
scrapy的allowed_domains設置含義
阿新 • • 發佈:2017-12-11
sta img 圖片 spa fff class .com start tps
設置allowed_domains的含義是過濾爬取的域名,在插件OffsiteMiddleware啟用的情況下(默認是啟用的),不在此允許範圍內的域名就會被過濾,而不會進行爬取
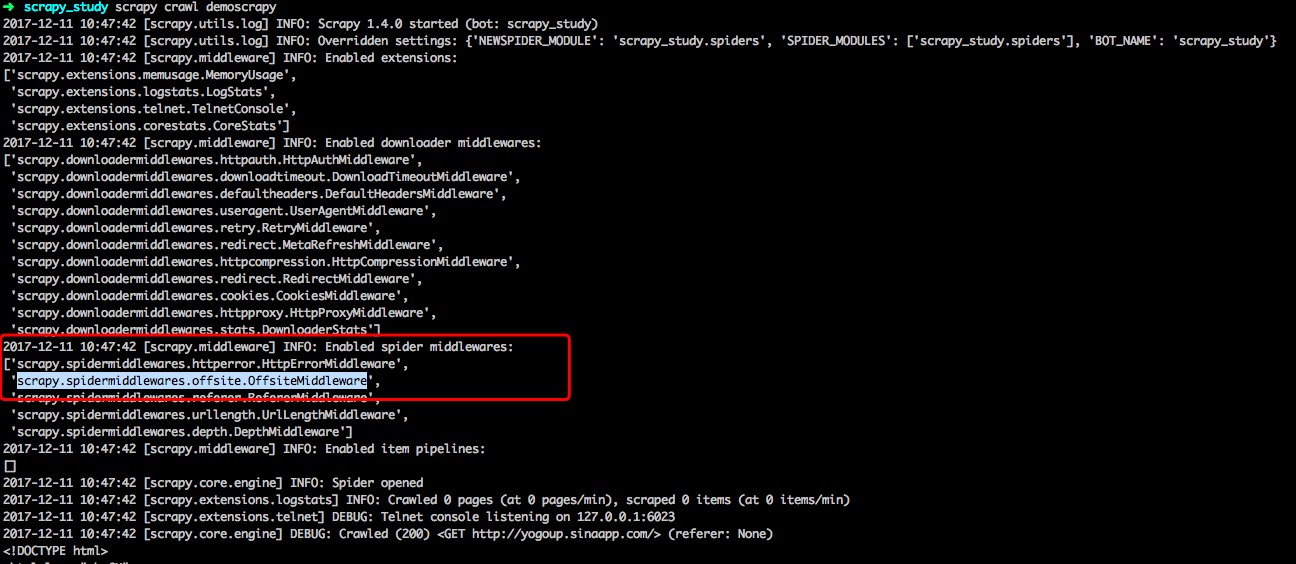
但是有一個問題:像下面這種情況,對於start_urls裏的起始爬取頁面,它是不會過濾的,它的作用是過濾首頁之後的頁面-----待驗證
#/usr/bin/env python #coding:utf-8 import scrapy # import sys # import os from scrapy_study.items import DemoItem class DemoScrapy(scrapy.Spider): name= ‘demoscrapy‘ # start_urls = [‘http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/tutorial.html‘] allowed_domains = ["scrapypython.2org"] # start_urls = [‘https://docs.python.org/2/library/os.path.html‘] start_urls = [‘http://yogoup.sinaapp.com/‘] def parse(self,response): print response.body
scrapy的allowed_domains設置含義