1 ;解碼結果的右位為 0 ,當且僅當 b 、 d 、 f 、 g 中有偶數個 1 。現在,我們需要再把某一個或某一些 0 改成 1 ,讓整個 7 位 01 串最後一次表達出任意一個我們想要的值。
假設 abcdef 當中,有一個 0 在 a 、 c 、 e 當中,有一個 0 在 b 、 d 、 f 中。無妨假設 a 和 b 都是 0 。那麽,不管現在 a 、 c 、 e 、 g 中數字 1 的個數是奇是偶,也不管現在 b 、 d 、 f 、 g 中數字 1 的個數是奇是偶,把 a 改成 1 就能改變前者的奇偶性,把 b 改成 1 就能改變後者的奇偶性,把 g 改成 1 就能同時改變兩者的奇偶性,把 a 、 b 、 g 都改成 1 則能保持兩者的奇偶性都不變。
假設 abcdef 當中,兩個 0 都在 b 、 d 、 f 當中。無妨假設 b 和 d 都是 0 。那麽,不管現在 a 、 c 、 e 、 g 中數字 1 的個數是奇是偶,也不管現在 b 、 d 、 f 、 g 中數字 1 的個數是奇是偶,把 b 和 g 都改成 1 就能改變前者的奇偶性,只把 b 改成 1 就能改變後者的奇偶性,把 g 改成 1 就能同時改變兩者的奇偶性,把 b 、 d 都改成 1 則能保持兩者的奇偶性都不變。當然,如果兩個 0 都在 a 、 c 、 e 當中,處理方法也是類似的(其實,兩個 0 都在 a 、 c 、 e 當中,這種情況根本不會出現)。
這套 WOM 編碼太完美了,對嗎?其實,剛才的編碼流程裏有一個巨大的漏洞,不知道你發現了沒有:萬一前面四次取反操作中,有一種操作出現了三次,另一種操作出現了一次,並且出現了一次的操作是最後才出現的,那該怎麽辦呢?舉例來說,假如前面四次取反操作分別是左位取反、左位取反、左位取反、兩位都取反,那麽我們應該怎麽做呢?我們可以先把 0000000 變為 1000000 ,再把 1000000 變為 1100000 。接下來,我們應該把某個 00 變為 01 。麻煩的地方來了:我們應該把哪個 00 變為 01 呢?當然,你應該把 cd 從 00 變為 01 ,從而為下一步的“兩位都取反”留下空間。但是,你事先怎麽知道,下一步是“兩位都取反”呢?在不知道這一點的情況下,你有可能不小心把 ef 改為 01 ,此時 7 位 01 串變成了 1100010 ;接下來,你會發現發現下一步是“兩位都取反”,需要把 ef 改為 10 ,然後就徹底傻眼了。這該怎麽辦呢?遇到這種情況時, a 、 c 、 e 當中一定有正好一個 1 , b 、 d 、 f 中一定有正好兩個 1 ,並且最後的 g 一定為 0 。我們可以按照下面的指示,把 abcdefg 中的其中兩個 0 改為 1 ,從而讓整個 7 位 01 串提前進入數字 1 的個數大於 4 的狀態,並表達出任何一個我們想要表達的值。
- 如果把 a 、 c 、 e 當中剩下的兩個 0 都改成 1 ,整個 7 位 01 串表達的值就是 10 。此時, b 、 d 、 f 當中還有一個 0 ,另外 g 也仍然是 0 ,利用它們就能再表達一個新的值了。不管你是想要左位取反,還是想要右位取反,還是想要兩位都取反,都可以通過把其中一個 0 改成 1 或者把兩個 0 都改成 1 來實現。
- 如果把 a 、 c 、 e 當中剩下的某一個 0 改成 1 ,再把 b 、 d 、 f 當中剩下的那個 0 改成 1 ,整個 7 位 01 串表達的值就是 01 。此時, a 、 c 、 e 當中還有一個 0 ,另外 g 也仍然是 0 ,利用它們就能再表達一個新的值了。不管你是想要左位取反,還是想要右位取反,還是想要兩位都取反,都可以通過把其中一個 0 改成 1 或者把兩個 0 都改成 1 來實現。
