
簡單團隊-爬取豆瓣電影T250-項目進度
本次主要講解一下我們的頁面設計及展示最終效果:
頁面設計主要用到的軟件是:html,css,js,
主要用的編譯器是:sublime,dreamweaver,eclipse,由於每個人使用習慣不一樣,所以有的人用的就簡單點。
我們都統一使用的是谷歌瀏覽器瀏覽完成後的網頁。
1.html代碼部分:
2.css代碼部分:
3.js代碼部分:
代碼過多在這就不展示了
4.整個代碼包的展示
由於我們大部分是套用的其他好的網站的代碼模式,所以比較容易。
還花錢購買了一個月的服務器,會看到效果。
頁面高端,鼠標劃過隨即有動畫跟隨,這個效果是一大亮點所在:
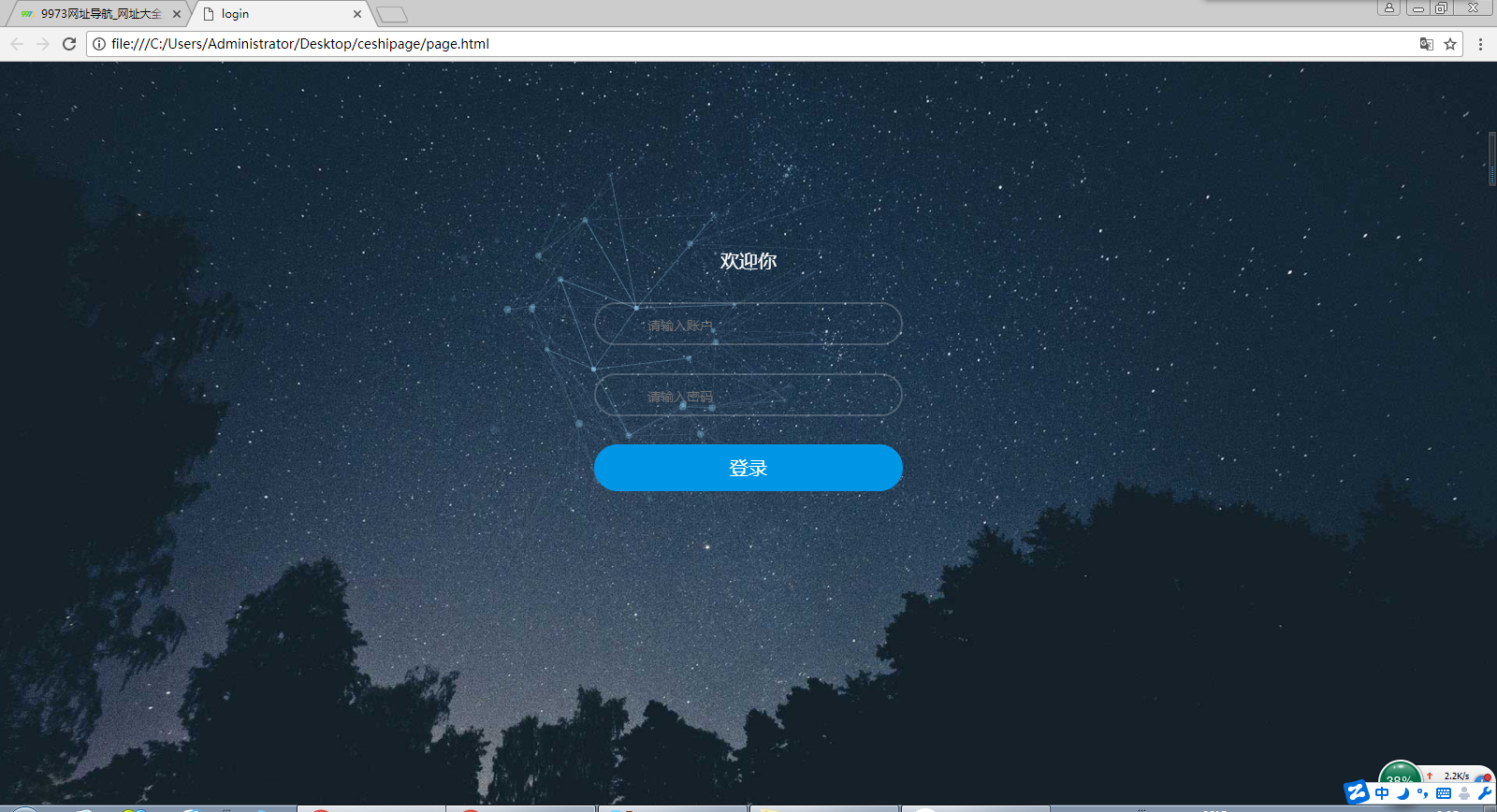
最後附上了我們團隊的名字:
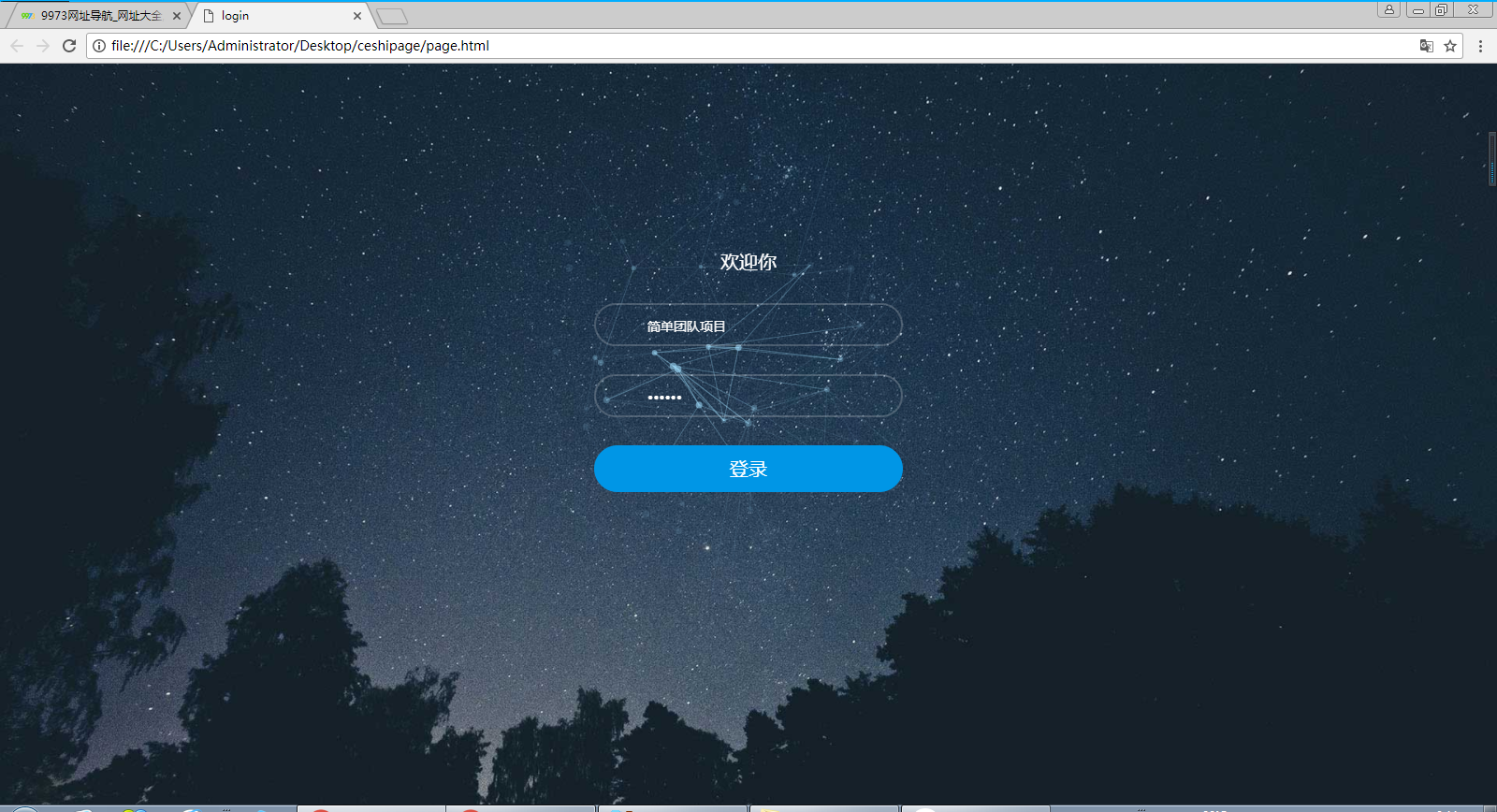
以上就是我們的登錄頁面完成效果,開始登錄頁是一個網頁的臉面,所以我們選用了深沈並且賦有神秘色彩的深色星空。
核心功能也正在慢慢完善中,今天主要是介紹登錄頁面的情況。
簡單團隊-爬取豆瓣電影T250-項目進度
相關推薦
簡單團隊-爬取豆瓣電影T250-項目進度
部分 色彩 核心 body pan log png 服務器 功能 本次主要講解一下我們的頁面設計及展示最終效果: 頁面設計主要用到的軟件是:html,css,js, 主要用的編譯器是:sublime,dreamweaver,eclipse,由於每個人使用習慣不一樣,所以有的
簡單團隊-爬取豆瓣電影top250-設計文檔
分享圖片 top 文檔 功能需求 class cnblogs 項目介紹 面向 設計文檔 項目介紹: 功能需求: 面向用戶: 未來規劃: 以上內容源自於在課上做的ppt內容,絕對本組ppt,並且真實有效。 簡單團隊-爬取豆瓣電影top
團隊-爬取豆瓣電影TOP250-簡單團隊一階段互評
思維 lec sel 敏捷 努力 查找 pan sele 參與 團隊名稱:簡單 學號:2015035107009 得分:10 原因:配合默契,負責女生部分 學號:2015035107224 得分:9 原因:思維敏捷,領導了大體思路 學號:2015035107005 得分:6
