
Spark快速大數據分析 01
阿新 • • 發佈:2017-12-11
計算機 clu nag manage 來看 分析 parquet 定義 分享
==Spark的發展介紹==
==一個大一統的軟件棧==
Spark核心
計算引擎 對由很多計算任務組成的、運行在多個工作機器或者是一個計算集群上的應用調度、分發以及監控的計算引擎 速度快、通用 Spark項目包含多個密切組成的組件 優點1:軟件棧中所有的程序庫和高級組件都可以從下層的改進中獲益 優點2:運行整個軟件棧的代價變小了 優點3:能夠構建出無縫整合不同處理模型的應用 Spark的各個組件  Spark Core 實現了Spark的基本功能 包含:任務調度、內存管理、錯誤恢復、與存儲系統交互等模塊 包含:對彈性分布式數據集RDD的API定義 RDD表示 分布在多個計算機節點上可以並行操作的元素集合 是Spark的主要編程對象 SparkCore提供了創建和操作這些集合的多個API SparkSQL 用來操作結構化數據的程序包 通過它我們可以使用 SQL or Apache Hive版本的SQL方言(HQL)查詢數據 支持多種數據源 比如:Hive表、Parquet、JSON等 為Spark提供了一個SQL接口 實在Spark1.0中被引用的 Spark Streaming Spark提供的對實時數據進行流式計算的組件 提供了用來操作數據流的API 與SparkCore中的RDD API高度對應 底層設計來看:它支持與Spark Core同級別的容錯性、吞吐量以及可伸縮性 MLlib 機器學習ML功能的程序庫 提供了很多種機器學習算法 分類 回歸 聚類 協同過濾等 GraphX 用來操作圖的程序庫 可以進行並行的圖計算 擴展了Spark的RDD API 用來創建一個頂點和邊都包含任意屬性的有向圖 集群管理器 支持在各種集群管理器(cluster manager)上運行 包括:Hadoop YARN、Apache Mesos、以及Spark自帶的獨立調器
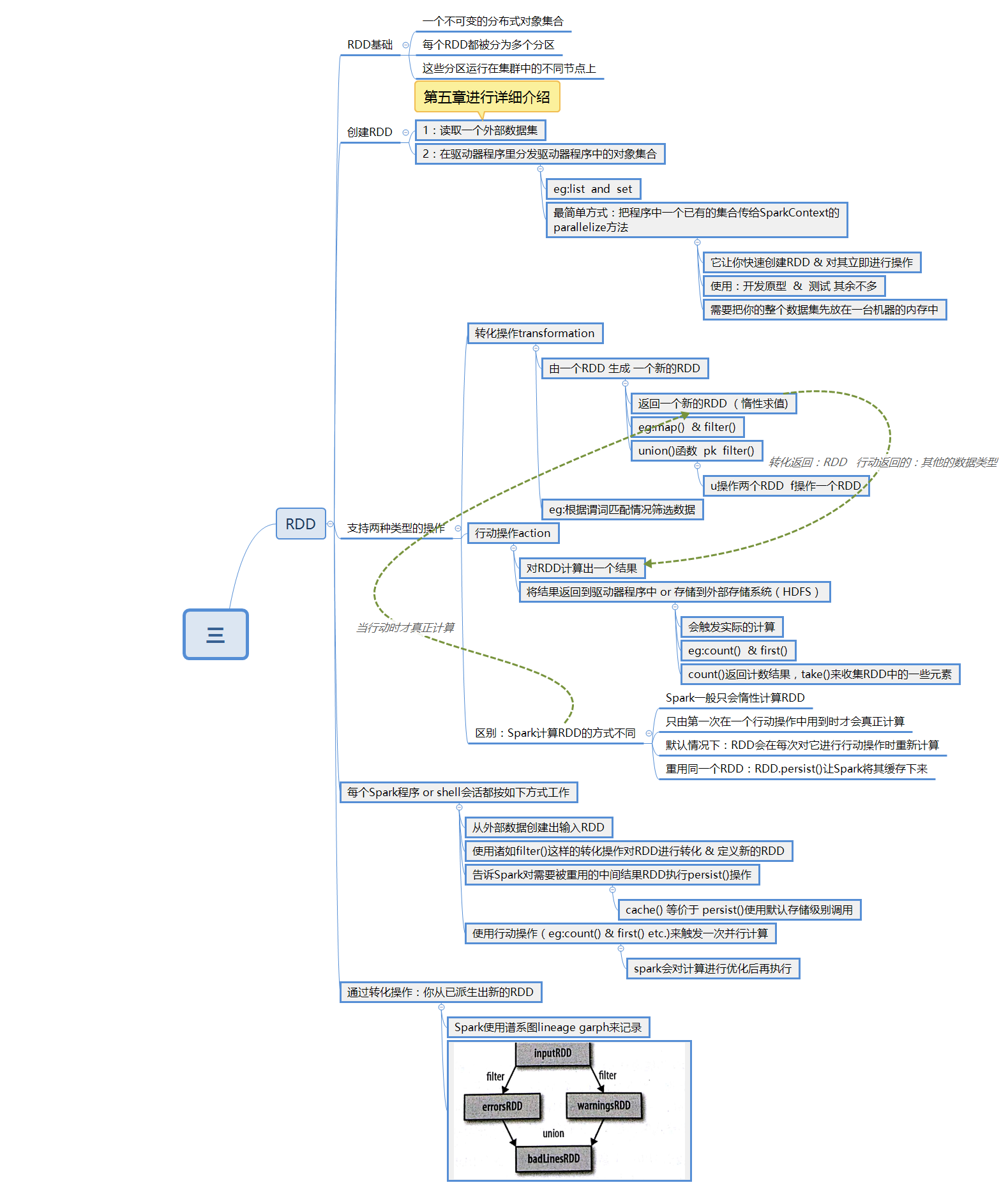
行動操作