- 如果把 a 、 c 、 e 當中剩下的某一個 0 改成 1 ,再把 g 從 0 改成 1 ,整個 7 位 01 串表達的值就是 11 。此時, a 、 c 、 e 當中還有一個 0 , b 、 d 、 f 當中也還有一個 0 ,利用它們就能再表達一個新的值了。不管你是想要左位取反,還是想要右位取反,還是想要兩位都取反,都可以通過把其中一個 0 改成 1 或者把兩個 0 都改成 1 來實現。
- 如果把 b 、 d 、 f 當中剩下的那個 0 改成 1 ,再把 g 從 0 改成 1 ,整個 7 位 01 串表達的值就是 00 。此時, a 、 c 、 e 當中還有兩個 0 ,其他地方都沒有 0 了。這不足以讓我們表達出所有可能的新的值。這可怎麽辦呢?幸運的是,如果前面四次取反操作中,有一種操作出現了三次,另一種操作出現了一次,所得的值不可能是 00 。這意味著,我們根本就不會碰到要表達出 00 的情況,自然也就不會碰到剛才的難題了。
前面這些雜亂無章的內容,已經唰唰唰地用掉了一萬多字。如果你能一字一句地讀到這裏,那我真的很佩服你。剛才講過的東西太多了,我們有必要整理一下線索。
不妨用符號 k × t / n 來表示每次寫入的數據量為 k 個 bit ,總的寫入次數為 t ,存儲器空間為 n 個 bit 的 WOM 編碼(註意到,這個符號作為一個算術表達式,算出來正好等於該 WOM 編碼的單個 bit 利用率)。我們最開始給出了一種 2 × 2 / 3 的 WOM 編碼,緊接著把它擴展為了一類 k × (2k – 2 + 1) / (2k – 1) 的 WOM 編碼,其中 k 是任意大於等於 2 的正整數。隨後,我們進一步把它擴展為了一類 k × ((r – (2k – 1)) · s) / (r · (k + s)) 的 WOM 編碼。但我們旋即指出,這樣的擴展雖然會帶來更高的空間利用率,卻因為過於龐大而難以用於實際。
所以,我們轉而開始研究另一類更具實際意義,同時也更加困難的問題。不妨用 w(k, t) 來表示所有可行的 k × t / n 當中最小的 n 。那麽,當各種正整數 k 和各種正整數 t 組合在一起時, w(k, t) 的值各是多少呢?首先, 2 × 2 / 3 的可行性說明了 w(2, 2) ≤ 3 。緊接著,我們證明了,當 t ≥ 3 時, w(2, t) ≥ t + 2 。隨後,我們構造性地證明了 w(k, t1 + t2) ≤ w(k, t1) + w(k, t2) 。利用 w(2, 1) ≤ 2 以及 w(2, 2) ≤ 3 ,我們得出了 w(2, 3) ≤ 5, w(2, 4) ≤ 6, w(2, 5) ≤ 8 。另外,我們不加證明地給出了兩個顯然成立的結論: w(2, 1) ≥ 2 ,以及 w(2, 2) ≥ 3 。綜合所有這些信息,我們得到:
- w(2, 1) = 2
- w(2, 2) = 3
- w(2, 3) = 5
- w(2, 4) = 6
- w(2, 5) = 7 或 8
最後,我們給出了一種 2 × 5 / 7 的 WOM 編碼,從而證明了 w(2, 5) = 7 。
尋找 w(k, t) 的精確值果然不是一件易事。我們費了好大的勁兒,結果不但完全沒動 k > 2 的情況,就連 k = 2 的情況也只搞出了 5 個準確值。當然,所有的 w(1, t) 顯然都等於 t ,所有的 w(k, 1) 顯然都等於 k ,因為它們太平凡了,我們一直沒提。除此之外,我們能不能再搞出幾個新的準確值來呢?