團隊-爬取豆瓣電影TOP250-需求分析
影評 鏈接 lock 分析 strong str 需求分析 豆瓣 信息 團隊-爬取豆瓣電影TOP250-需求分析 需求:爬取豆瓣電影TOP250 *向用戶展示電影的排名,分數,名字,簡介,導演,演員,前10條影評信息,鏈接信息 實現思路: 分析豆瓣電影TOP250
《團隊-爬取豆瓣電影TOP250-需求分析》
round ack 地址 align wid ica san pad ext 需求: 1.搜集相關電影網址 2.實現相關邏輯的代碼 項目步驟: 1.通過豆瓣網搜索關鍵字,獲取相關地址 2.根據第三方包實現相關邏輯《團隊-爬取豆瓣電影TOP250-需求分析》
團隊-爬取豆瓣電影TOP250-開發環境搭建過程
技術 團隊 img mage www. 9.png 官網下載 har image 從官網下載安裝包(http://www.python.org)。 安裝Python 選擇安裝路徑(我選的默認) 安裝Pycharm 1.從官網下載安裝包(ht
《團隊-爬取豆瓣電影TOP250-設計文檔》
python top 賬號 集成開發環境 python3 搭建環境 電影 settings 解耦 搭建環境: 1.安裝python3.4 2.安裝pycharm集成開發環境 3.安裝Git for Windows 4.安裝python第三方包 bs4開發階段: 1
團隊-爬取豆瓣電影-設計文檔
常用 不一致 spider 其他 所有 功能 sch pytho awl 團隊成員: 張曉亮,邵文強,寧培強,潘新宇,邵翰慶,李國峰,張立新 概要設計思路(https://github.com/Wooden-Robot/scrapy-tutorial): 聲明
團隊-爬取豆瓣電影top250-模塊開發過程
rds tps tde 轉換 /usr sub bigger pen 其他 項目托管平臺地址:https://gitee.com/nothingbigger/DouBantop250 開發模塊功能: 完善爬取功能、補全獲取數據的漏洞,開發時間:1天 #!/usr