RDD
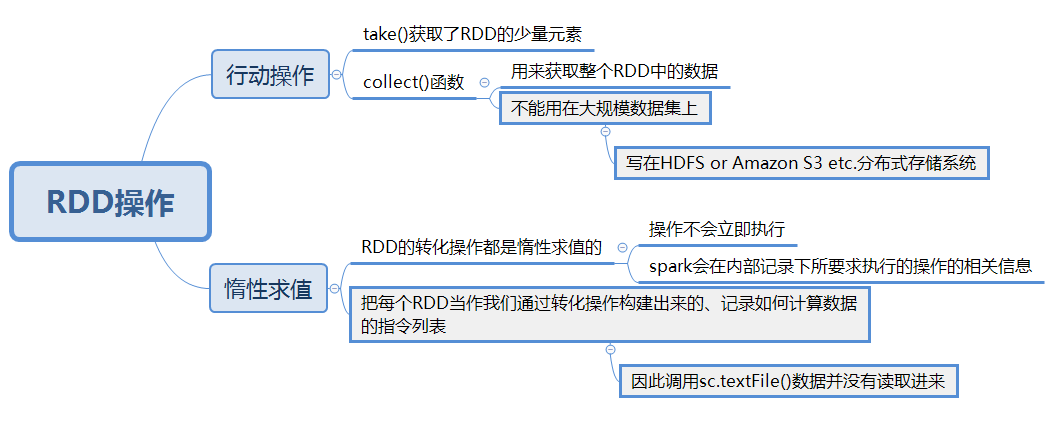
Spark傳遞函數

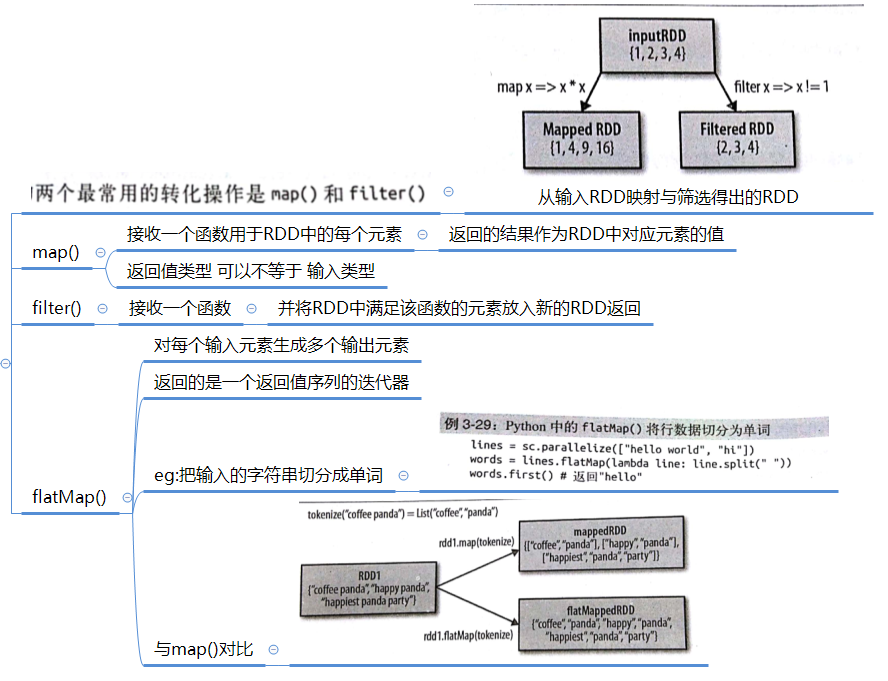
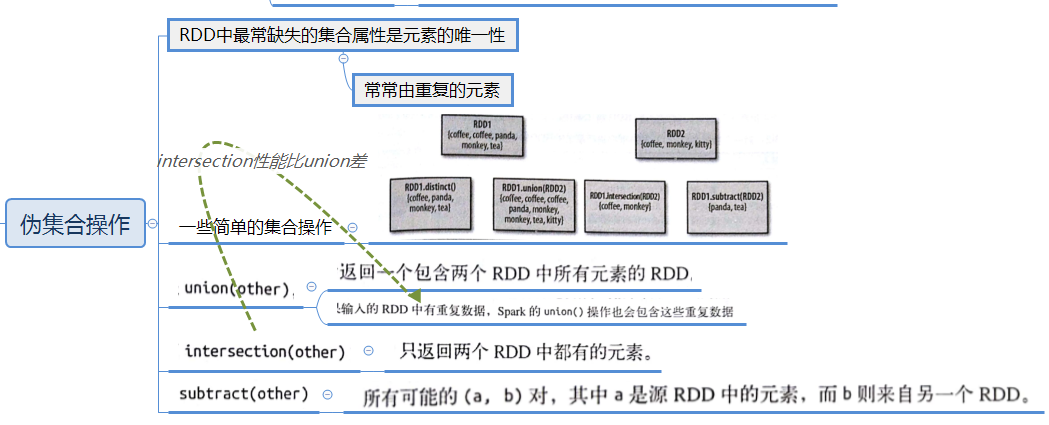
常見的轉化操作

Spark快速大數據分析 01