由於 w(3, 1) = 3 ,這說明,要想寫入 1 次 3 個 bit 的數據,存儲器裏至少需要留有 3 個數字 0 。據此容易得出, w(3, 2) ≥ 5 。這是因為,如果存儲器裏只有 4 個 bit 的話,為了給第 2 次寫入數據留下足夠的空間,不管第 1 次寫入的是什麽,我們都最多只能使用 4 個 0 中的 1 個 0 。然而, C(4, 0) + C(4, 1) = 5 < 23 ,這說明,最多只用 4 個 0 中的 1 個 0 ,無法表達出 23種不同的值。因此, w(3, 2) 至少是 5 。
另一方面,只需要簡單地把 k1 × t / n1 和 k2 × t / n2 連接起來使用,我們便能得到 (k1 + k2) × t / (n1 + n2) 。這說明, w(k1 + k2, t) ≤ w(k1 , t) + w(k2, t) 。(註意,這和之前的 w(k, t1 + t2) ≤ w(k, t1) + w(k, t2) 是兩個不同的結論。)由於 w(1, 2) = 2 , w(2, 2) = 3 ,因而 w(3, 2) ≤ 5 。結合上一段的結論,我們就得到了, w(3, 2) = 5 。
類似地,由於 C(5, 0) + C(5, 1) = 6 < 24 ,這說明 w(4, 2) ≥ 6 ;另一方面, w(4, 2) = w(2 + 2, 2) ≤ w(2, 2) + w(2, 2) = 3 + 3 = 6 。因此, w(4, 2) = 6 。
我們還能繼續把 w(5, 2) 的準確值給搞出來嗎?試試看吧。由於 C(6, 0) + C(6, 1) = 7 < 25 ,這說明 w(5, 2) ≥ 7 。事實上,由於 C(7, 0) + C(7, 1) + C(7, 2) = 29 < 25 ,這說明 w(5, 2) ≥ 8 。另一方面, w(5, 2) = w(2 + 3, 2) ≤ w(2, 2) + w(3, 2) = 3 + 5 = 8 。因此, w(5, 2) = 8 。
這條路還能走多遠?讓我們繼續。由於 C(8, 0) + C(8, 1) + C(8, 2) = 37 < 26 ,這說明 w(6, 2) ≥ 9 。另一方面, w(6, 2) = w(2 + 4, 2) ≤ w(2, 2) + w(4, 2) = 3 + 6 = 9 。因此, w(6, 2) = 9 。
難不成我們能把所有的 w(k, 2) 的準確值都搞出來?由於 w(1, 2) + w(6, 2) = w(2, 2) + w(5, 2) = w(3, 2) + w(4, 2) = 11 ,因此我們只能得出 w(7, 2) ≤ 11 。要是 C(10, 0) + C(10, 1) + C(10, 2) + C(10, 3) < 27 ,我們就能說明 10 個 bit 的空間不夠, w(7, 2) 的準確值也就出來了。只可惜, C(10, 0) + C(10, 1) + C(10, 2) + C(10, 3) = 176 > 27 。剛才的那條路到這裏就被堵死了。
在《怎樣重復使用一次寫入型存儲器》中, Ronald Rivest 和 Adi Shamir 說道:“對於較小的 k 和 t ,我們能推導出 w(k, t) 的值,如下表所示。我們尚不知道表中空白處的準確值。”
| k ╲ t | 1 | 2 | 3 | 4 | 5 | 6 |
| 1 | 1 | 2 | 3 | 4 | 5 | 6 |
| 2 | 2 | 3 | 5 | 6 | 7 | |
| 3 | 3 | 5 | 7 | |||
| 4 | 4 | 6 | ||||
| 5 | 5 | 8 | ||||
| 6 | 6 | 9 | ||||
| 7 | 7 |
這個表中的每一項的來歷,都是我們剛才講過的。呃……等等……好像並不是這樣…… w(3, 3) 是怎麽來的?為什麽 w(3, 3) = 7 ?好像就只有這一項是怎麽來的我們還不太清楚。
我們首先證明 w(3, 3) ≥ 7 。由於 w(3, 2) = 5 ,這說明,要想寫入 2 次 3 個 bit 的數據,存儲器裏至少需要留有 5 個數字 0 。如果存儲器裏只有 6 個 bit 的話,為了給後 2 次寫入數據留下足夠的空間,不管第 1 次寫入的是什麽,我們都最多只能使用 6 個 0 中的 1 個 0 。然而, C(6, 0) + C(6, 1) = 7 < 23 ,這說明,最多只用 6 個 0 中的 1 個 0 ,無法表達出 23 種不同的值。因此, w(3, 3) 至少是 7 。