團隊-爬取豆瓣電影-最終程序
class 示例 ast tree 成員 spa mas lec .com 托管平臺地址:https://gitee.com/w789369/PaChong/tree/master 小組名稱:簡單 小組成員合照:無 程序運行方法:python 程序運行示例及運行結果:
團隊-張文然-需求分析-python爬蟲分類爬取豆瓣電影信息
工具 新的 翻頁 需求 使用 html 頁面 應該 一個 首先要明白爬網頁實際上就是:找到包含我們需要的信息的網址(URL)列表通過 HTTP 協議把頁面下載回來從頁面的 HTML 中解析出需要的信息找到更多這個的 URL,回到 2 繼續其次還要明白:一個好的列表應該:包含
《團隊-爬取豆瓣Top250電影-團隊-階段互評》
溝通 爬取 top 負責 負責任 完成 好的 電影 責任 學號:2015035107080得分:9.8原因:認真完成任務,與組員相互溝通交流,相互協作。 學號:2015035107152得分:9.6原因:為人誠實謙虛,能吃苦耐勞,敏而好學,積極尋找答案。 學號:201503
團隊-爬取豆瓣Top250電影-團隊-階段互評
尋找 爬取 編程 階段 豆瓣 top 積極 領導 耐心 學號:2015035107001得分:8.5 原因:有耐心,較為認真 學號:2015035107004得分:9.6 原因:結對編程夥伴,負責 學號:2015035107080得分:10 原因:領導性較強 ,認真負責,樂
Python開發簡單爬蟲之靜態網頁抓取篇:爬取“豆瓣電影 Top 250”電影數據
模塊 歲月 python開發 IE 女人 bubuko status 公司 使用 目標:爬取豆瓣電影TOP250的所有電影名稱,網址為:https://movie.douban.com/top250 1)確定目標網站的請求頭: 打開目標網站,在網頁空白處點擊鼠標右鍵,
爬取豆瓣電影短評並使用詞雲簡單分析top50