但是,不管使用 w(k1 + k2, t) 的構造法,還是 w(k, t1 + t2) 的構造法,我們都只能得出 w(3, 3) ≤ 8 。怎麽辦呢?別忘了,之前我們還講過很多其他 WOM 編碼,比如一類 k × (2k – 2 + 1) / (2k – 1) 的 WOM 編碼。當 k = 3 時,它就成為了一種 3 × 3 / 7 的 WOM 編碼。因此,我們有 w(3, 3) ≤ 7 。結合上一段的結論,我們就得到了, w(3, 3) = 7 。 Ronald Rivest 和 Adi Shamir 列出的表格裏的所有項,至此就全部解說完畢了。
顯然,對 w(k, t) 的探討遠未就此結束,我們還留下了很多的未解之謎。不僅如此, w(k, t) 這個記號本身也還可以推廣,比如 k 甚至不一定是整數。在實際應用中,每次寫入的數據量並不總是滿滿的 k 個 bit 。假如我們想要用打孔卡片或者打孔紙帶記錄英文句子,那麽每次寫入的就是 26 個英文字母中的一個,數據量也就是 log226 了。容易證明,為了重復使用 2 次紙帶,每次寫入的都是 26 個字母之一,只用 6 個 bit 的空間是不夠的。 Ronald Rivest 和 Adi Shamir 則給出了一種只用 7 個 bit 的方案。為了方便地表示出編碼方案,他們把這 26 字母排成了下面這個表格:
| A | H | G | G | F | Y | L | w | E | Z | Y | r | X | f | p | n | D | W | V | z | U | d | j | o | T | w | k | e | l | t | d | u |
| C | S | R | c | Q | i | o | z | P | p | i | h | u | e | x | y | O | z | s | j | s | n | i | w | v | c | q | g | f | k | b | m |
| B | N | M | z | L | b | g | m | K | u | t | b | n | g | f | w | J | w | r | h | k | v | x | y | m | j | p | s | o | q | c | i |
| I | k | m | q | l | c | k | u | w | t | e | o | s | d | j | v | u | d | b | f | g | e | t | p | y | x | n | l | h | r | z | a |
這個表格一共有 4 行,每行的編號分別是 00, 01, 10, 11 ;這個表格一共有 32 列,每列的編號分別是 00000, 00001, 00010, …, 11110, 11111 。每個位置上的字母是什麽,則對應的行號與列號相連後,所得的 7 位 01 串就對應哪個字母。其中,大寫字母表示第 1 次寫入,小寫字母表示第 2 次寫入。例如, 0011000 表示的就是字母 T ,把它的左起第 1 位、第 2 位、第 5 位改為 1 之後,就能得到 1111100 ,表示的是字母 h 。
WOM 編碼是一個很有趣的課題。最後,我們再介紹兩種有趣的 WOM 編碼,來結束這篇兩萬字的長文吧。
David Leavitt 給出了一種 log25 × 3 / 5 的 WOM 編碼,它可以重復 3 次使用 5 個 bit 的空間,每次寫入的都是 5 個符號中的任意一個,其單個 bit 利用率約為 1.393 。不妨把這 5 個符號分別記作 a 、 b 、 c 、 d 、 e 。第 1 次寫入時,用 10000 來表示符號 a ;第 2 次寫入時,用 01001 和 00110 之一來表示符號 a ;第 3 次寫入時,用 01111 、 10110 、 11001 之一來表示符號 a 。其他符號所對應的編碼,則是由符號 a 的編碼分別向右循環移動 1 位、 2 位、 3 位、 4 位所得。例如, 00110 表示 a ,那麽 00011 就表示 b , 10001 就表示 c , 11000 就表示 d , 01100 就表示 e 。對於符號 a 的另外 5 種編碼,則也是用這種方法變成其他各個符號的編碼。由於 01 串的長度 5 是一個質數,因此循環移動後得到的編碼不會發生重復。
| 第 1 次寫入 | 第 2 次寫入 | 第 3 次寫入 | ||||
| a 的編碼 | 10000 | 01001 | 00110 | 01111 | 10110 | 11001 |
| b 的編碼 | 01000 | 10100 | 00011 | 10111 | 01011 | 11100 |
| c 的編碼 | 00100 | 01010 | 10001 | 11011 | 10101 | 01110 |
| d 的編碼 | 00010 | 00101 | 11000 | 11101 | 11010 | 00111 |
| e 的編碼 | 00001 | 10010 | 01100 | 11110 | 01101 | 10011 |
可以驗證,如果第 1 次寫入的是 a ,第 2 次想把它改寫成 b 、 c 、 d 、 e 都是有辦法的;如果第 2 次寫入的是 a (不管是哪種形式),第 3 次想把它改寫成 b 、 c 、 d 、 e 都是有辦法的。再考慮到所有的編碼都是循環移動生成的,因此符號 a 能被順利改寫,所有符號都能被順利改寫了。
Frans Merkx 給出了一種 log27 × 4 / 7 的 WOM 編碼,它可以重復 4 次使用 7 個 bit 的空間,每次寫入的都是 7 個符號中的任意一個,其單個 bit 利用率約為 1.604 。不妨把這 7 個符號分別記作 a 、 b 、 c 、 d 、 e 、 f 、 g 。 Frans Merkx 把它們寫成了 7 組,每組三個符號:
| (a, b, d) | (a, c, g) | (a, e, f) | (b, c, e) | (b, f, g) | (c, d, f) | (d, e, g) |
可以驗證,每個符號都正好出現在了三個不同的組裏,並且對於任意兩個符號,都有且僅有一個組同時包含它們。接下來,我們將給大家演示,通過選中越來越多的符號,如何一次又一次地表示新的符號。
- 初始時,所有的符號都沒有被選中,因此我們要表示誰就選中誰。
- 如果我們想表示一個新的符號,我們就選中唯一那個和已選中的符號以及這個新的符號共組的符號。如果我們把上一步已選中的符號記作 x ,把這一步想要表示的新符號記作 u ,那麽我們這一步就選中那個唯一和 x 、 u 同組的符號 y 。
- 如果我們想再表示一個新的符號,又該怎麽辦呢?如果這個新的符號是 x ,那麽我們就選中任意一個包含 y 但不包含 x 的組裏的所有符號;如果這個新的符號是 y ,那麽我們就選中任意一個包含 x 但不包含 y 的組裏的所有符號;如果這個新符號是除了 x 、 y 的其他符號,那麽我們就把這個新符號選中,同時選中唯一那個和 x 、 y 共組的符號(即上一步表示的符號)。不管怎麽樣,我們都選中了四個符號,其中三個符號形成一組,單獨出來的符號就是我們要表示的符號。
- 如果我們想再表示一個新的符號,又該怎麽辦呢?假設上一步選中的符號是 p 、 q 、 r 、 s ,其中 p 、 q 、 r 是一組, s 是上一步表示的符號。如果我們要表示 p ,就把唯一那個和 p 、 s 同組的符號選中;如果我們要表示 q ,就把唯一那個和 q 、 s 同組的符號選中;如果我們要表示 r ,就把唯一那個和 r 、 s 同組的符號選中;如果我們要表示其他的符號,那這個符號一定沒被選中,我們只需把別的符號都選中,只留下這個符號不選即可。
這 7 個符號當中,我們究竟選了哪些符號,這可以用 7 個 bit 來表示。例如, 0100100 就表示我們選中了 b 、 e 這兩個符號,別的符號都沒選。利用上面給出的方法,我們可以重復四次利用這 7 個 bit ,每次都可以表示 a 、 b 、 c 、 d 、 e 、 f 、 g 這 7 個符號當中任意一個與上次所表示的符號不同的符號。解碼時,我們只需要看看這 7 個 bit 裏有多少個數字 1 。
- 如果只有 1 個數字 1 ,它表示的就是這個數字 1 所對應的符號。
- 如果有 2 個數字 1 ,它表示的就是唯一與這兩個數字 1 所對應的兩個符號同組的符號。
- 如果有 4 個數字 1 ,對應的四個符號中一定有三個同組,剩下的那個符號就是它所表示的符號。
- 如果有 5 個數字 1 ,對應的五個符號一定形成了兩個組,同在這兩個組裏的符號就是它所表示的符號。
- 如果有 6 個數字 1 ,它表示的就是唯一那個數字 0 所對應的符號。
有一種幾何方法可以直觀地表示出這 7 個符號之間的關系。這裏,每個符號都用一個點表示,同一組符號所對應的點則都在一條線上(中間那個圓也是一條過三點的線)。
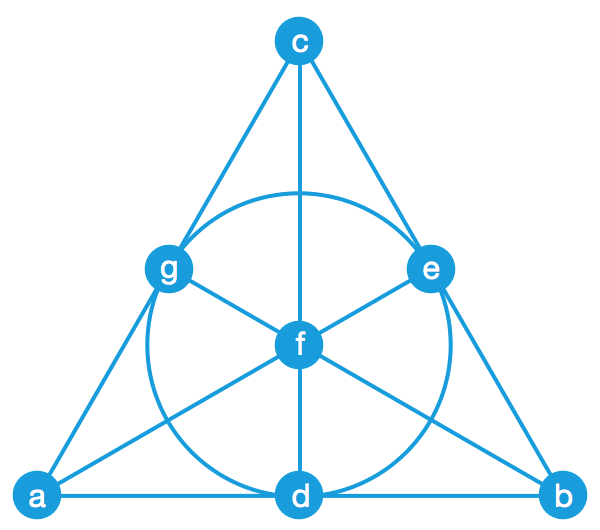
可以驗證,每條線上都有三個點,每個點都引出了三條線,並且任意兩點之間都有且只有一條線。由於這個結構是射影幾何裏的經典結構,因此 Frans Merkx 的 WOM 編碼也可以看作是射影幾何的妙用。
轉:WOM 編碼與一次寫入型存儲器的重復使用