先使用程序池爬取豆瓣電影短評 import requests import re import random import time import pandas as pd from pymongo import MongoClient from multiprocessing import
初學python:用簡單的爬蟲爬取豆瓣電影TOP250的排名
一開始接觸到python語言,對它沒什麼瞭解。唯一知道的就是它可以用來寫爬蟲,去爬取網路上的資源。爬蟲是一種按照一定的規則,自動地抓取網路上的資訊的程式或者指令碼。所以當我對python有一定的瞭解後,我就想個寫個爬蟲來試試手。於是就有了這篇文章,用簡單的爬蟲爬取豆瓣電影TO
爬取豆瓣電影排行(T250)的資訊
1.分析 針對所爬去的Url進行分析: 分析網址'?'符號後的引數,第一個引數'start=0',這個代表頁數,‘=0’時代表第一頁,‘=25’代表第二頁,以此類推。 1.1頁面分析 明確要爬取的元素 :排名、名字、導演、評語、評分 1.2 頁面程式碼分析
scrapy爬取豆瓣電影top250
imp port 爬取 all lba item text request top 1 # -*- coding: utf-8 -*- 2 # scrapy爬取豆瓣電影top250 3 4 import scrapy 5 from douban.items i
爬取豆瓣電影儲存到數據庫MONGDB中以及反反爬蟲
ica p s latest tel mpat side nload self. pro 1.代碼如下: doubanmoive.py # -*- coding: utf-8 -*- import scrapy from douban.items import Douba
關於html的多行匹配,正則re.S的使用(爬取豆瓣電影短評)
htm detail 3.1 port encoding 關於 color tel frame 參考鏈接:http://www.python(tab).com/html/2017/pythonhexinbiancheng_0904/1170.html(去除括號)